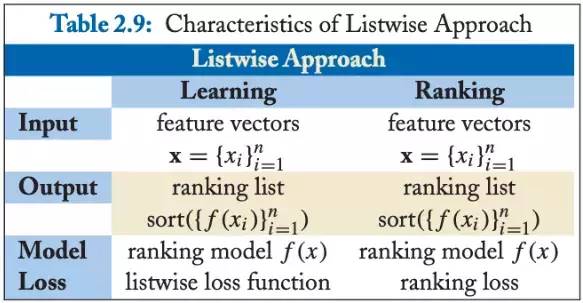
推荐系统中排序学习的三种设计思路
排序学习(Learning to Rank,LTR),也称机器排序学习(Machine-learned Ranking,MLR) ,就是使用机器学习的技术解决排序问题。自从机器学习的思想逐步渗透到信息检索等领域之后,如何利用机器学习来提升信息检索的性能水平变成了近些年来非常热门的研究话题,因此产生了各类基于机器学习的排序算法,也带来了搜索引擎技术的成熟和发展,如今,Learning to Rank 已经成为搜索、推荐和广告领域非常重要的技术手段。本文我们主要介绍排序学习的三种主要类别Point-wise、Pair-wise、List-wise和应用场景。
1.为什么需要排序学习
传统的排序方法可粗略分为基于相似度和基于重要性进行排序两大类,早期基于相关度的模型,通常利用 query 和 doc 之间的词共现特性(如布尔模型)、VSM(如 TF-IDF、LSI)、概率排序思想(如 BM25、LMIR)等方式。基于重要性的模型,利用的是 doc 本身的重要性,如 PageRank、TrustRank 等。
传统的检索模型所考虑的因素并不多,主要是利用词频、逆文档频率和文档长度、文档重要度这几个因子来人工拟合排序公式,且其中大多数模型都包含参数,也就需要通过不断的实验确定最佳的参数组合,以此来形成相关性打分。这种方式非常简单高效,但是也同时存在很多问题:
-
很难融合多种信息 -
手动调参工作量太大,如果模型参数很多,手动调参的可用性非常低 -
可能会过拟合
LTR 则是基于特征,通过机器学习算法训练来学习到最佳的拟合公式,相比传统的排序方法,优势有很多:
-
可以根据反馈自动学习并调整参数 -
可以融合多方面的排序影响因素 -
避免过拟合(通过正则项) -
实现个性化需求(推荐) -
多种召回策略的融合排序推荐(推荐) -
多目标学习(推荐)
排序学习在推荐领域中有着举足轻重的作用,推荐的整个流程可以分为召回、排序、重排序这三个阶段,通俗来说,召回就是找到用户可能喜欢的几百条资讯,排序就是对这几百条资讯利用机器学习的方法预估用户对每条资讯的偏好程度,一般以点击率衡量,也就是点击率预估问题。不难看出,排序学习在推荐领域主要用于排序阶段,最常用的是 Pointwise 排序方法;重排序更多是考虑业务逻辑的规则过滤,如在推荐结果的多样性、时效性、新颖性等方面进行控制。
在没有 Learning to Rank 之前,基于内容的推荐算法和基于邻域的协同过滤虽然也能预测用户的偏好,可以帮助用户召回大量的物品,但是我们必须知道,推荐系统中更重要的目标是排序,因为真正最后推荐给用户的只有少数物品,我们更关心这些召回物品中哪些才是用户心中更加喜欢的,也就是排序更靠前,这便是 Top-N 推荐。例如使用用户最近点击的资讯信息召回这些 item 的相关结果与用户偏好类别的热门结果组合后进行返回。但是这对于资讯类推荐需要考虑以下问题:资讯类信息流属于用户消费型场景,item 时效性要求高,item base cf 容易召回较旧的内容,而且容易导致推荐结果收敛。因此可以将 item 的相关结果保证时效性的基础上,融合类别、标签热门结果,对各个策略的召回结果按照线上总体反馈进行排序,就可以作为用户的推荐结果。但是这一融合过程比较复杂,一种简单的方式就是看哪种召回策略总体收益越高就扩大这个策略的曝光占比,对于个体而言却显得不是特别个性化,而且在规则调参上也比较困难,而 Leaning to Rank 则可以根据用户的反馈对多路召回的 item 进行排序推荐。
2.排序学习架构
排序学习是一个典型的有监督机器学习过程,我们分别来看一下排序学习在搜索以及推荐领域中的结构和作用。
在信息检索中,对每一个给定的查询-文档对,抽取特征,通过日志挖掘或者人工标注的方法获得真实数据标注。然后通过排序模型,使得输入能够和实际的数据相似。
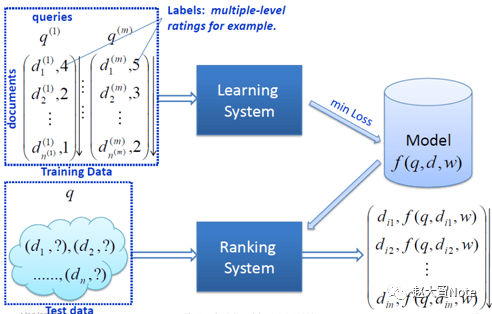
排序学习在现代推荐架构中处于非常关键的环节,它可以完成不同召回策略的统一排序,也可将离线、近线、在线的推荐结果根据根据用户所处的场景进行整合和实时调整,完成打分重排并推荐给用户。
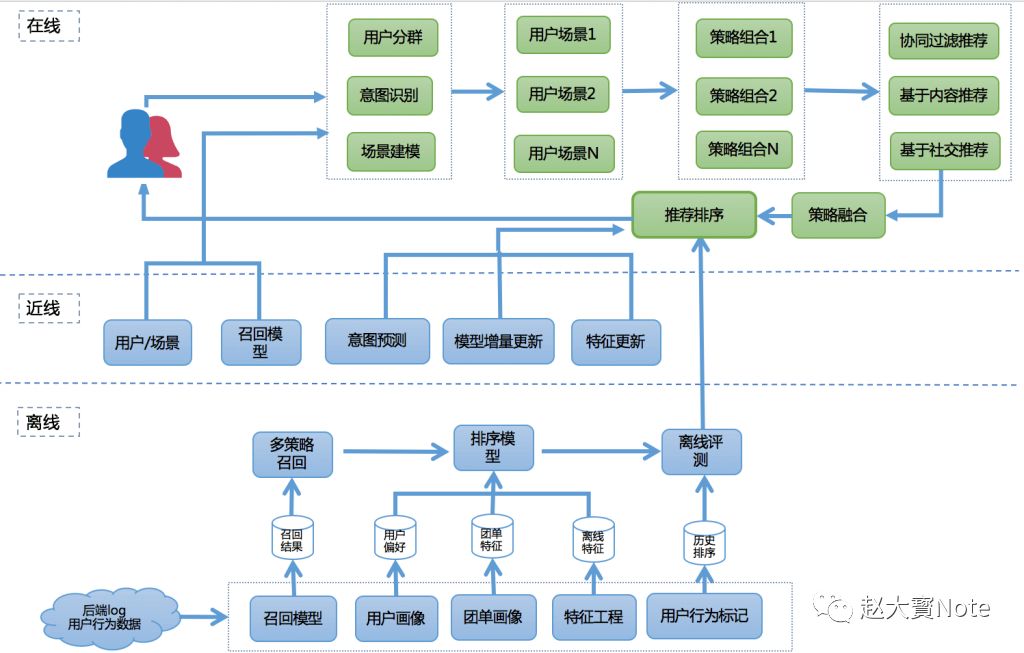
无论是搜索还是推荐,排序学习模型的特征提取以及训练数据的获取是非常重要的两个过程,与常见的机器学习任务相比,也有很多特殊的地方,下面我们简单介绍这两个过程中可能需要考虑的问题。
2.1.特征提取
在排序学习模型中,文档都是转化成特征向量来表征的,这便涉及一系列文本特征提取的工作,我们这里简单介绍一些可能用到的特征提取方法以及常用的特征类型。
文档的特征通常可以从传统排序模型获得一些相关特征或者相关度打分值,所以可分为两种类型:
一是文档本身的特征,比如 Pagerank 值、内容丰富度、spam 值、number of slash、url length、inlink number、outlink number、siterank,用户停留时间、CTR、二跳率等。
二是 Query-Doc 的特征:文档对应查询的相关度、每个域的 tf、idf 值,bool model,vsm,bm25,language model 相关度等。
也可以对文档分域,如对于一个网页文本,特征所在的文档区域可以包括 body 域,anchor 域,title 域,url 域,whole document 域等。
通过各个域和各种特征,我们可以组合出很多特征,当然有些特征是正相关有些是负相关,这需要我们通过学习过程去选取优化。
2.2.训练数据的获取
特征可以通过各种方式进行提取,但是 Label 的获取就不是那么容易了。目前主要的方式是人工获取或者日志提取,需注意的是,标注的类型与算法选择以及损失函数都有很大关系。
人工标注
人工标注比较灵活,但是若需要大量的训练数据,人工标注就不太现实了,人工标注主要有以下几种标注类型:单点标注,两两标注和列表标注。
日志抽取
当搜索引擎搭建起来之后,就可以通过用户点击记录来获取训练数据。对应查询返回的搜索结果,用户会点击其中的某些网页,假设用户优先点击的是和查询更相关的网页。尽管很多时候这种假设并不成立,但实际经验表明这种获取训练数据是可行的。
比如,结果 ABC 分别位于 123 位,B 比 A 位置低,但却得到了更多的点击,那么 B 的相关性可能好于 A。
这种点击数据隐含了 Query 到文档的相关性好坏。所以一般会使用点击倒置的高低位结果作为训练数据。
但是日志抽取也存在问题:
-
用户总是习惯于从上到下浏览搜索结果 -
用户点击有比较大的噪声 -
一般头查询(head query)才存在用户点击
3.排序学习设计方法
排序学习的模型通常分为单点法(Pointwise Approach)、配对法(Pairwise Approach)和列表法(Listwise Approach)三大类,三种方法并不是特定的算法,而是排序学习模型的设计思路,主要区别体现在损失函数(Loss Function)、以及相应的标签标注方式和优化方法的不同。
三种方法从 ML 角度的总览:
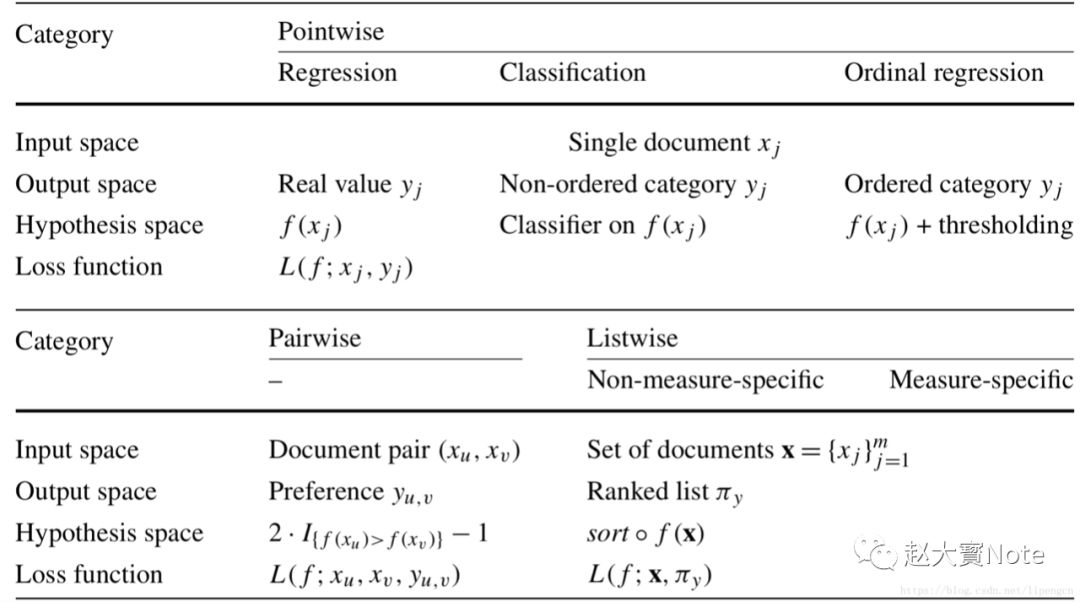
3.1.单点法(Point-wise)
单点法排序学习模型的每一个训练样本都仅仅是某一个查询关键字和某一个文档的配对。它们之间是否相关,与其他文档和其他查询关键字都没有关系。很明显,单点法排序学习是对现实的一个极大简化,但是对于训练排序算法来说是一个不错的起点。
单点法将文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档打分,打分结果即是搜索结果。


分别看一下损失函数的设计思想:
-
分类(Classification):输出空间包含的是无序类别,对每个查询-文档对的样本判断是否相关,可以是二分类的,如相关认为是正例,不相关认为是负例;也可以是类似 NDCG 那样的五级标注的多分类问题。
分类模型通常会输出一个概率值,可根据概率值的排序作为排序最终结果。
-
回归(Regression):输出空间包含的是真实值相关度得分,可通过回归来直接拟合相关度打分。
-
有序分类(Ordinal Classification):有序分类也称有序回归(Ordinal Regression),输出空间一般包含的是有序类别,通常的做法是找到一个打分函数,然后用一系列阈值对得分进行分割,得到有序类别。如采用 PRanking、基于 margin 的方法。
推荐领域的 Pointwise 排序学习
回到我们的推荐系统领域,最常用就是二元分类的 Pointwise,比如常见的点击率(CTR)预估问题,之所以用得多,是因为二元分类的 Pointwise 模型的复杂度通常比 Pairwise 和 Listwise 要低,而且可以借助用户的点击反馈自然地完成正负样例的标注,而其他 Pairwise 和 Listwise 的模型标注就没那么容易了。成功地将排序问题转化成分类问题,也就意味着我们机器学习中那些常用的分类方法都可以直接用来解决排序问题,如 LR、GBDT、SVM 等,甚至包括结合深度学习的很多推荐排序模型,都属于这种 Pointwise 的思想范畴。
Pointwise 方法存在的问题:
Pointwise 方法通过优化损失函数求解最优的参数,可以看到 Pointwise 方法非常简单,工程上也易实现,但是 Pointwise 也存在很多问题:
-
Pointwise 只考虑单个文档同 query 的相关性,没有考虑文档间的关系,然而排序追求的是排序结果,并不要求精确打分,只要有相对打分即可; -
通过分类只是把不同的文档做了一个简单的区分,同一个类别里的文档则无法深入区别,虽然我们可以根据预测的概率来区别,但实际上,这个概率只是准确度概率,并不是真正的排序靠前的预测概率; -
Pointwise 方法并没有考虑同一个 query 对应的文档间的内部依赖性。一方面,导致输入空间内的样本不是 IID 的,违反了 ML 的基本假设,另一方面,没有充分利用这种样本间的结构性。其次,当不同 query 对应不同数量的文档时,整体 loss 将容易被对应文档数量大的 query 组所支配,应该每组 query 都是等价的才合理。 -
很多时候,排序结果的 Top N 条的顺序重要性远比剩下全部顺序重要性要高,因为损失函数没有相对排序位置信息,这样会使损失函数可能无意的过多强调那些不重要的 docs,即那些排序在后面对用户体验影响小的 doc,所以对于位置靠前但是排序错误的文档应该加大惩罚。
代表算法:
基于神经网络的排序算法 RankProp、基于感知机的在线排序算法 Prank(Perception Rank)/OAP-BPM 和基于 SVM 的排序算法。
推荐中使用较多的 Pointwise 方法是 LR、GBDT、SVM、FM 以及结合 DNN 的各种排序算法。
3.2.配对法(Pair-wise)
配对法的基本思路是对样本进行两两比较,构建偏序文档对,从比较中学习排序,因为对于一个查询关键字来说,最重要的其实不是针对某一个文档的相关性是否估计得准确,而是要能够正确估计一组文档之间的 “相对关系”。
因此,Pairwise 的训练集样本从每一个 “关键字文档对” 变成了 “关键字文档文档配对”。也就是说,每一个数据样本其实是一个比较关系,当前一个文档比后一个文档相关排序更靠前的话,就是正例,否则便是负例,如下图。试想,有三个文档:A、B 和 C。完美的排序是 “B>C>A”。我们希望通过学习两两关系 “B>C”、“B>A” 和 “C>A” 来重构 “B>C>A”。

这里面有几个非常关键的假设。
第一,我们可以针对某一个关键字得到一个完美的排序关系。在实际操作中,这个关系可以通过五级相关标签来获得,也可以通过其他信息获得,比如点击率等信息。然而,这个完美的排序关系并不是永远都存在的。试想在电子商务网站中,对于查询关键字 “哈利波特”,有的用户希望购买书籍,有的用户则希望购买含有哈利波特图案的 T 恤,显然,这里面就不存在一个完美排序。
第二,我们寄希望能够学习文档之间的两两配对关系从而 “重构” 这个完美排序。然而,这也不是一个有 “保证” 的思路。用刚才的例子,希望学习两两关系 “B>C”、“B>A” 和 “C>A” 来重构完美排序 “B>C>A”。然而,实际中,这三个两两关系之间是独立的。特别是在预测的时候,即使模型能够正确判断 “B>C” 和 “C>A”,也不代表模型就一定能得到 “B>A”。注意,这里的关键是 “一定”,也就是模型有可能得到也有可能得不到。两两配对关系不能 “一定” 得到完美排序,这个结论其实就揭示了这种方法的不一致性。也就是说,我们并不能真正保证可以得到最优的排序。
第三,我们能够构建样本来描述这样的两两相对的比较关系。一个相对比较简单的情况,认为文档之间的两两关系来自于文档特征(Feature)之间的差异。也就是说,可以利用样本之间特征的差值当做新的特征,从而学习到差值到相关性差异这样的一组对应关系。
Pairwise 最终的算分,分类和回归都可以实现,不过最常用的还是二元分类,如下图:
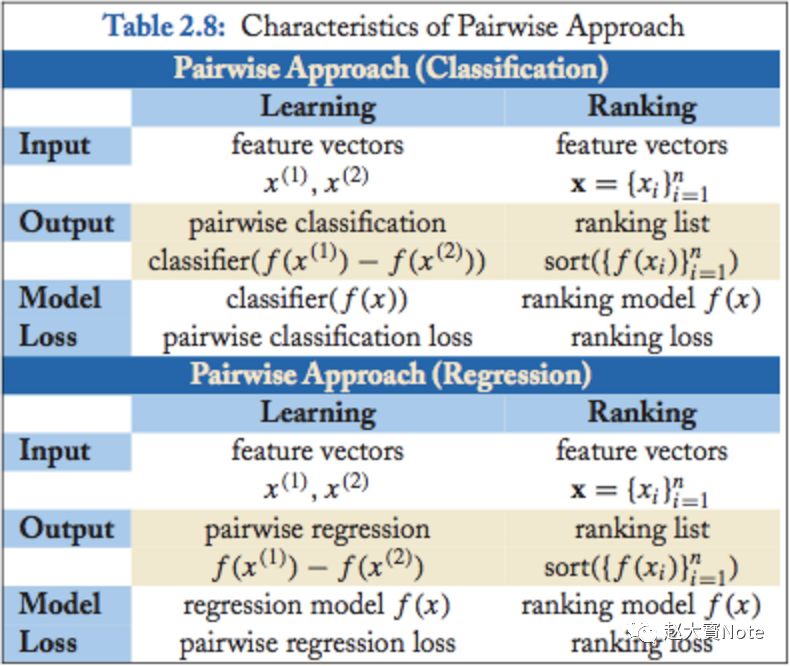
人工标注标签怎么转换到 pairwise 类方法的输出空间:
如果标注直接是相关度 ,则 doc pair 的真实标签定义为 如 如果标注是 pairwise preference ,则 doc pair 的真实标签定义为 如果标注是整体排序 π,则 doc pair 的真实标签定义为
Pairwise 方法存在的问题:
Pairwise 方法通过考虑两两文档之间的相关对顺序来进行排序,相比 Pointwise 方法有明显改善。但 Pairwise 方法仍有如下问题:
-
使用的是两文档之间相关度的损失函数,而它和真正衡量排序效果的指标之间存在很大不同,甚至可能是负相关的,如可能出现 Pairwise Loss 越来越低,但 NDCG 分数也越来越低的现象。 -
只考虑了两个文档的先后顺序,且没有考虑文档在搜索列表中出现的位置,导致最终排序效果并不理想。 -
不同的查询,其相关文档数量差异很大,转换为文档对之后,有的查询可能有几百对文档,有的可能只有几十个,这样不加均一化地在一起学习,模型会优先考虑文档对数量多的查询,减少这些查询的 loss,最终对机器学习的效果评价造成困难。 -
Pairwise 方法的训练样例是偏序文档对,它将对文档的排序转化为对不同文档与查询相关性大小关系的预测;因此,如果因某个文档相关性被预测错误,或文档对的两个文档相关性均被预测错误,则会影响与之关联的其它文档,进而引起连锁反应并影响最终排序结果。
代表算法:
基于 SVM 的 Ranking SVM 算法、基于神经网络的 RankNet 算法和基于 Boosting 的 RankBoost 算法。
推荐中使用较多的 Pairwise 方法是贝叶斯个性化排序(Bayesian personalized ranking,BPR)。
Pointwise 与 Pairwise 的结合方案
Pairwise 方法的训练样例是偏序文档对,它将对文档的排序转化为对不同文档与查询相关性大小关系的预测;因此,如果因某个文档相关性被预测错误,或文档对的两个文档相关性均被预测错误,则会影响与之关联的其它文档,进而引起连锁反应并影响最终排序结果。而 Pointwise 方法的训练样例是单个文档,它解决的问题恰恰是对单个文档的相关性预测。基于此,本文在 Pairwise 方法的基础上,增加 Pointwise 损失函数,通过融入对单个文档相关性大小的考虑,减小因错误预测单个文档相关性大小而导致连锁反应所造成的损失,来优化 Pairwise 方法去排序模型,提升其排序性能。
1)推荐领域中,凡是基于协同过滤对单个物品进行偏好打分预测的模型,其实都可以看成是 Pointwise 排序方法。对于 Pairwise 方法,协同过滤可以发展为用户对一对物品偏好。一个通常的做法是将 Pointwise 的输出作为 Pairwise 的输入特征,然后两两作差,在用 Pointwise 方法保证单个物品预测精度的基础上,用 Pairwise 对做进一步排序优化。这种方法的一个典型案例是 BPR,它是推荐领域中使用较多的 Pairwise 方法,具体内容我们将在下一小节单独介绍。
2)将 Pointwise 的损失函数融合进 Pairwise 的损失函数7
考查现存 Pointwise 方法,大多将排序问题转化为分类或回归问题,所用到的损失函数分别为分类或回归问题的损失函数。本文采用回归损失函数,它也是人工神经网络中常用的用于衡量训练样例的预测值与真实值之间误差的函数。记为训练集合中文档的相关性大小标注值,为排序模型对文档的相关性预测值,则其 Pointwise 损失函数形式如下:
考虑到 Pairwise 方法不会将所有文档的相关性预测错误,且单个文档在不同偏序文档对中存在重复,因而将 Pairwise 损失函数与 Pointwise 损失函数线性插值,得到改进的损失函数,形式如下:
3.3.列表法(List-wise)
相对于尝试学习每一个样本是否相关或者两个文档的相对比较关系,列表法排序学习的基本思路是尝试直接优化像 NDCG(Normalized Discounted Cumulative Gain)这样的指标,从而能够学习到最佳排序结果。
关于 NDCG 以及其他相关排序指标,可参考我之前写的文章《工业界推荐系统的评测标准》。
列表法的相关研究有很大一部分来自于微软研究院,这其中著名的作者就有微软亚洲院的徐君、李航、刘铁岩等人,以及来自微软西雅图的研究院的著名排序算法 LambdaMART 以及 Bing 搜索引擎的主导人克里斯托弗·博格斯(Christopher J.C. Burges)。
列表法排序学习有两种基本思路。第一种称为 Measure-specific,就是直接针对 NDCG 这样的指标进行优化。目的简单明了,用什么做衡量标准,就优化什么目标。第二种称为 Non-measure specific,则是根据一个已经知道的最优排序,尝试重建这个顺序,然后来衡量这中间的差异。
1)Measure-specific,直接针对 NDCG 类的排序指标进行优化
先来看看直接优化排序指标的难点和核心在什么地方。
难点在于,希望能够优化 NDCG 指标这样的 “理想” 很美好,但是现实却很残酷。NDCG、MAP 以及 AUC 这类排序标准,都是在数学的形式上的 “非连续”(Non-Continuous)和 “非可微分”(Non-Differentiable)。而绝大多数的优化算法都是基于 “连续”(Continuous)和 “可微分”(Differentiable)函数的。因此,直接优化难度比较大。
针对这种情况,主要有这么几种解决方法。
第一种方法是,既然直接优化有难度,那就找一个近似 NDCG 的另外一种指标。而这种替代的指标是 “连续” 和 “可微分” 的 。只要我们建立这个替代指标和 NDCG 之间的近似关系,那么就能够通过优化这个替代指标达到逼近优化 NDCG 的目的。这类的代表性算法的有 SoftRank 和 AppRank。
第二种方法是,尝试从数学的形式上写出一个 NDCG 等指标的 “边界”(Bound),然后优化这个边界。比如,如果推导出一个上界,那就可以通过最小化这个上界来优化 NDCG。这类的代表性算法有 SVM-MAP 和 SVM-NDCG。
第三种方法则是,希望从优化算法上下手,看是否能够设计出复杂的优化算法来达到优化 NDCG 等指标的目的。对于这类算法来说,算法要求的目标函数可以是 “非连续” 和 “非可微分” 的。这类的代表性算法有 AdaRank 和 RankGP。
2)Non-measure specific,尝试重建最优顺序,衡量其中差异
这种思路的主要假设是,已经知道了针对某个搜索关键字的完美排序,那么怎么通过学习算法来逼近这个完美排序。我们希望缩小预测排序和完美排序之间的差距。值得注意的是,在这种思路的讨论中,优化 NDCG 等排序的指标并不是主要目的。这里面的代表有 ListNet 和 ListMLE。
3)列表法和配对法的中间解法
第三种思路某种程度上说是第一种思路的一个分支,因为很特别,这里单独列出来。其特点是在纯列表法和配对法之间寻求一种中间解法。具体来说,这类思路的核心思想,是从 NDCG 等指标中受到启发,设计出一种替代的目标函数。这一步和刚才介绍的第一种思路中的第一个方向有异曲同工之妙,都是希望能够找到替代品。
找到替代品以后,接下来就是把直接优化列表的想法退化成优化某种配对。这第二步就更进一步简化了问题。这个方向的代表方法就是微软发明的 LambdaRank 以及后来的 LambdaMART。微软发明的这个系列算法成了微软的搜索引擎 Bing 的核心算法之一,而且 LambdaMART 也是推荐领域中可能用到一类排序算法。
Listwise 方法存在的问题:
列表法相较单点法和配对法针对排序问题的模型设计更加自然,解决了排序应该基于 query 和 position 问题。
但列表法也存在一些问题:一些算法需要基于排列来计算 loss,从而使得训练复杂度较高,如 ListNet 和 BoltzRank。此外,位置信息并没有在 loss 中得到充分利用,可以考虑在 ListNet 和 ListMLE 的 loss 中引入位置折扣因子。
代表算法:
基于 Measure-specific 的 SoftRank、SVM-MAP、SoftRank、LambdaRank、LambdaMART,基于 Non-measure specific 的 ListNet、ListMLE、BoltzRank。
推荐中使用较多的 Listwise 方法是 LambdaMART。
4.应用场景
在推荐领域,排序学习可能会用在以下场景:
-
用于多路召回策略的融合排序
一个推荐系统的召回阶段可能会用到多种不同召回策略,比如基于内容的召回、基于热门物品的召回、基于协同过滤的召回、基于类别和标签的召回等等,不同的召回策略召回的物品无法确切地分辨哪个策略召回更重要,所以需要一个排序学习模型,根据用户的行为反馈来对多路召回的物品进行排序推荐,这也是排序模块的一大重要作用。
-
一个排序模型完成召回排序
某些简单的推荐场景下,召回排序过程区分的不够开,目标比较单一,比如相关推荐,对相关性要求比较高,此时可以用 LTR,一个排序模型就可以完成召回排序任务。
-
解决多目标排序问题
通常一个推荐系统的目标是提高点击率(CTR)或转化率(CVR),但是这些并不能完全反映用户对推荐物品的满意度,以此为目标的推荐系统也无法保证用户存留。为了提高用户对推荐物品满意度,可能还需要依赖更多的指标,比如加购、收藏、分享等等。由此便产生了多种目标,如何优化最终推荐列表的顺序来使得众多指标在不同的场景下尽可能达到最优或者满意,这就是推荐系统中的多目标排序问题,而排序学习是解决多目标排序问题的一种重要方法。
关于多目标学习,限于篇幅我打算单独写文章详细阐述,这里仅谈一下常见的多目标学习方法。
1)每个目标训练一个模型,每个模型算出一个分数(预估概率),然后根据业务设计一个经验公式计算出综合分数,再按照综合分数进行排序推荐。这个经验公式通常会包含代表各个目标重要性的超参数(比如最简单的线性回归中的权重),但这些超参数基本是靠人工根据经验来确定的,因为很难标注 Label,不太容易用模型学习。
2)使用排序学习方法融合多目标,一种常见的方法是对多目标产生的物品构建 Pair,比如用户对物品 产生的购买,对物品 产生了了点击,假定我们觉得购买的目标比点击的目标更重要,就可以让 𝑖>𝑢𝑗。有了顺序对后,我们便可以训练排序学习模型,这样一个模型就可以融合多个目标,而不用训练多个模型。
3)采⽤用多任务学习(multi-task learning),共享参数,学习出多个分数,最后结合起来。典型的算法有谷歌的 MMOE(Multi-gate Mixture-of-Experts)以及阿里的 ESMM(Entire Space Multi-Task Model)。
5.参考资料
1 [延伸]Tie-Yan Liu. Learning to Rank for Information Retrieval. Springer
2 [延伸]Hang Li. Learning to rank for information retrieval and natural language processing
3 [延伸]Li Hang. A Short Introduction to Learning to Rank
4 Learning to rank 学习基础
5 达观数据. 资讯信息流 LTR 实践. 机器之心
6 美团技术团队. 深度学习在美团推荐平台排序中的运用
7 吴佳金等. 改进 Pairwise 损失函数的排序学习方法. 知网
8 Steffen Rendle et. Bayesian Personalized Ranking from Implicit Feedback. arxiv
9 刘建平. 贝叶斯个性化排序 (BPR) 算法小结. cnblogs
10 笨兔勿应. Learning to Rank 算法介绍. cnblogs
11 卢东宁.推荐系统中的排序学习
推荐阅读
关注公众号回复关键字【推荐系统论文】获取超百篇完整论文列表下载链接。



