张钹院士 | AI科学突破的前夜,教授们应当看到什么?

12月27日, 清华大学举办了一个研讨会,主题是「从AlphaGo到通用人工智能:脑科学与人工智能」。这是清华大学脑与智能实验室自12月15日成立之后举办的首次学术研讨会。
在这次研讨会上,张钹院士做了《AI 和神经科学》的报告,他的报告全程英文,但最后用中文做了点睛之笔。张钹院士在报告中首先分析了什么是智能。他认为智能包含三个成分:perceive、rational thinking和taking action。综合来说就是,一个智能体要能够感知它周围的环境,进行思考并采取行动来最大化它实现某些目的的机会。
现在的AI model无外乎两种类型:符号模型(Symbolic model)和亚符号模型(Sub-symbolic model)或者称为连接主义(Connectionism)。
符号模型
符号模型的基本思想主要由J. McCarthy等人于1955年提出。他们认为AI的研究基于这样一个猜想,即学习或者任何其他的智能特征原则上都可以被精确地描述。他们提出两个基本假设:
物理符号系统假设:物理符号系统是智能的充分必要条件;
人脑和计算机都是物理符号系统,认知过程就是在符号表示上的运算。
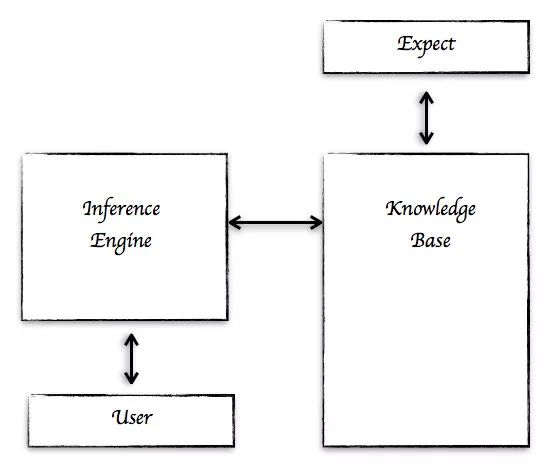
在1976年,Newell和Simon提出了一个符号模型。它包含两部分:知识库和推理机(Inference Engine)。这种AI主要是知识驱动或者基于规则的模型。
在McCarthy等人提出符号模型之后大约40年,1997年,IBM推出的基于符号模型的IBM深蓝(Deep Blue)在国际象棋比赛中以2赢1败3平打败了当时的世界冠军Kaspanov。在深蓝的系统中,包含了700,000份人类大师的棋谱,这些棋谱分别用V-value函数来表示,函数有8000多个变量。
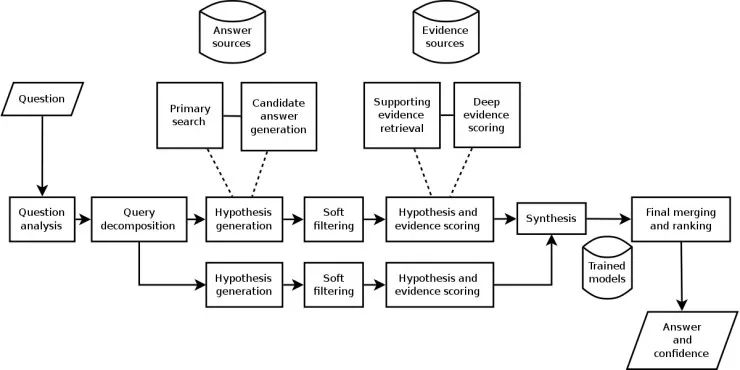
IBM沃森的结构
2011年,IBM沃森在综艺节目《危险边缘》中打败了最高奖金得主布拉德·鲁特尔和连胜纪录保持者肯·詹宁斯。同样它也是基于知识的符号型AI系统,它的知识来源于百科全书、字典 、词典、新闻、文学作品以及维基百科的全部文本,在其4TB的磁盘中包含了2亿页结构化和非结构化的信息。
以Watson为代表的新一代的基于知识的符号模型系统相对之前有少许变化。其一是知识库中的知识表示变成多样化;其二是多推理机(Multi-Inference Engines)结构;其三是增加了大众知识(来自互联网)。
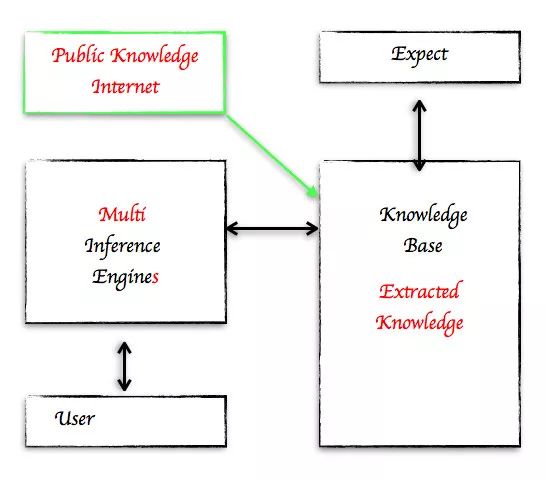
但是这种知识驱动的符号模型也有其局限之处,如下:
有很多人类行为(知识)并不能精确描述,例如常识;
知识库总是有限的,它不能包含所有的信息;
知识是确定的;
它只能描述特定的领域;
大量知识不能做到定量化(例如质量)。
所以这种模型只能在宏观层面上用来模拟人类的某些行为。
亚符号模型/连接主义
1965年,在达特茅斯夏季研讨会的提议文件(http://t.cn/RAnjsCF)的问题2中说到「怎么安排一组(假设的)神经元来形成概念?这个问题仍需要更多的理论工作。」
对于神经网络,大致有两个时期。第一个为浅层神经网络(Shallow Neural Network),这个网络只有一层隐藏层。在这种网络中,需要手工特征(Hand-crafted Features)来构建分类器,因此它需要有领域的知识。
另外一种是在2000-2006年间,由Igor Aizenberg和Geoffey Hinton完成。这个网络有更多的隐藏层,称为多隐藏层(深度)神经网络。多隐藏层的结构带来了很大的变化。首先是,我们可以用Raw data代替手工特征,所以领域知识也就不再是必须的了。以图像为例,我们只需要将图像按照pixel的格式输入即可。其次,深度神经网络让亚符号模型的表现有了很大的提高。再次,在90年代AI研究人员发展了一系列成熟的统计数学工具,这在模型中有很多表现,让模型变得更具可度量和可验证性。另外,这个模型有很清晰的神经科学的解释。
这种AI系统主要是基于数据驱动。只要有数据,我们不需要有太多的领域知识就可以在任务中做得很好。基于深度神经网络的例子很多,例如AlphaGo。
相比于人类的神经网络,它仍有一系列的缺点。如下:
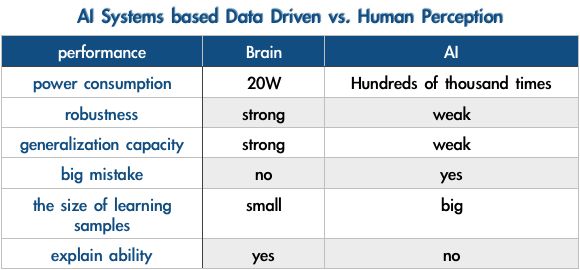
以2014年Goodfellow发表的Adversarial examples and adversarial training为例,输入的图片加上一点点的噪声,AI系统就将一张明显是熊猫的图片以99.3%的置信度识别成长臂猿。所以目前的AI系统在robustness上还是非常弱的。

这种AI系统只是一种分类机器,是一个AI without Understanding,所以仅仅依靠基于数据驱动的深度学习很难产生真正的智能,也远没有触及智能的核心。

人工智能的核心
前面说道,深度学习并没有触及到人工智能的核心,那么人工智能的核心是什么呢?张钹院士认为主要表现为以下五个方面:
在缺乏知识和数据的情况下依然能够完成任务;
在信息不完善(甚至缺乏信息)的情况下依然能够完成任务;
能够处理非确定性的任务;
能够处理动态任务;
能够处理多领域和多任务。
AI 研究的新趋势
基于对上面的讨论,可以看出目前AI的研究有两种,基于知识的符号模型和基于数据的亚符号模型(连接主义)。张钹院士认为现在在AI研究中渐渐出现了一种新的趋势,即建立一种同时基于知识和数据的AI系统。
他认为,处理知识是人类所擅长的,而处理数据是计算机所擅长的。如果能够将二者结合起来,一定能够构建出一个比人类更加智能的系统。
如何去做呢?
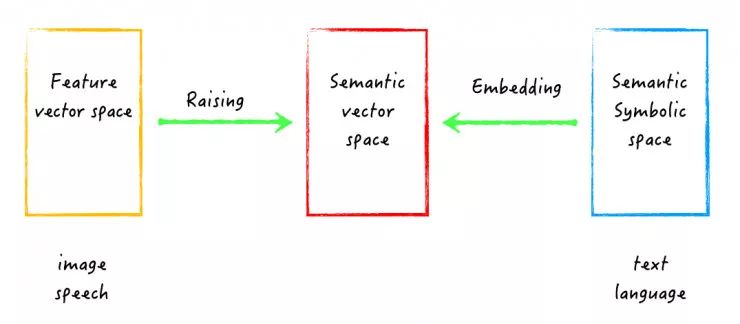
现在我们有两种基本的AI方法。一种是基于语义符号的方法,一般用在处理文本和语言,我们会构建一个语义符号空间(Semantic Symbolic Space)。另一种是基于数据的特性向量的方法,用来处理图像和语音,我们会构建一个特性向量空间(Feature Vector Space)。
因此我们可以构建一个新的空间,叫做语义向量空间(Semantic Vector Space),即将语义符号空间进行embedding处理或者将特性向量空间进行Raising处理。通过这种方法,我们将可以统一处理text、language、image和speech。
张钹院士认为在这些方面,尤其是在将特性向量空间raising到语义空间上,我们应该向神经科学学习。例如脑神经中有feedback connection、lateral connections、sparse firing、attention mechanism、multi-model、memory等机制,这些都值得设计AI系统的人员去注意和学习。
研究案例
张钹院士介绍了四个案例来说明如何向神经科学学习,以及如何构建同时基于知识和数据的AI系统。
一、Sparse Firing+HMAX
论文:Sparsity-Regularized HMAX for Visual Recognition
这项工作的一个创新点在于将神经科学中的发现Sparse firing和HMAX结合在一起。
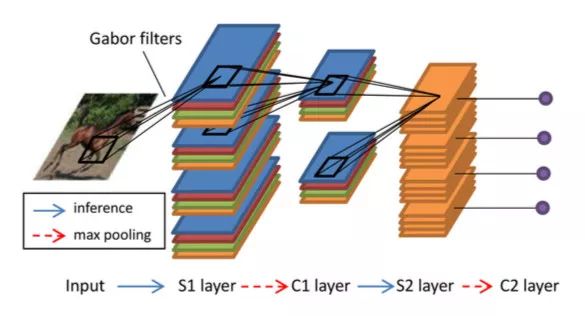
HMAX模型是Riesenhuber, M. & Poggio, T等人于1999年提出,其理念是模仿人的认知,由点到线到面逐级抽象,还原高级特性。HMAX是计算机视觉中非常重要的一个模型。
Sparse firing是神经科学中的一个概念。神经科学的研究表明在人的大脑中,针对一个刺激大多数神经元是沉默的。例如依照大脑内细胞的密度、探针大小以及探针可以测量到的信号距离来估计,一根探针应该可以测到周围十个甚至上百个神经元的信号,但实际情况通常只能测到几个神经元信号,90%以上的神经元是测不到的。这就是说针对一个刺激,只有少数(稀疏)神经元是被激活的。
大脑神经元的这种sparse firing激活方式,或者说sparse coding方式有许多优点,一方面可以用少量的神经元对大量的特征进行编码,另一方面也能降低解码误判以及能量损耗等等。
这篇文章的工作正是将Sparse firing与HMAX模型相结合,应用于图像识别任务当中。工作非常有意思,感兴趣的读者不妨一读。
二、视觉识别验证码
论文:A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs ( Science, 26 Oct. 2017)
这篇文章于2017年10月份发表于Science期刊,是人工智能向神经科学学习的一个范例。
目前的机器学习模型在图像识别的任务中往往需要大量的训练数据集,而训练的结果往往只能应用于特定的领域内。但人类的视觉智能则可以通过少数样本(甚至不需要样本)来学习并能够很轻易地迁移到完全不同的情景当中。所以向人类的视觉神经机理学习或许是机器学习模型进一步发展的方向。
在这篇文章中,知名的人工智能创业公司Vicarious就通过人类视觉一些工作机理的启发,构建了一个层级模型,他们称之为「递归皮层网络」(Recursive Cortical Network, RCN)。在模型中他们引入了视觉概率生成的模型框架,其中基于消息传送(message-passing)的推断,以统一的方式处理图像的识别、分割和推理(Reasoning)。
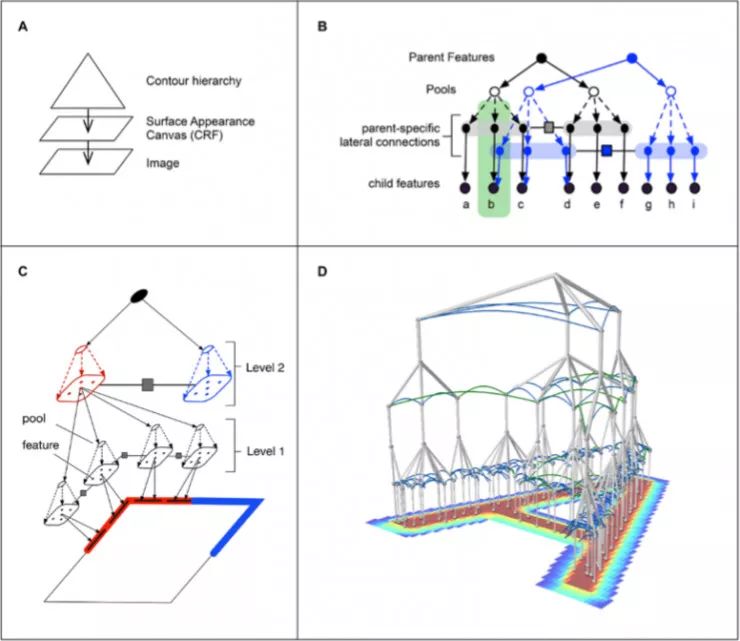
这个方法表现出了非常优秀的泛化和遮挡推理(occlusion-reasoning)能力,在困难的场景文字识别任务上远优于深度神经网络,且具有300倍的数据效率(data efficient)优势。
其实验结果如下表:
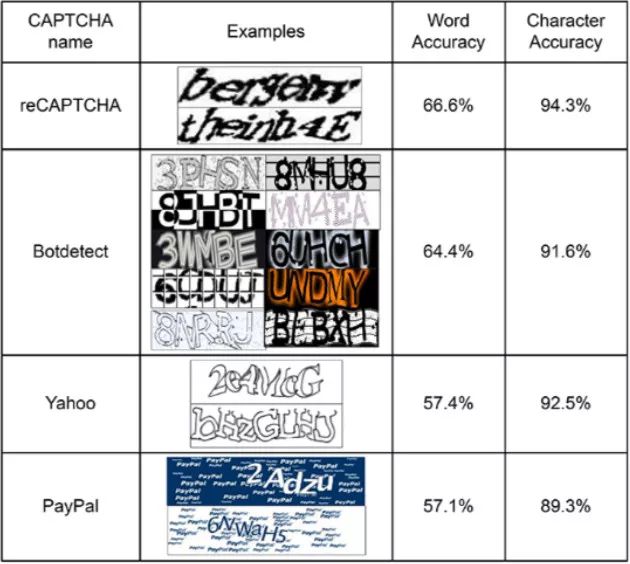
在reCAPTCHA的验证码单词识别准确率已经可以达到66.6%,BotDetect为64.4%,雅虎上为57.4%,PayPal上为 57.1%。
三、DNN的可解释性
论文:Improving interpretability of deep neural networks with semantic information (2017)
这篇文章是张钹院士团队在CVPR 2017上的一篇论文,是「Knowledge+data」的一个典型范例。
在传统的图像识别的DNN模型中,我们输入图片,得到描述性结果,但是我们却不知道为什么会得到这样的结果,也不知道隐藏层中都是什么feature,或者当得到一个错误结果时我们不知道为什么会错。
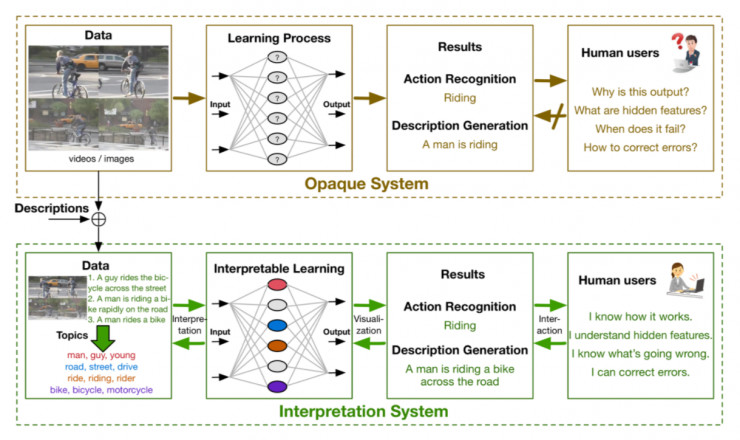
这篇文章的研究主要方法就是先获得一些人类对图片的描述作为语义信息数据;将这些数据和图片同时送入到DNN模型中进行训练;这里每一个神经元都会与一个topic进行关联,于是整个网络变得具有可解释性。
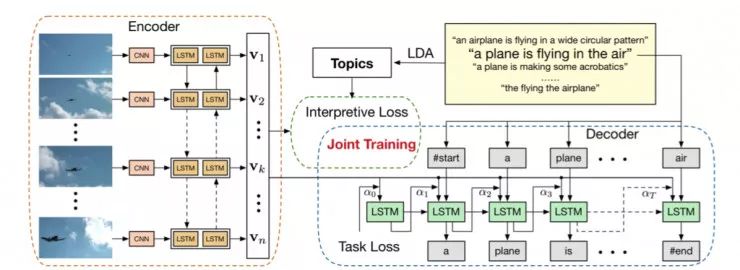
四、Zero-shot视频识别
论文:Recognizing an Action Using Its Name: A Knowledge-Based Approach,这篇文章的工作也是一个典型的「Knowledge+data」范例。
现有的动作识别算法需要一组正面的示例来训练每个动作的分类器。但是,我们知道,动作类的数量非常大,用户的查询变化也很大。预先定义所有可能的行动类别是不切实际的。
在本文中作者提出了一种不需要正面示例的方法,通常这种方法被称为「Zero-shot Learning」。目前的零点学习模式通常训练一系列属性分类器,然后根据属性表示识别目标动作。为了确保特定动作类别的最大覆盖范围,基于属性的方法需要大量可靠且准确的属性分类器,这在现实世界中通常是不可用的。
在这篇论文中,作者提出的方法只需要一个行动名称作为输入来识别感兴趣的行为,没有任何预先训练的属性分类器和正面的示例。

给定一个动作名称后,首先根据外部知识(例如 Wikipedia)建立一个类比池,类比池中的每个动作都会与不同层次的目标动作有关。
从外部知识推断的相关性信息可能是嘈杂的。所以他们又提出一种算法,即自适应多模型秩保持映射(Adaptive multi-model rank-preserving mapping model, AMRM)来训练动作识别的分类器,能够自适应地评估类比池中每个图片的相关性。
以上四个例子有两类,一类是向神经科学学习的结果;一类是基于「数据+知识」的结果。
张钹院士介绍说他们工作的一个思路就是:数据+知识=统计学习模型。其中知识包括先验模型、逻辑规则、表示学习、强健的统计约束等。
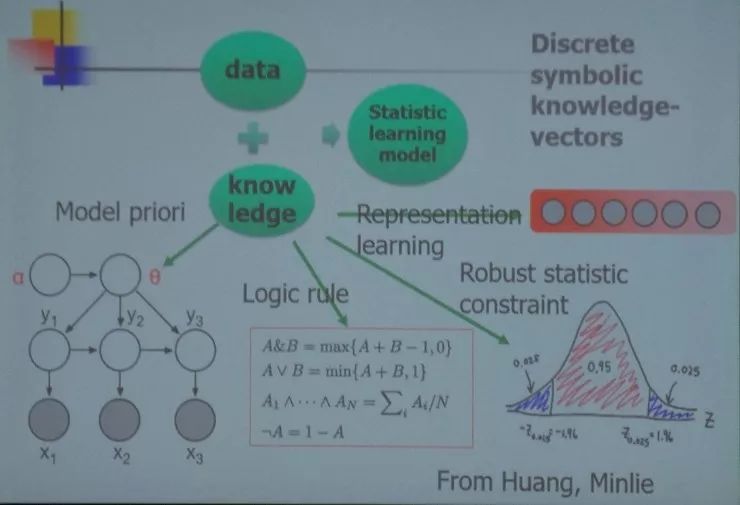
此外他还提到了的 Bayesian Deep Learning 的概念。

最后他认为我们目前的AI系统是在介观层面上模仿了人类,我们还需要向神经科学学习和合作。在AI系统的研究中应当将知识驱动和数据驱动结合起来,将理性行为和感性行为结合起来。
总结(划重点)
张钹院士演讲的亮点在最后的summary,原文整理如下(稍作修改):

鲁迅说到,不同的人对《红楼梦》有不同的看法,经济学家看到《易》,道学家看到淫,才子看到缠绵,革命家看到反满,流言家看到宫闱秘事。
现在的人工智能有点儿像《红楼梦》,不同的人有不同的看法。企业家看到商机,科学家(霍金)看到危险,工程师看到应用前景,老百姓看到AlphaGo打败李世石。我现在就说教授们应该看到什么,这也是我今天报告希望大家能够看到的。
看到什么呢?就是——AI科学的曙光。
大家看待AI,有两个过程。过去是低看了AI,觉得AI没什么。现在AlphaGo出来以后,突然AI上天了,大家对它仰视了。我告诉大家,这两个都不对。大家要平视AI。
为什么过去对AI有这个印象呢?确实,过去的AI我们没有资格去谈,因为我们只有猜测、假设,只有case by case。我们没有什么本事。再加上有些人炒作,不靠谱的东西很多。所以过去我们不能给大家谈。
现在我们有希望给大家谈的,就是刚才讲的。现在从深度学习中大家看到的是广泛的应用。但是没有看到深度学习给我们点燃了一个曙光,就是人工智能完全可以用建立数学模型的方法来做。当然它也告诉我们,光用数学的方法来建造人工智能是不行的,例如深度学习获得的结果只是一个机械的分类器,这跟人的认知或感知完全是两码事。
那么我们接下来怎么走向建造人工智能的数学模型这一步呢?只有两条路。一条就是向脑科学学习,看大脑里面是怎么做到智能的。大脑里面也是使用神经网络, 为什么它可以认识「鸟」,而计算机就不行呢?我们很清楚,计算机的这个神经网络和大脑的神经网络不可同日而语。我们必须向大脑学习。
另一条路就是把知识和数据结合起来。大家想一想,人的智能主要不是来自于数据,而是来自于知识。但是为什么大家要把数据看得这么重呢?这是因为数据很多,而且计算机最擅长的就是数据的处理。所以就给大家一个模糊的认识,以为数据决定一切。这是错的。但是这也给我们提了个希望,既然计算机搞数据厉害,人利用知识厉害,如果我们能够让这两个结合起来,我们就有希望做出比人还要好的系统。
问:张老师您好。您最后一个slice说在AI中商人看到了商机等等。所以我特别想知道您最后问的问题的答案,教授们应该看到的什么?
张钹:教授应当看到的是——去做人工智能的基础问题。我们不能去看那个商机,商机应该让企业家去看。我现在认为人工智能正处在突破的前夜。深度学习不是我们的突破,深度学习只是展示了突破的希望,因为深度学习并没有构造真正的Intelligence。
现在我们有机会触及到the core of intelligence。在什么情况下我们才有可能触碰the core of intelligence呢?就是刚才我讲那5个条件,即
在缺乏知识和数据的情况下依然能够完成任务;
在信息不完善(甚至缺乏信息)的情况下依然能够完成任务;
能够处理非确定性的任务;
能够处理动态任务;
能够处理多领域和多任务。
现在的人工智能做的并不是真正的智能。它是选择了那些确定性的、静态的问题,这个本来就是计算机会干的事。计算机不会干的事是随机应变,举一反三,由表及里,这才是智能的本质。我们过去做的系统,没法做到智能的本质,因为我们还不知道。深度学习给了我们一个提示,就是我们已经接触到了智能的本质。那么我们沿着这个去做,才有希望。
大家现在都在消费深度学习。我们都知道,如果用深度学习来做识别,把石头看成人没有关系;但是做决策,把敌人看成朋友是不允许的。深度学习不解决这个问题,它绝对会产生大错。这是它本质造成的。 所以我一直说,到目前为止,在复杂路况下,还很难实现真正的无人车,「无人车」旁边还需要坐一个人。为什么?稍微懂点人工智能的人都知道,目前人工智能还不能解决突发事件。
过去我们没有能力做到真正智能这一点。而今天是科学研究人员的一个机会。希望大家去做。如果大家持续去做,我相信会有新的发现。现在很多人看到了商机,看到了应用,看到了计算机打败李世石,但却很少人有看到这一点。局外人看不清,作为局内人,我提醒大家,教授应当看到——AI科学的曙光。
本文经授权转载自AI科技评论,版权归原作者所有。

📚往期文章推荐

🔗北大传奇天才在海外沉沦20多年,如今的他却因这件事震惊全世界!
🔗Gary Marcus | 提出对深度学习的系统性批判,指明其面临的十大挑战

点击“阅读原文”,移步求知书店,可查阅选购德先生推荐书籍。


