DeepMind新研究:可微归纳逻辑编程,融汇神经网络与逻辑编程之长(下)
随着深度学习的兴起,神经网络的尺寸也伴随着表达力的提升而提升。随着神经网络复杂度的增加,过拟合问题也变得越来越普遍。虽然正则化可以缓解过拟合问题,但解决过拟合问题最常用的方法还是使用大量训练数据,希望足够多的训练数据的分布可以逼近测试数据的分布。然而,大量数据并不总是那么容易得到。相比神经网络,归纳逻辑编程可以说是极度数据高效了。然而,归纳逻辑编程对噪声和标注错误的数据极为敏感,也无法应用于非符号领域的问题,因此,归纳逻辑编程适用的领域比神经网络要狭窄得多。DeepMind的研究科学家Richard Evans和Edward Grefenstette提出了可微归纳逻辑编程∂ILP,结合了神经网络和归纳逻辑编程的优势。
在上篇中,我们介绍了∂ILP如何将归纳推理问题转化为可满足性问题,以及∂ILP在标准ILP任务上的表现。在这篇文章中,我们将介绍∂ILP的可微架构,以及∂ILP对错误标注数据的鲁棒性和如何应用∂ILP到非符号数据。除此以外,我们还将讨论∂ILP与相关工作的异同,以及∂ILP的缺陷及改进空间。
模型架构
上篇提到研究人员所采取的模型采用的是自顶向下方法,也就是根据语言生成程序,然后在正例和反例上进行测试。因此,给定一个ILP问题(L, B, P, N),一个程序模板Π,模型将基于L、B、Π生成一组子句,然后测试正例和反例。
那么,从机器学习的视角而言,这个模型很像是一个二元分类器,学习基础原子a的真值(为真时属于正例,为假时属于反例)。
c(a, L, B, Π) -> {False, True}
然后,为了便于使用随机梯度下降之类的方法进行训练,研究人员将二元分类器的输出从离散的布尔值改成了[0, 1]实数区间。同理,研究人员将上篇中提到的表明程序实际使用的子句的离散的布尔值变量改成了连续的权重子句的概率分布(不妨用W表示)。相应地,模型学习的也是基础原子a的条件概率(不妨用λ表示)。
由此,研究人员构建了一个可微的模型:
p(λ | a, W, Π, L, B)
相应地,正例和反例可以表示为标注过的原子数据集:
Λ = {(r,1) | r ∈ P} ∪ {(r, 0) | r ∈ N}
损失函数为分类问题常用的交叉熵:
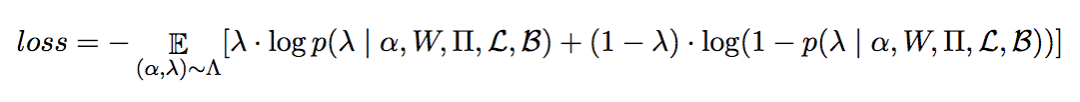
前面我们提到了模型要学习条件概率:
p(λ | a, W, Π, L, B)
那么,这个概率具体是如何计算的呢?
研究人员使用了4个辅助函数进行计算:
p(λ | a, W, Π, L, B) = f_extract(
f_infer(f_convert(B),
f_generate(Π, L),
W,
T
),
a)
用图形表示更容易理解:
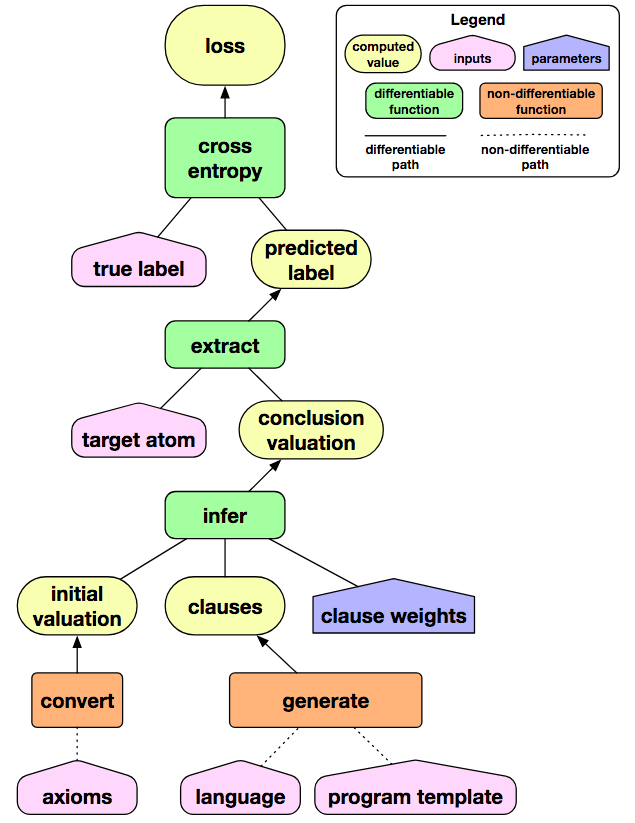
上图中,绿框中的函数为可微函数,实线表示可微路径,虚线表示不可微路径。我们看到,虽然generate和convert为不可微函数,但是从子句权重到最终的损失函数,模型是处处可微的。也就是说,训练模型以自动得到权重的过程,都是可微的。
以上我们概览了整个模型的架构,下面我们详细解释下权重是如何表示的。
规则权重
W为由矩阵组成的权重集合{W1, ..., W|P_i|},每个矩阵对应于一个内涵谓词p ∈ Pi,即(|cl(τp1)|, |cl(τp2,k)|)。不同的矩阵的大小通常不一样,因为不同的规则模板生成的子句集合的大小不同。
Wp[j,k]表示系统有多么相信子句对(Cp1,j, Cp2,k)是定义内涵谓词p的正确方式。
研究人员使用softmax将权重矩阵Wp[j,k]转换为概率分布:
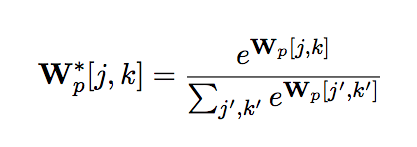
相应地,Wp*[j,k]表示(Cp1,j, Cp2,k)为定义内涵谓词p的正确方式的概率。
正向链
∂ILP的核心是给定子句c,可以自动生成其正向链函数Fc.
下面我们结合一个例子,解释如何生成(计算)这个正向链函数Fc.
给定P = {p, q, r},C = {a, b},将C中的元素代入P,通过排列组合,我们可以得到对应的基础原子集合G:

假定子句c为:
r(X,Y) <- p(X,Z), q(Z,Y)
我们可以定义一个集合Xc = {xk}nk=1,表示满足子句c的所有基础原子对的集合。
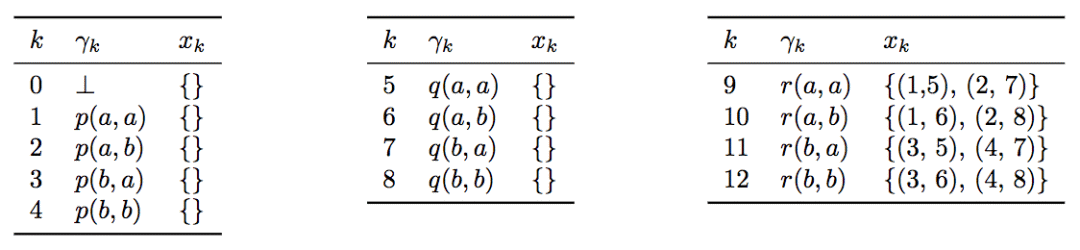
比如,k=9时,xk为(1,5)和(2,7),换言之:
r(a,a) <- p(a,a), q(a,a)
r(a,a) <- p(a,b), q(b,a)
Xc为基础原子对的集合(xk)的集合,因此,可以转化为一个三维tensor:X ∈ Nnxwx2。其中,w为1...n间的k中最大的基础原子对数。w取决于规则模板中v(变量)的数目,又因为每个变量可以接受|C|个常量,因此w = |C|v。最后,研究人员使用(0,0)补齐,(0,0)对应于(⊥,⊥)。
在我们的例子中,X为:
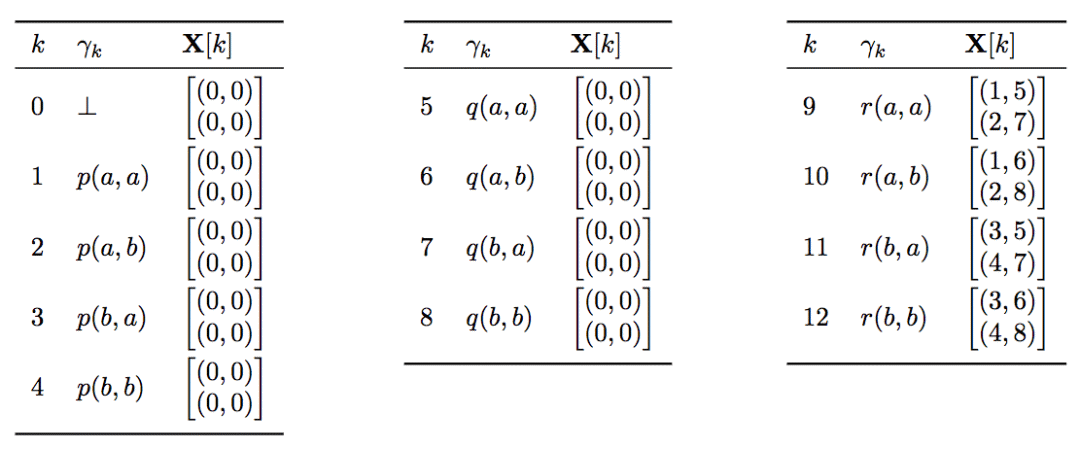
最终我们将通过基础原子生成子句,因此再将X分成X1和X2,分别对应基础原子对中的第一个原子和第二个原子。
然后,将其拼装起来:
Y1 = gather2(a, X1)
将上式中的X1替换为X2,可以得到Y2的定义。
其中,gather2的定义为:
gather2(x,y)[i,j] = x[y[i,j]]
然后,模糊合取(fuzzy conjunction)Y1和Y2:
Z = Y1 ⊙ Y2
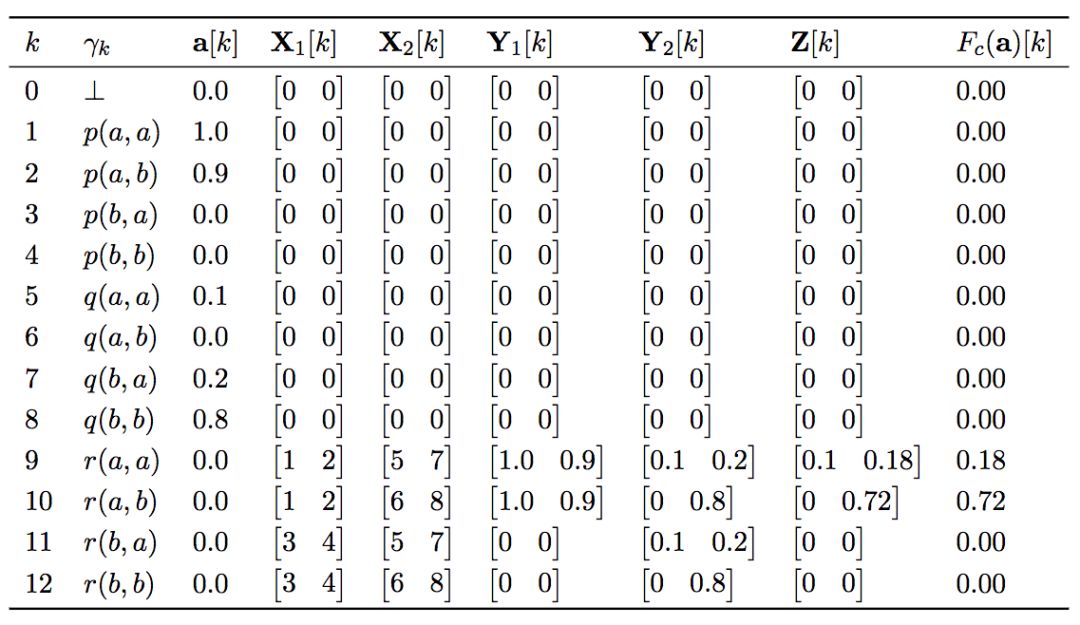
Fc(a)选取Z中模糊真值的最大值,即Fc(a) = a',其中a'[k] = max(Z[k,:])
回到先前的例子,下表显示了Fc(a)的值:
上面的模糊合取,研究人员使用了像素级乘积(element-wise product)。事实上,有很多表示模糊合取的方式。为了保证高度的概括性,模糊合取运算需要满足t-norm:
交换律:
x * y = y * x结合律:
(x * y) * z = x * (y * z)单调性(i): 若x1 ≤ x2,则x1y ≤ x2y
单调性(ii): 若y1 ≤ x]y2,则xy1 ≤ xy2
单位元(i):
x * 1 = x单位元(ii):
x * 0 = 0
满足t-norm的运算有:
Godel t-norm min(x,y)
Lukasiewic t-norm max(0,x+y-1)
乘积 t-norm x · y
研究人员选取乘积 t-norm的原因是,当损失函数反向传播至子句权重时,梯度均匀地在Y1和Y2间流动。而使用Godel t-norm时,若Y1 > Y2,没有梯度信息传递给Y1。类似地,使用Lukasiewic t-norm时,若Y1 + Y2 < 1,Y1和Y2均收不到梯度信息。
推理
将前向链函数分别应用于子句集合Cp1,j和Cp2,k,并取元素级最大值(element-wise max):
Gpj,k(a) = x
其中,
x[i] = max(Fp1,j(a)[i],Fp2,k(a)[i])
然后我们可以定义t时步推断后的结果为:
ctp,j,k = Gpj,k(at)
t=0时的初始值a0为背景公理:
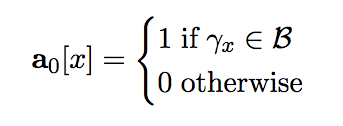
ctp,j,k的加权平均(基于softmax)为:
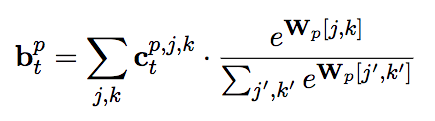
由此,可以定义两个时步间的关系,即基于当前推断计算下一步推断:
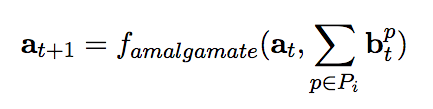
其中,famalgamate的定义,研究人员首先尝试直接使用最大值函数:
famalgamate(x,y) = max(x,y)
但研究人员发现,这一定义在训练时会影响梯度流程,因此研究人员最后使用了概率和(probabilistic sum):x + y - x * y
内存占用
∂ILP属于内存密集模型。
atp,j,k和ctp,j,k占用了大量的内存。它们共需存储如下数目的浮点数:
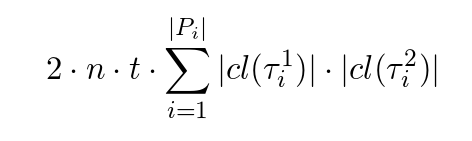
中间向量Y1、Y2和Z的计算也需要大量内存:
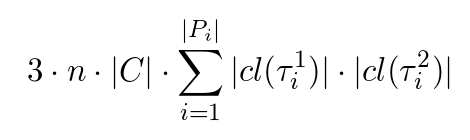
之所以占用这么多内存,主要原因是模型为每对规则模板分配了权重矩阵(|cl(τp1)|, |cl(τp2,k)|)。看起来,这么做引入了不必要的复杂性,完全可以为单独的规则模板分配权重,而不用存储这么多的规则模板组合对应的权重。这样,模型大大简化了,内存占用也大大下降了。
事实上,研究人员起初就是这么做的。为每个模板生成的字句cl(τ)分配了一个权重矩阵。相应地:
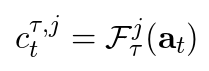
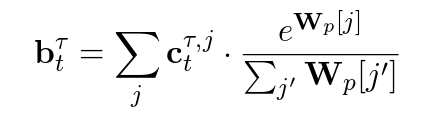
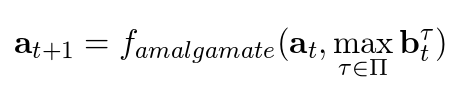
然而,研究人员发现,在较困难的任务中,这一简化模型无法摆脱局部极小值。
简化模型的问题在于,如果有两个规则模板定义了相同的内涵谓词,组合这两条规则时,会损失信息。这会影响系统学习涉及多子句的程序。
实现细节
框架
两位研究人员均来自Google DeepMind,顺理成章地使用TensorFlow实现了模型。
超参数
研究人员首先使用网格搜索查找一些“合理的”超参数。“合理”的含义是,可以基于至少5%的随机初始化的权重解决10个特定的问题。研究人员尝试了一些优化算法:随机梯度下降、Adam、AdaDelta、RMSProp,也尝试了不同的学习率{0.5, 0.2, 0.1, 0.05, 0.01, 0.001}。权重基于均值为0、标准差在0到2之间(均值为固定值,标准差为超参数)的正态分布随机初始化。每个超参数配置,研究人员在10个特定问题上测试了20次,每次使用不同的随机数种子。
研究人员发现RMSProp和Adam都能给出合理的结果。当学习率处于0.5到0.01之间时,RMSProp都能成功。
最终,研究人员选定了如下超参数配置:RMSProp,学习率0.5,初始权重取样自N(0, 1)的正态分布。
试验方法
基于上述超参数,研究人员训练了6000步。在训练中,使用了多个(B, P, N)三元组。在训练的每一步中,模型首先从其中一个三元组取样,接着从P ∪ N中取样一个mini-batch。提供不同的三元组,帮助系统正确地正确地进行概括。
注意,取样mini-batch时,并没有使用整个正例、反例集合,而是在每一步随机选取一个子集,从子集中取样mini-batch。这给过程增加了随机性,有助于避免陷入局部极小值。
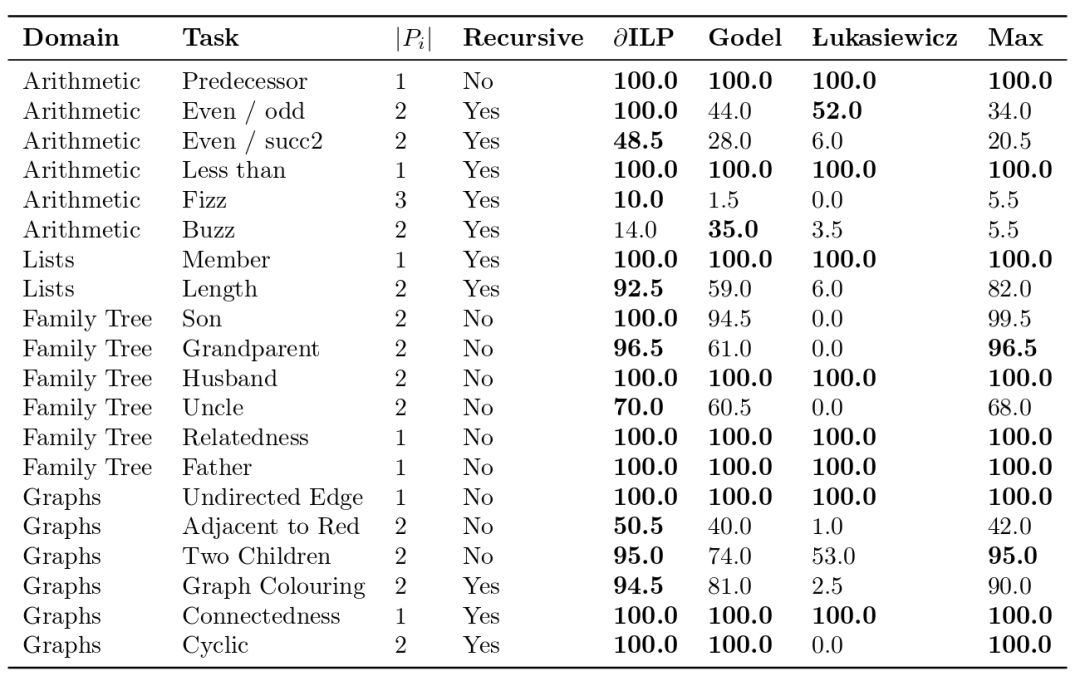
消融测试
研究人员在三类任务上试验了∂ILP:
标准的ILP问题(基于离散、无误的输入)
错误标注的问题
模糊问题
其中,标注ILP问题上的测试结果,我们已经在上篇介绍过了。
此外,为了验证∂ILP的有效性,研究人员还进行了一系列消融测试:
错误标注问题
研究人员在训练数据(正例、反例)中掺杂了错误标注的信息,以考验∂ILP对抗噪声的能力。
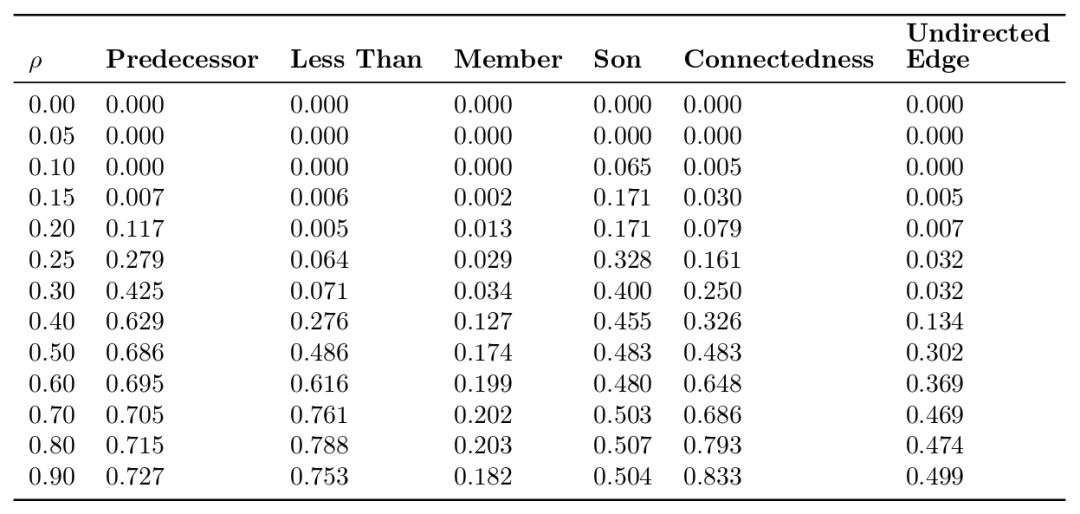
p为错误标注的信息比例
从上表我们可以看到,在有10%的错误标注信息的情况下,∂ILP仍然为6个任务中的5个找到了正确解答。在一些任务中,即使错误标注率高达20%或30%,∂ILP仍能找到正确解答。
从上表我们还可以看到,随着错误标注比例的升高,∂ILP的表现平稳地下降。这和传统的ILP系统大不相同。在传统的ILP系统中,单个错误标注的训练样本就足以让测试误差剧烈升高。从下图能更清楚地看到这一点。
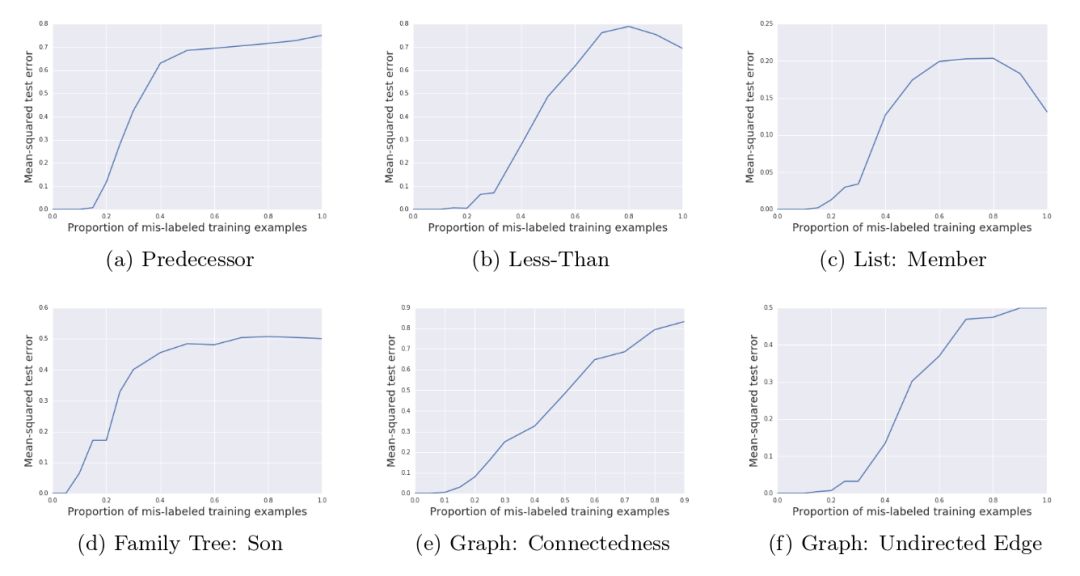
下图显示了随着错误标注比例的升高,规则的熵值变化的情况。softmax后的规则权重,表示子句的概率分布。该概率分布的熵值衡量了所学规则的模糊程度。注意,在某些情形下,错误标注比例升高的一定程度后,熵值反而下降了。这是因为,有时候,当数据全部都错误标注的时候,相比有一半数据错误标注的情况,反而更容易找到清晰的规则。例如,假设我们学习自然数上的even(偶数)谓词,然后将所有正例和反例对调,那我们将学习到odd(奇数)谓词的规则,这条错误的规则的熵值为零。
处理模糊数据
在上篇中,我们介绍了一个自然数上even(偶数)/odd(奇数)谓词的例子。现在,我们讨论一个类似的例子,只不过接受的输入不再是符号(数字),而是像素图像(MNIST数据集中的图像)。
和上篇的例子一样,背景知识仍然是基本的算术(只不过为了简化这个例子,这里只考虑0-5的情形):
B = {zero(0)} ∪ {succ(n,n+1) | n } ∈ {0, ..., 4}
这一任务的语言模板为:
Pe: {zero/1, succ/2, image/1}
Pi: {target/0, pred/1, pred2/1}
C = {0, ..., 5}
我们看到,这个语言模板和原本的语言模版类似,不同之处主要为:
C的范围限制为0至5,如前所述,这是为了简化这个例子。
target谓词由单元谓词变为零元谓词,当前查看的图像表示偶数时,target为真。
image谓词表示图像的概率分布。
∂ILP找到的一个解答为:
target() <- image(X), pred1(X)
pred1(X) <- zero(X)
pred1(X) <- succ(Y,X), pred2(Y)
pred2(Y) <- succ(Y,X), pred1(Y)
其中,第一条规则的意思是“当前图像表示数值X,且X满足pred1时,target谓词为真”。
当然,为了处理像素图像,需要对∂ILP进行一些改造。研究人员在∂ILP的架构中加入了一个在MNIST上预训练过的卷积神经网络。像素图像传入预训练过的卷积神经网络,通过softmax将卷积神经网络的输出转化为原子的概率分布。例如,假设图像表示数字“2”,最终得到的概率分布可能是:

加入卷积神经网络后,整个网络架构如下图所示:
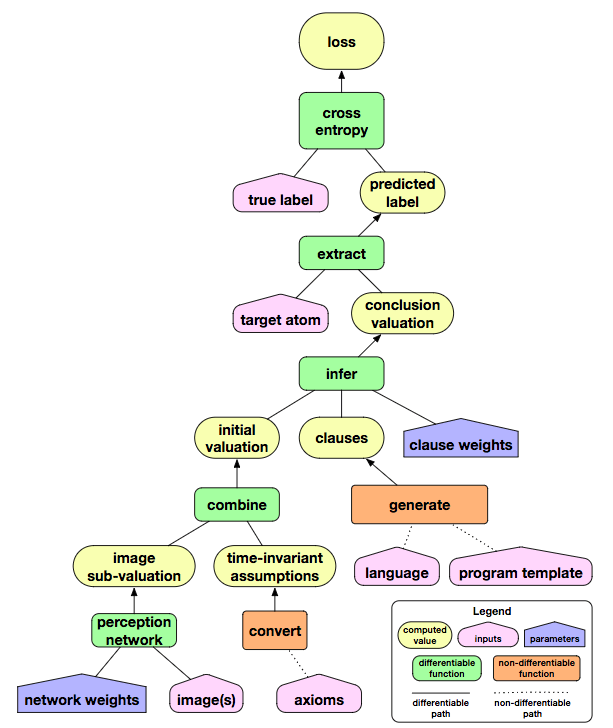
上面的网络架构仍有改进的空间:
加入的卷积神经网络是预先训练好的,而不是和整个网络架构一起训练的。
研究人员使用了表示“当前图像代表数值X”的概率分布,因为研究人员知道图像代表一个0-5之间的数字。在理想情况下,这应该是由网络架构自行学习的,并且,学习到什么程度应该取决于当前任务。比如,假设任务是学习zero谓词(判断当前图像是否为零),那么,模型并不需要学习清楚1-4之间的概率分布,对于模型而言,1-4之间的界限应该是模糊的(相反,与0的界限则是清晰的)。
相关研究
相比prolog的模式声明(mode declaration),和metagol的元规则(meta rules),∂ILP的规则目标的限制要少得多。
为了克服传统ILP的缺陷,Garcez等在2015年尝试基于神经网络框架实现ILP系统,但是这一工作只在有限的概念验证性的例子上起效,未能成功应用于实际问题。
深度学习社区也尝试将ILP生成的符号程序表示改为隐式的基于网络权重分布的图灵机之类的底层计算模型。有不少工作基于这一思路,经此改造的ILP能够应对噪声和模糊数据。然而,和传统ILP不同,由于生成的计算模型过于底层,因此难以查探,不具可读性,而且概括性也很差,当测试数据包含很多训练数据中未见的新数据时,模型的表现剧烈下降。例如,假设训练数据长度为10,测试数据长度为20,这样的模型可能表现不错。但如果测试数据长度为100,模型的表现就急剧下降。
当然,也有一些工作采用了和∂ILP相近的思路。
Holldoble等在1999年证明,对任何特定类型的逻辑程序,存在一个循环神经网络,能够以任意所需精度逼近原逻辑程序。然而,这一工作仅仅是理论上的证明,并没有给出为具体程序构建循环神经网络的方法。(“Approximating the Semantics of Logic Programs by Recurrent Neural Networks”)
基于以上工作,Bader等在1999年给出了构造方法。(“Connectionist Model Generation: A First-Order Approach”)
该方法和∂ILP的不同点为:
Bader等考虑的是无环逻辑程序,而∂IL考虑的是Datalog逻辑程序。
由于使用网络的权重表达程序,因此难以查探和理解。
Bader等的网络的隐藏状态编码一个特定的基础原子集合,∂ILP中的隐藏状态编码重复应用的通用规则的相对权重。
Serafini和Garcez在2016年提出了“实逻辑”,将一阶逻辑中的布尔值替换为[0, 1]之间的实数值。这一做法与∂ILP类似。不过,如上篇所属,∂ILP能生成一阶逻辑无法表达的问题的解答。当然,“实逻辑”不像∂ILP一样限定了确定性Datalog子句。(“Logic Tensor Networks: Deep Learning and Logical Reasoning from Data and Knowledge”)
Bader、Garcez、Hitzler在2005年使用fibred神经网络表示逻辑程序。fibred神经网络可以表示递归程序,甚至互递归程序。然而,这一系统无法表示自由变量。(“Computing First-Order Logic Programs by Fibring Artificial Neural Networks”)
Kersting等在2006年改进了隐马尔科夫模型(HMM),提出了逻辑隐马尔科夫模型(LOHMM),该模型可以编码一阶表示。和∂ILP类似,LOHMM基于条件概率,可以应对噪声问题。和∂ILP不同,LOHMM基于原子序列进行学习,LOHMM的规则体只包含一个原子。(“Logical Hidden Markov Models”)
De Raedt和Kersting在2008年提出了一个非常概括的ILP形式化表示,基于覆盖(cover)关系(∂ILP的蕴涵关系属于覆盖关系中的一种)。不过,∂ILP可以学习递归子句,而这一系统无法学习递归子句。(“Probabilistic Inductive Logic Programming”)
Guillame-Bert、Broda、Garcez在2010年发表的论文“First-order Logic Learning in Artificial Neural Networks”使用了和∂ILP在很多方面相似的方法:同样限定确定性子句,使用神经网络架构实现正向链。和∂ILP不同,他们的方法没有Datalog限制(可以使用函数符号),然而,只能学习单个子句,也不支持递归子句。
Fran ̧ca、Zaverucha、Garcez在2014年提出的CILP++系统没有∂ILP的内存占用问题,但无法学习递归子句。总体而言,CILP++的设计方向与∂ILP不同,CILP++致力于学习更多数据,而∂ILP致力于学习更复杂的程序。(“Fast Relational Learning Using Bottom Clause Propositionalization with Artificial Neural Networks”)
Rockt ̈aschel和Riede在2016年提出了基于反向链的可微神经网络架构(∂ILP基于正向链)。另外,该系统的规则模板比∂ILP的限制更多。和∂ILP类似,该系统同样限定了Datalog子句。(“Learning Knowledge Base Inference with Neural Theorem Provers”)
Rockt ̈aschel和Riede在2016年提出了基于反向链的可微神经网络架构(∂ILP基于正向链)。另外,该系统的规则模板比∂ILP的限制更多。和∂ILP类似,该系统同样限定了Datalog子句。(“Learning Knowledge Base Inference with Neural Theorem Provers”)
Yang等在2016年提出了正向链的可微实现,和∂ILP不同,该实现学习单独子句,也不支持递归子句。(“A Differentiable Approach to Inductive Logic Programming”)
Eisner等在2004年提出了用于自然语言处理系统的Dyna语言,一个声明式一阶语言。和∂ILP类似,Dyna基于正向链推理计算概率。(“Dyna: A Declarative Language for Implementing Dynamic Programs”)
缺陷和改进空间
如前所述,∂ILP的缺陷主要是内存密集。这限制了∂ILP应用于大量数据,也难以应对需要三元以上谓词才能求解的问题。
目前∂ILP需要规则模板才能生成程序。研究人员尝试过使用暴力搜索法避免手工构造规则模板,然而,这牵涉大量运算。研究人员计划在以后使用更巧妙、更节省算力的解决方案。
另外,“处理模糊数据”一节已经提过,应用于模糊数据的∂ILP,可以改进的方面有:卷积神经网络与整个系统一起训练,根据手头的问题决定模糊数据的学习程度。





