BERT模型精讲

本文概览:
1. Autoregressive语言模型与Autoencoder语言模型
1.1 语言模型概念介绍
Autoregressive语言模型:指的是依据前面(或后面)出现的单词来预测当前时刻的单词,代表有 ELMo, GPT等。
Autoencoder语言模型:通过上下文信息来预测被mask的单词,代表有 BERT , Word2Vec(CBOW) 。

1.2 二者各自的优缺点
Autoregressive语言模型:
-
缺点: 它 只能利用单向语义而不能同时利用上下文信息。ELMo通过双向都做Autoregressive模型,然后进行拼接,但从结果来看,效果并不是太好。 -
优点:对生成模型友好,天然符合生成式任务的生成过程。这也是为什么 GPT 能够编故事的原因。
Autoencoder语言模型:
-
缺点:由于训练中采用了 [MASK] 标记,导致 预训练数据与微调阶段数据不一致的问题。BERT独立性假设问题,即 没有对被遮掩(Mask)的 token 之间的关系进行学习。此外对于生成式问题,Autoencoder模型也显得捉襟见肘。 -
优点:能够很好的编码上下文语义信息(即考虑句子的双向信息), 在自然语言理解相关的下游任务上表现突出。
2. DAE与Masked Language Model
2.1 AutoEncoder
如下图所示,AutoEncoder框架包含两大模块:编码过程和解码过程。通过 将输入样本 映射到特征空间 ,即编码过程;然后再通过 将抽象特征 映射回原始空间得到重构样本 ,即解码过程。优化目标则是通过最小化重构误差来同时优化encoder和decoder,从而学习得到针对输入样本 的抽象特征表示 。
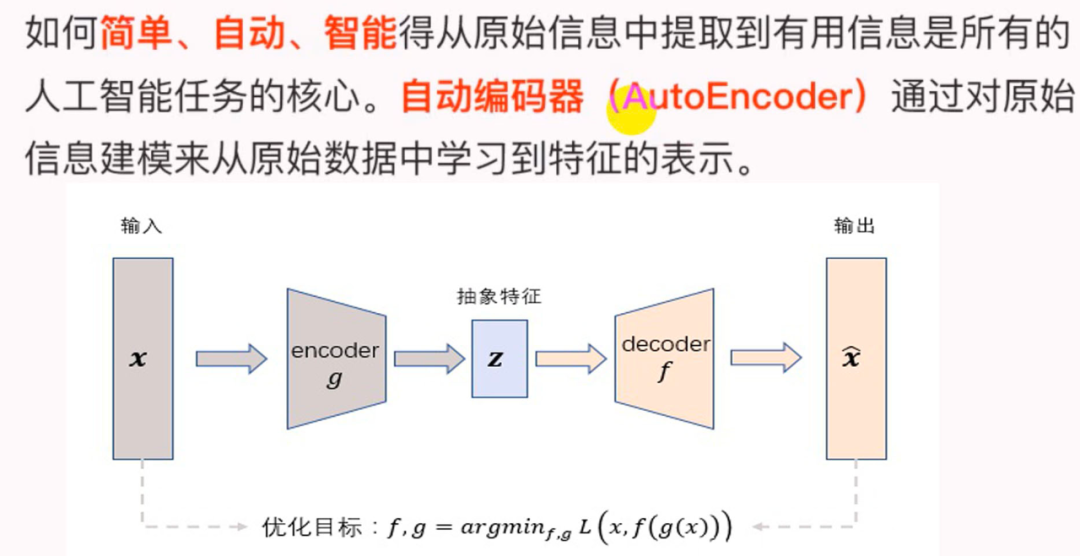
这里我们可以看到,AutoEncoder在优化过程中无需使用样本的label,本质上是把样本的输入同时作为神经网络的输入和输出,通过最小化重构误差希望学习到样本的抽象特征表示 。这种无监督的优化方式大大提升了模型的通用性。
对于基于神经网络的AutoEncoder模型来说,则是encoder部分通过逐层降低神经元个数来对数据进行压缩;decoder部分基于数据的抽象表示逐层提升神经元数量,最终实现对输入样本的重构。
这里值得注意的是,由于AutoEncoder通过神经网络来学习每个样本的唯一抽象表示,这会带来一个问题:当神经网络的参数复杂到一定程度时AutoEncoder很容易存在过拟合的风险。
2.2 Denoising AutoEncoder(DAE)
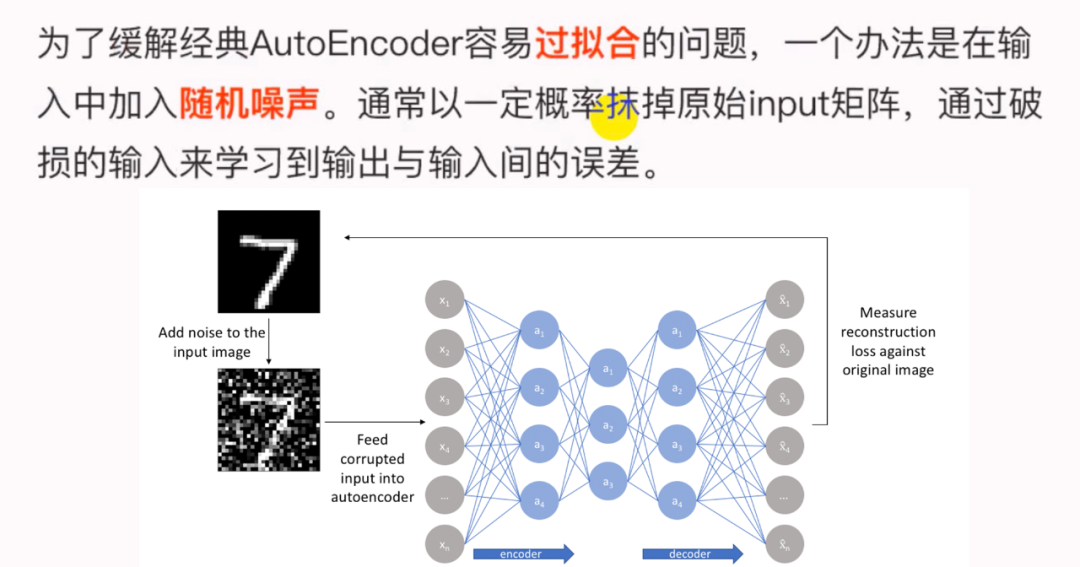
为了缓解经典AutoEncoder容易过拟合的问题,一个办法是在输入中加入随机噪声,Vincent等人提出了Denoising AutoEncoder,即在传统AutoEncoder输入层加入随机噪声来增强模型的鲁棒性;另一个办法就是结合正则化思想,Rifai等人提出了Contractive AutoEncoder,通过在AutoEncoder目标函数中加上encoder的Jacobian矩阵范式来约束使得encoder能够学到具有抗干扰的抽象特征。
下图是Denoising AutoEncoder的模型框架。目前添加噪声的方式大多分为两种:
-
添加服从特定分布的随机噪声; -
随机将输入x中特定比例的数值置为0;
DAE模型的优势:
-
通过与非破损数据训练的对比,破损数据训练出来的 Weight噪声较小。因为擦除数据的时候不小心把输入噪声给擦掉了。 -
破损数据一定程度上 减轻了训练数据与测试数据的代沟。由于数据的部分被擦掉了,因而这破损数据一定程度上比较接近测试数据。
推荐阅读论文:
【1】Extracting and composing robust features with denoising autoencoders, Pascal Vincent etc, 2008.
【2】Contractive auto-encoders: Explicit invariance during feature extraction, Rifai S etc, 2011.
2.3 DAE与Masked Language Model联系
-
BERT模型是基于 Transformer Encoder来构建的一种模型。 -
BERT模型基于 DAE(Denoising AutoEncoder,去燥自编码器)的,这部分在BERT中被称为 Masked Language Model (MLM)。 -
MLM并不是严格意义上的语言模型,它仅仅是训练语言模型的一种方式。BERT随机把一些单词通过 MASk标签来代替,并接着去预测被 MASk的这个单词,过程其实就是DAE的过程。
3. Transformer模型回顾
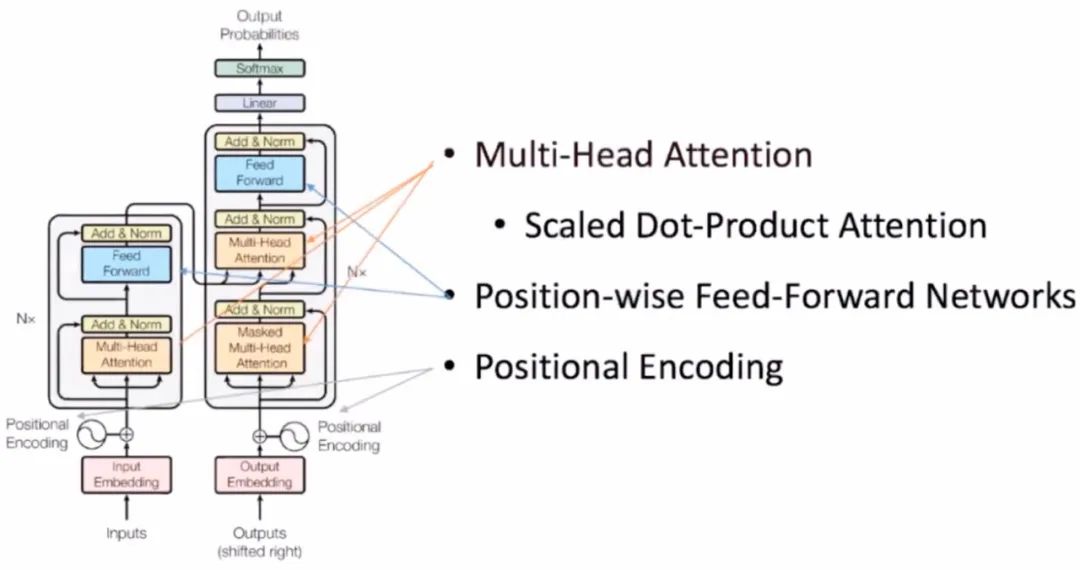
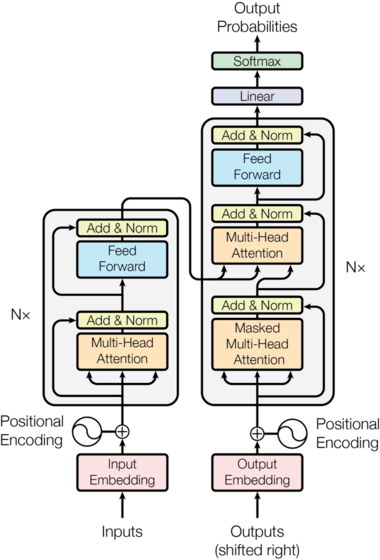
Transformer模型使用经典的encoder-decoder架构,由encoder和decoder两部分组成。
-
下图左侧用 框出来的,就是我们encoder的一层。encoder一共有 层这样的结构。 -
下图右侧用 框出来的,就是我们decoder的一层。decoder一共有 层这样的结构。 -
输入序列经过Input Embedding和Positional Encoding相加后,输入到encoder中。 -
输出序列经过Output Embedding和Positional Encoding相加后,输入到decoder中。 -
最后,decoder输出的结果,经过一个线性层,然后计算 。
3.1 Encdoer部分
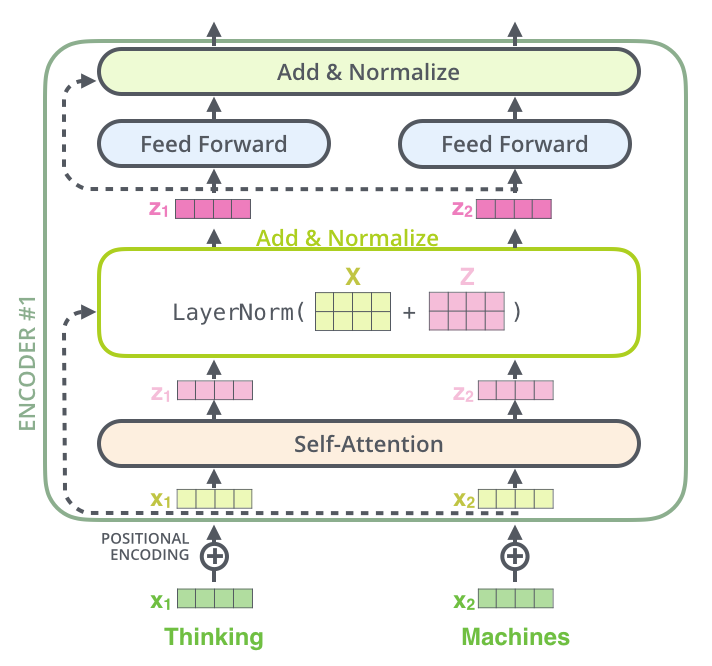
输入是原始词表中词的 。接着进行Input Embedding,把词 转换成分布式的表示。在语言模型中词的顺序还是很重要的,因此Transformer加入了Positional Encoding,也就是加入了词的位置信息。encoder的输入是Input Embedding 加上对应位置的Positional Encoding。
Input Embedding 加上对应位置的Positional Encoding作为encoder的输入,首先会经过Multi-Head Attention,学习输入中词与词之间的相关性。接着是Add & Norm层,Add残差的方式对不同的输出相加,是借鉴CV中的残差网络思想解决梯度消失问题;Norm用的是Layer Norm。然后进行Feed Forward的前向计算,这一层就是全连接的神经网络。最后再接一层Add & Norm,防止梯度消失。
3.2 Decoder部分
通过encoder部分已经获得了所有输入的信息,把这些信息当作decoder后面Multi-Head Attention的输入,也就是self-attention中的 、 来自encoder部分输出的特征, 来自decoder部分的输入。
decoder之前解码出的单词当作本次decoder的输入,也是通过Output Embedding 加上对应位置的Positional Encoding输入到Masked Multi-Head Attention,再经过Add & Norm层,这里还把decoder输入和Masked Multi-Head Attention输出做了残差连接,最后得到的输出就是我们上面提到的 了。
把encoder部分获得的所有输入的信息和decoder前半部分得到的输入信息,一同送到后面这个Multi-Head Attention中,它学习哪些输入信息和之前输出信息的特征更有利于解码,最后还经过了Add & Norm层、Feed Forward层和Add & Norm层,得到了decoder的最终输出。
解码这里要特别注意一下,编码可以并行计算,一次性全部encoding出来,但是解码不是一次把所有序列解出来的,而是像RNN一样一个一个解出来的,因为要用前几个位置单词的结果当作self-attention的query。
3.3 Linear 和 Softmax
拿到decoder的输出做一个线性变换,最后通过一个 计算对应位置的输出词的概率。Transformer本次的输出当作下一步decoder的输入。
关于Transformer更详细的内容,可以参考我之前写的一篇文章:《Self-Attention与Transformer》
面试题:为什么NLP中的模型一般使用Layer Norm,而不是Batch Norm?
回答:
-
在CV中,深度网络中一般会嵌入批归一化(BatchNorm,BN)单元,比如ResNet;而NLP中,则往往向深度网络中插入层归一化(LayerNorm,LN)单元,比如Transformer。为什么在归一化问题上会有分歧呢?一个最直接的理由就是,BN用在NLP任务里实在太差了(相比LN),此外,BN还难以直接用在RNN中,而RNN是前一个NLP时代的最流行模型。虽然有大量的实验观测,表明NLP任务里普遍BN比LN差太多,但是迄今为止,依然没有一个非常严谨的理论来证明LN相比BN在NLP任务里的优越性。 -
基于我阅读过的文献,我个人认为:BatchNorm就是通过对batch size这个维度归一化来让分布稳定下来,有助于训练深度神经网络,是因为它可以让loss曲面变得更加平滑。LayerNorm则是通过对Hidden size这个维度归一化来让某层的分布稳定,主要作用是在训练初期缓解梯度消失和爆炸的问题,提升稳定性。 -
关于BatchNorm为什么在NLP问题上不work和LayerNorm在NLP问题上work的讨论,我强烈推荐大家阅读这篇文章 《LayerNorm是Transformer的最优解吗?》
4. BERT模型
BERT的全称是Bidirectional Encoder Representation from Transformers,模型是基于Transformer中的Encoder并加上双向的结构,因此一定要熟练掌握Transformer的Encoder。BERT模型的主要创新点都在pre-train方法上,即用了Masked Language Model和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
在用Masked Language Model方法训练BERT的时候,随机把语料库中15%的单词做Mask操作。对于这15%的单词做Mask操作分为三种情况:80%的单词直接用[Mask]替换、10%的单词直接替换成另一个新的单词、10%的单词保持不变。
因为涉及到Question Answering (QA) 和 Natural Language Inference (NLI)之类的任务,增加了Next Sentence Prediction预训练任务,目的是让模型理解两个句子之间的联系。与Masked Language Model任务相比,Next Sentence Prediction更简单些,训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,BERT模型预测B是不是A的下一句。
由于注意力计算开销是输入序列长度的平方,较长的序列会影响训练速度,为了加快实验中的预训练速度,所以90%的steps都用序列长度为128进行预训练,余下10%的steps预训练为512长度的输入。
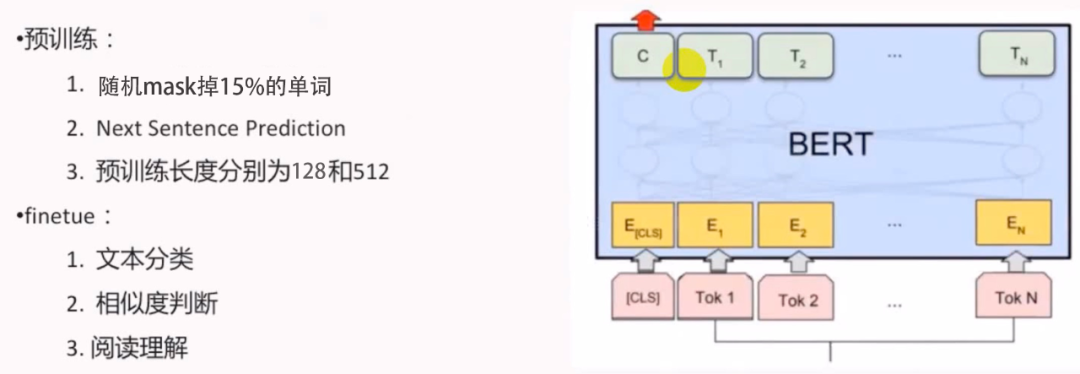
BERT预训练之后,会保存它的Embedding table和 层Transformer权重(BERT-BASE)或 层Transformer权重(BERT-LARGE)。使用预训练好的BERT模型可以对下游任务进行Fine-tuning,比如:文本分类、相似度判断、阅读理解等。
5. BERT模型在实际场景的应用
BERT模型在现实中的应用:
-
情感分类:通过用户对商品评价来对商品质量问题进行分析,比如是否新鲜、服务问题等; -
意图识别; -
问答匹配; -
槽位提取:BERT后接CRF来做命名实体识别;
6. BERT模型的预训练及其改进


7. BERT的Fine-tuning不同训练方式及常见的改进策略
7.1 Fine-tuning的不同训练方式

7.2 BERT的Fine-tuning中常见的改进策略
如果机器不足、预料不足,一般都会直接考虑用原始的BERT、Roberta、XLnet等在下游任务中微调,这样我们就不能在预训练阶段进行改进,只能在Fine-tuning阶段进行改进。改进方案如下图所示:

7.3 BERT在实践中的trick
-
筛选训练数据,剔除过短或者过长的数据; -
尝试bert+conv, bert+conv+avg_max_pooling, bert_last_layer_concat等方式; -
针对本场景数据,进行少步数的进一步预训练;
8. 总结
BERT模型作为当今NLP应用的大杀器,具有易于使用、稳定性强等诸多优点。本文深入了解BERT的原理,如何做到BERT的预训练改进以及Fine-tuning中所涉及到的常见改进策略。另外,本文也讲述了BERT模型在实际场景中的应用及在实践中的一些tricks。
9. Reference
本文部分内容是Microstrong在观看徐路在B站上讲解的视频《BERT模型精讲》的笔记,地址:https://www.bilibili.com/video/BV1M5411x7FZ?from=search&seid=7509511278753452725 ,剩余部分是Microstrong从BERT论文及下列参考文章中整理而来。
【1】Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
【2】BERT模型精讲,地址:https://www.bilibili.com/video/BV1M5411x7FZ?from=search&seid=7509511278753452725
【3】LayerNorm是Transformer的最优解吗?,地址:https://mp.weixin.qq.com/s/W4gI9SWJm3MjbQHYgvFKbg
【4】The Illustrated Transformer,地址:https://jalammar.github.io/illustrated-transformer/
【5】一文看懂AutoEncoder模型演进图谱 - 深度的文章 - 知乎 https://zhuanlan.zhihu.com/p/68903857
【6】【NLP】Google BERT详解 - 李如的文章 - 知乎 https://zhuanlan.zhihu.com/p/46652512
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



