清华IEEE论文:利用新型训练方法,帮自动驾驶决策摆脱「路侧干扰」
编译 / Aaron 、曹锦
近日,来自清华大学的学者提出了一套基于自动编码器实现的新训练方法,使其能够忽略输入图像中的无关特征,同时保留相关特征。与现有的端到端提取方法相比,该方法只需要图像级标签,降低了标记成本。

研究者发现,通过训练卷积神经网络(CNNs)模型来处理编码器的输出,并产生一个转向角来控制车辆,可验证了该方法的有效性。整个端到端的自动驾驶方法可以忽略不相关特征的影响,即使这些特征在训练卷积神经网络的时候也不存在。
基于卷积神经网络的自动编码器
论文作者列出了相应算法的主要思想和基本过程:该系统由自动编码器和自动编码器组成如图1所示。来自前置摄像头的图像作为输入提供给自动编码器。自动编码器由编码器和解码器组成,编码器的输出作为CNN的输入,CNN计算并输出转向角度来控制车辆。
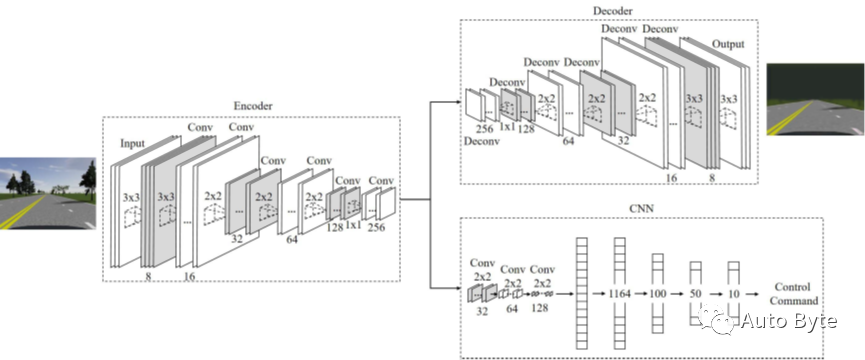
(图1、完整系统的示意图,该系统包含一个自动编码器来消除图像中的无关特征,以及一个产生控制命令的CNN)
自动编码器是一种人工神经网络,它旨在以无监督的方式学习高效的数据编码。它学习如何有效地对数据进行编码,并将数据从编码后的表示重构为尽可能接近原始数据的表示。自编码器的两个主要应用是降维和信息检索。虽然降维与我们的任务相似,但由于它们都需要从输入中提取有用的特征,所以通常不会去除特征。
最近,自动编码器被证明可应用于不同的任务,如图像处理方面,自动编码器可以达成图像压缩和图像去噪,然而这些任务对精准的路侧物体识别意义不大。
在图形压缩工作中,图像被压缩以降低存储或传输的成本;在图像去噪任务中,噪声图像被传输到原始图像中。噪声图像作为输入,原始图像作为标签来训练网络。另外,噪声图像应该与原始图像完全相同。
从文中的例子来看,如果将不相关的物体作为噪声处理,那么图像去噪的方法似乎可以用来提取相关的特征。但是,在实际驾驶场景中,天空、树木等不相关的物体是无法去除的,所以这种方法并不可行。
Auto-Encoder如何配合CNNs
研究者提出,算法的目的是在保留所有相关特征的同时,从图像中去除所有与决策无关的特征。为了降低标签的成本,最好只使用图像级标签训练网络。
同时,为了满足端到端方法的定义,特征提取过程的输出应该具有隐含意义。与CNNs相比,自动编码器在这方面是一个更好的选择:它不可能直接理解编码器的输出,而是将其转换为原始输入,因为它包含了和输入一样多的信息。
解码器的输出和原始输入之间总是有一些错误。换句话说,总有一些信息丢失。在理想情况下,算法的目标是确保任何丢失的信息只包含不相关的特征,同时保留想要保留的特征。为了实现这一点,网络需要被教导哪些类型的特征应该保留,哪些应该消除。然后,经过多次重复训练过程,网络就具备了从输入中提取所需特征的能力。
那么,CNNs在其中的作用又是什么呢?我们系统的CNN体系结构如图1所示,它包括三个卷积层和四个全连通层,其中最后一层输出控制命令(即方向盘角度)。
训练CNN时,自动编码器的参数保持不变。在良好场景的专业驾驶测试过程中,训练图像会包含很多正常状态的图像。不过,一旦车辆偏离了当前车道的中心,CNN就可能无法做出正确的决定。
为了避免该问题,研究者采用如图2所示的在线训练方法:由网络控制车辆,同时由专家提供控制命令。训练过程中获取的图像将作为训练数据,而专家给出的命令作为标签,这些数据随后被用来训练网络。
由于网络是随机初始化的,在训练的早期,车辆经常处于异常状态,避免了正常图像过多的问题。
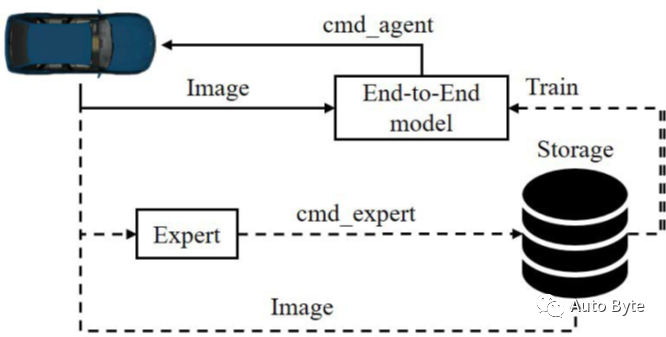
(图2、CNN培训过程。实线表示用于控制车辆的信息流,虚线表示用于训练模型的信息流)
利用仿真实现的模拟器和
数据集描述(Dataset Description)
展示了仿真模拟器和数据收集过程,并将开发的系统与具有相同网络结构的基线模型的性能进行了比较。
仿真环境采用PreScan构建,PreScan是智能车辆系统开发的仿真环境,用户可以在其中设计逼真的交通场景。一旦特定的交通场景完成,该工具可以自动生成Simulink模型,用于测试自动驾驶算法。
为此,研究者制定了以下四个测试计划。
1)测试方案一:算法在场景1-1进行训练,在场景1-3和场景1-4进行测试。
2)测试方案二:算法在场景1-2进行训练,在场景1-3和场景1-4进行测试。
3)测试方案三:算法在场景2-1进行训练,在场景2-3和场景2-4进行测试。
4)测试方案四:算法在场景2-2进行训练,在场景2-3和场景2-4进行测试。
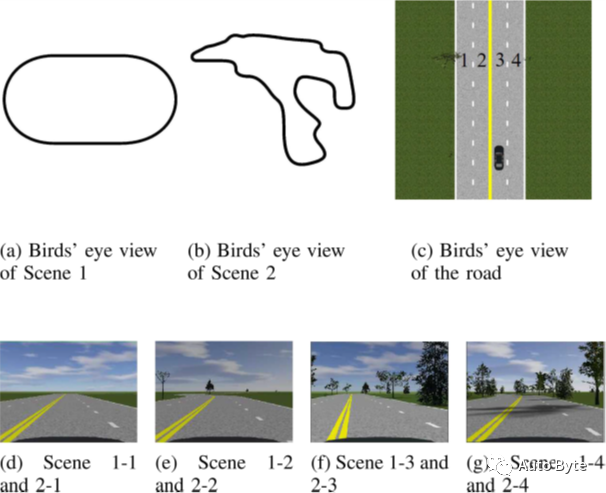
(图3、内置PreScan的场景)
自动解码器训练过程需要收集正、负样本。在所构建的场景中,道路和车道标志是影响驾驶指令的主要因素,而树木和天空则无关紧要。研究者先在模拟环境中随机拍摄图片,然后将每个图像分配给一个数据集,如下所示。
如果图像主要由道路特征组成,则将其归类为阳性样本。另一方面,如果图像主要由树木或天空特征组成,则将其归类为负样本。否则,如果相关特征和不相关特征的比例几乎相同,则丢弃图像。正、负样本集如图4所示。
在训练CNN的方法中,用于训练目的的数据是在训练过程中收集的。前置摄像头拍摄的输入图像尺寸为240 × 320 × 3。由于任务是保持在车道上,标签即转向角度可以通过跟踪算法来确定,该算法可以控制车辆沿着车道的中心线行驶,且该跟踪算法由PreScan环境提供。

(图4、部分数据集用于训练自动编码器 )
综合看来,该论文提出了一种新的训练方法,即允许自动编码器从输入图像中提取有用的特征,并将其应用到端到端自动驾驶方法中,以忽略不相关的路边目标。
从中我们可以得到一些结论:首先,在训练自动编码器时采用正负交替采样,编码器可学会从输入图像中去除那些不相关的特征,从而保证输出特征映射只包含相关特征。在解码器输出的图像中,不相关的物体,如树木和天空,实际上是无法区分的,而道路和车道标记是清晰的。
同时,文中所提出的训练方法仅依赖图像级标记即可对自动编码器进行训练。与现有的端到端多任务自动驾驶方法相比,该方法降低了标签成本。
另外,使用自动编码器与CNN组成的端到端自动驾驶方法,即使训练数据中几乎没有不相关的物体,也不会受到路边不相关物体的影响。由此提炼出的模型和基线模型不容易受到阴影的影响。当阳光角度设置为45°,提出的模型仍然提供良好的性能,而基线模型无法保持车辆在车道上。
这种方法目前的一个限制是「简单的场景」。为了扩大应用范围,可以有不同的无关对象,如建筑物和周围的车辆。该模型中的CNN可以用强化学习算法代替来处理动态场景。也可以考虑有限范围的道路测试。此外,为了处理如此复杂的图像,决策网络的架构也将被扩展。
原文链接:
Wang, T., Luo, Y., Liu, J., Chen, R., & Li, K. (2022). End-to-end self-driving approach independent of irrelevant roadside objects with auto-encoder. IEEE Transactions on Intelligent Transportation Systems, 23(1), 641-650. doi:http://dx.doi.org/10.1109/TITS.2020.3018473
主要作者信息:
Yugong Luo(IEEE成员)——分别在1996年和1999年分别获得重庆大学科技学士和科学硕士学位。2003年获得清华大学博士学位。现任清华大学汽车与交通学院教授。他撰写了70多篇期刊文章,拥有31项专利。主要研究方向为智能互联电动汽车动力学与控制、汽车噪声控制。
Tinghan Wang——在2016年获得了清华大学的科技学士学位,目前正在攻读博士学位。他的研究兴趣包括基于深度神经网络的端到端自动驾驶和深度强化学习。
Jinxin Liu——于2017年获得合肥工业大学理工科学士学位。他目前在攻读清华大学博士学位。主要研究方向为汽车意图识别和行为规划。
关于Auto Byte
Auto Byte 为机器之心推出的汽车技术垂直媒体,关注自动驾驶、新能源、芯片、软件、汽车制造和智能交通等方向的前沿研究与技术应用,透过技术以洞察产品、公司和行业,帮助汽车领域专业从业者和相关用户了解技术发展与产业趋势。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。


