深度学习如何提升肺结节良恶性诊断准确率到90%?图玛深维首席科学家给出了答案!

去年5月,在2017年度GPU技术大会(GTC)上,英伟达发布了超级计算机NVIDIA DGX Station。作为针对人工智能开发的GPU工作站,NVIDIA DGX Station的计算能力相当于400颗CPU,而所需功耗不足其1/20,而计算机的尺寸恰好能够整齐地摆放在桌侧。数据科学家可以用它来进行深度神经网络训练、推理与高级分析等计算密集型人工智能探索。
作为致力于将深度学习人工智能技术引入到智能医学诊断的系统开发商,图玛深维采用了DGX Station以及CUDA并行加速来进行神经网络模型的训练,并在此基础上开发出了σ-Discover Lung智能肺结节分析系统。σ-Discover Lung系统能够帮助医生自动检测出肺结节、自动分割病灶、自动测量参数,自动分析结节良恶性、提取影像组学信息、并对肺结节做出随访,大幅度减少结节筛查时间,减少读片工作量,提高结节的检出率,并且提供结节的良恶性定量分析,提高筛查的效果。σ-Discover Lung系统于去年8月发布。去年12月,图玛深维完成软银中国领投的2亿人民币B轮融资。
3月23日起,智东西联合NVIDIA推出「NVIDIA实战营」,共计四期。第一期由图玛深维首席科学家陈韵强和NVIDIA高级系统架构师付庆平作为主讲讲师,分别就《深度学习如何改变医疗影像分析》、《DGX超算平台-驱动人工智能革命》两个主题在智东西旗下「智能医疗」社群进行了系统讲解。目前,「NVIDIA实战营」第二期已经结束。而第三期将于4月13日20点开讲,主题为《智能监控场景下的大规模并行化视频分析方法》,由西安交通大学人工智能和机器人研究所博士陶小语、NVIDIA高级系统架构师易成共同在「智能安防」社群主讲。
本文为陈韵强博士的主讲实录,正文共计4472字,预计7分钟读完。在浏览主讲正文之前,可以思考以下五个问题:
-低剂量胸部扫描是否能识别结节的良恶性?
-传统CAD技术为何不如深度学习?
-深度学习在医学影像分析有哪些应用场景?
-基于多任务的深层神经网络模型如何搭建智能肺结节分析系统?
-深度学习给医疗哪些领域会带来变革?
陈韵强:大家好!很高兴有机会和英伟达的专家一起和大家交流深度学习在智能医疗影像分析方面的应用。先简单介绍下图玛深维医疗科技有限公司(以下简称图玛深维)以及公司在智能医疗领域的产品路线。图玛深维成立于2015年,一直致力于利用深度学习技术来提高智能医疗水平,辅助医生采用更加精确、有效的手段来诊断疾病和确定治疗方案,从而更好地为患者服务。公司发展到今天,已经有一百多名全职雇员,八位医学顾问,公司总部设在北京,并且已经在苏州、上海以及美国圣地亚哥建立了分部。
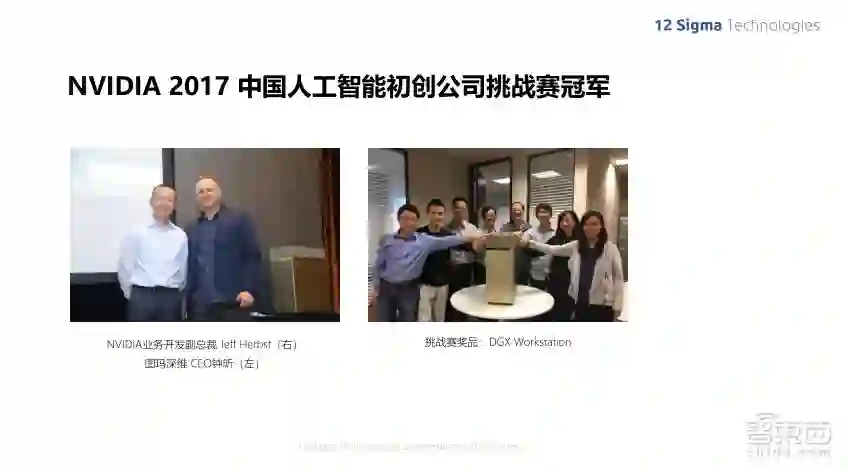
在去年的GTC大会北京站上,图玛深维获得“2017中国人工智能初创公司挑战赛”冠军并获得了价值百万的超级计算机DGX-1大奖。这张照片就是我们在这次挑战赛冠军的奖品——最新的DGX工作站。我们已经将其应用到研发工作中,并且给工作效率带来了非常大的提升。后面我也会做一些关于DGX工作站效率的详细比较,大家可以看一下。

图玛深维目前主要专注于医学影像分析。现代医学影像取得重大进步的一个原因,其实就是基于不同成像设备的巨大发展,比如CT断层成像、核磁共振扫描、三维超声等,都可以在没有创伤或微创的情况下,观察人体内部的细微组织结构,在疾病的早期检测、找到疾病的病因以及病灶位置方面带来了极大的增强,从而可以让医生尽早确定治疗方案。另外,在人体的不同部位,不同疾病的表现方式也都不太一样,检测方法也不一样,因此图玛深维的产品针对不同的成像仪器,涵盖了人体的多个部位,来对一些高发以及高危的疾病进行智能辅助诊断。现在我们着重的是比较高危害的疾病,包括各种恶性的癌症、心血管常见疾病以及脑血管疾病等。
下面我主要以我们公司的肺癌产品为例,来介绍一下公司在智能医疗领域的贡献、智能医疗的重要性和它需要实现的任务及范畴。可以看到,现在世界卫生组织预测21世纪人类第一杀手,就是一些常见的恶性癌症。全球每年大概有700万人死于癌症,而在中国,恶性肿瘤发病率也非常高,每年发病率平均在160万左右,死亡数量也相当高,达到130万,恶性肿瘤在所有的死亡病例里面占了1/5左右,是现代危害非常严重的一种疾病。而肺癌更是恶性肿瘤里面发病率最高的恶性肿瘤之一,其五年生存率仅仅为15%左右。

从上图我们可以看到肺癌在男性发病率里面是最高的,女性群体中乳腺癌是最高的,而其次就是肺癌。因此肺癌在整个恶性肿瘤中是最严重的一种,但是实际上我们也不应该谈癌变色,而是要尽早地发现和治疗,这样才能提高治愈率。
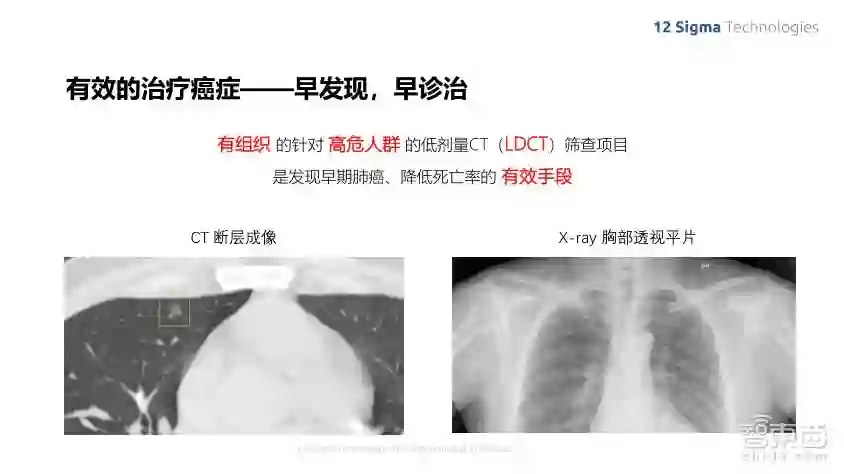
肺癌之所以可怕,是因为它的初期症状非常不明显,很容易被忽略掉,而到了晚期则会发生癌细胞转移,导致治疗非常困难。美国肿瘤协会一系列的研究表明,检测肺部结节是早期发现肺癌的一个非常有效的手段。由于肺部结节肿瘤的尺寸很小,在传统的X-ray胸部透视平片上是很难看到的,而通过低剂量CT进行早期筛查,能够极大地提高早期肺癌的诊断率。
我们知道,CT断层成像是分辨率非常高的三维成像,所以它的数据量也非常大。每个病人基本上都有几百张断片成像,这样就导致了医生诊断非常困难,花的时间也非常多。由于它诊断的困难性,所以有不少人在很早期时就提出来用计算机辅助诊断,利用计算机的大运算量来帮助医生进行诊断,一直到深度学习的出现,才使得这个想法变得可行,因为早期诊断算法的诊断效率以及准确率都比较低,不能达到实用的要求。随着深度学习的出现,在各种诊断率上面有了显著的提高,也使得计算机辅助诊断的想法成为了可能。
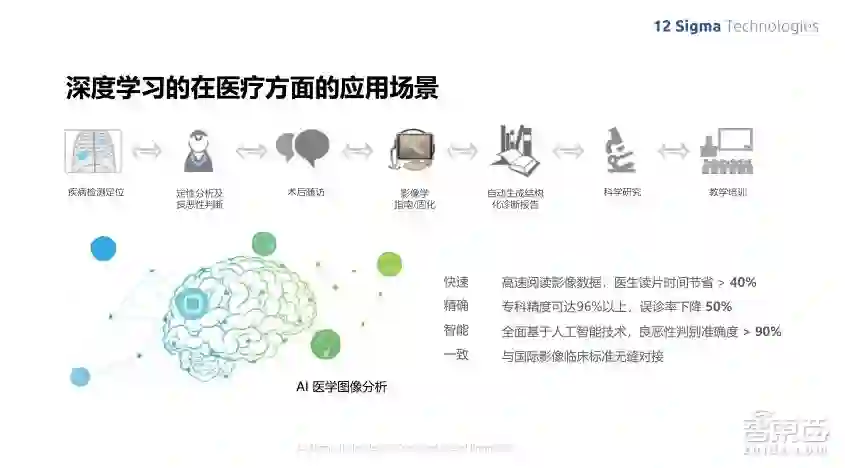
就肺癌诊断这个方向来说,其实绝大多数其他疾病的诊断跟肺癌诊断的应用场景是比较相似的。由于数据量非常庞大,由医生一张张来找是非常困难的一件事情。所以,我们可以通过算法来自动进行疾病的病灶检测和定位,在进行了病灶的定位以后,还可以做一些辅助性的定性分析,比如结节的良恶性判断等工作,由于有随访的要求,那么一个病人可能是在经过半年时间左右再回来复查的时候,我们需要了解结节的变化大小,所以这些数据由计算机来计算,就非常方便。深度学习由于它快速有效的运算以及非常高的精度,使得其在不少实际的识别问题中已经达到了接近人的视觉经验的水平,同时它是比较智能化的,可以通过大量数据的训练来增强它的准确性。
深度学习应用在医学中也可以去生成自动学习的特征来进行疾病的识别和判断,也可以自动生成结构化的诊断报告,辅助进行科学研究以及教学培训。

那么传统的CAD技术为什么达不到这些效果呢?在传统的CAD技术里,主要是通过医学影像分析,由那些有很多经验的人来设计一些比较适合做不同类型疾病检测的特征值,比如纹理分析、边缘检测以及物体检测的各种不同的特征函数,比如SIFT或HoG等。
但是这些特征的训练完全是通过人来实现的,而人需要去看大量的病例,然后从数据中总结出经验,而且不可能用太多的特征来做这件事情,所以导致了疾病的诊断率一直上不来,同时在面对不同疾病的时候,又需要设计一套完全不同的特征向量,这也是传统CAD技术没办法很快地应用到医学的不同领域中去的原因。
随着深度学习技术的出现,它对我们最大的贡献是提供了一套可以从大量数据中自动学习最有效特征的算法。其实它也是在模拟人的视觉系统及识别系统中的一些实现方式,比如,以前人是通过看大量的图像来人为地选取特征,而现在变成利用梯度的反向传播原理来自动提取特征向量。
深度学习的另外一个好处,就是它在训练的过程中,一直专注于优化准确率,而且它可以通过看大量的训练数据来实现最优的准确率,如果让人类来做这个设计的话,几乎是不可能实现的。我们不可能去把所有的图都去算一遍,然后去调整阈值,调整各种权重之类的参数来达到最优,现在这些都是由具备超强运算能力的GPU来实现的。
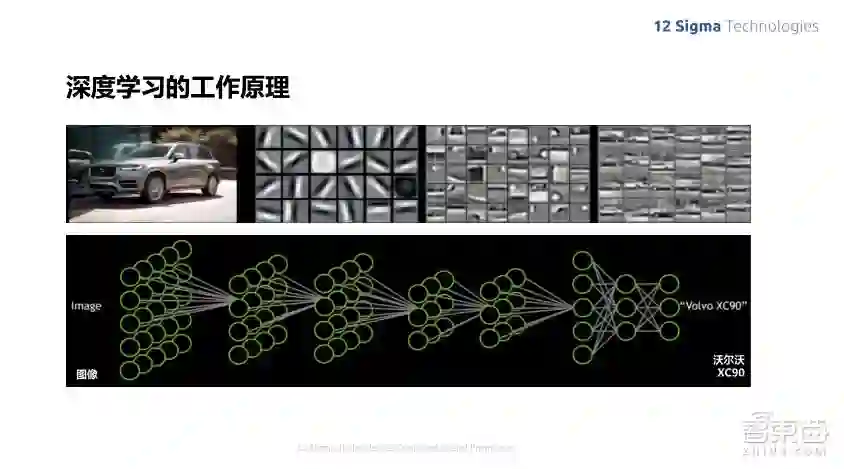
这个图就是深度学习早期时候的一些文章,显示它训练出来的特征向量,我们可以看到,其实在前几层的时候,深度学习选出来的特征向量跟人选出来的特征值是非常接近的。比如各种不同角度的edge detection,以前人类来设计特征向量也有各种角度多个尺度的Gabor Filter Bank等这些设计,相比来说其实是非常类似的。但是人没办法进入更高层的抽象,所以导致识别的效率没有那么高,可以看到,在后面几层识别出来的这些特征,就比较接近每个元部件的组成。
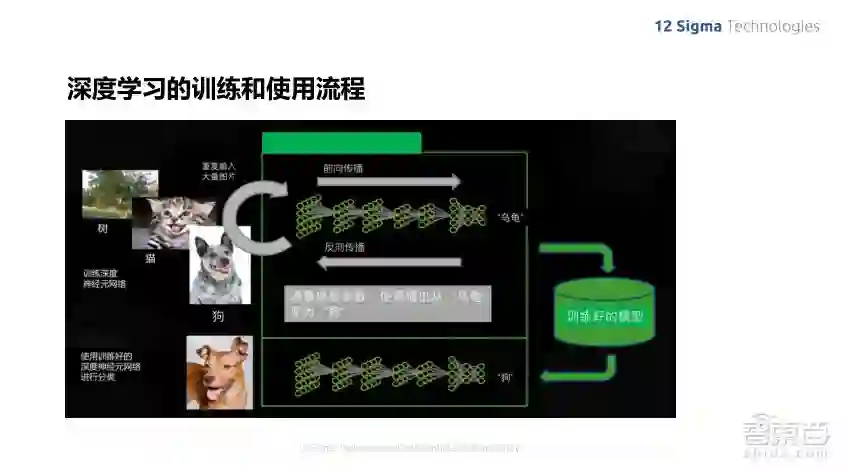
可以看到,如果我们要识别不同物体的种类,比如树、猫、狗等,那么深度学习一开始在所有网络里面的权重都是随机选取的,这时它出来的结果很可能是完全没有道理的,比如给它一张猫的图片,它可能认为是乌龟,但是我们因为有这个类型的标识,所以我们可以知道这个做错了,这时它就可以把错误反向传播,同时希望使得给出的正确路径得到进一步的增强,而错误的路径则得到进一步的抑制,经过多次这样的循环以后,得到准确的特征向量。
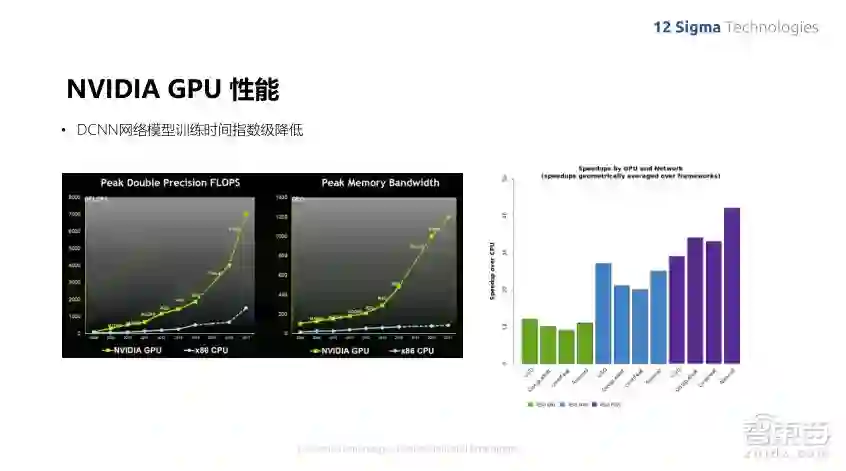
整个学习的过程在早期是没办法实现的,电脑的计算能力虽然一直有非常快速的增长,也符合之前的摩尔定律,但即使如此,计算能力也一直没办法进行这么大规模的训练量,而随着NVIDIA GPU的出现,运算能力已经远远超过原来摩尔定律的设定,最主要原因当然是因为GPU可以进行大规模的并行计算,我们知道这些特征的计算都是基于一个小的区域来进行的,而在整张图像上的不同地方都是可以并行计算的。随着GPU的发展,不同深度学习网络的运算速度尤其是训练的速度已经显著增强,GPU比CPU的速度要快出好几百倍。

因为针对的是三维医学图像,所以我们的算法使用的是三维卷积网络,在三维的情况下,计算量更大,因此GPU的效果在我们实际机器上做出来的benchmark中,GPU效率使CPU的500多倍,在做最终推理的时候,大概是2000多倍。
拿到了DGX Workstation后,我们又跟之前用的P100 GPU做了比较,发现DGX的运算速度比P100要快一倍左右,在训练和推理过程中,基本上都是超过一倍的速度。
我一直觉得训练速度是一件非常重要的事情,因为在整个模型中,我们经常需要去调各种模型参数、试验不同的模型等,如果每调整一个参数我们都需要等上好几天才能看到结果的话,那么整个算法模型优化的过程就会变得非常没有效率,可能过了几天等结果出来了以后,我们都忘了想做什么测试了,所以现在如果能加快训练模型的速度,对研发是非常有好处的。
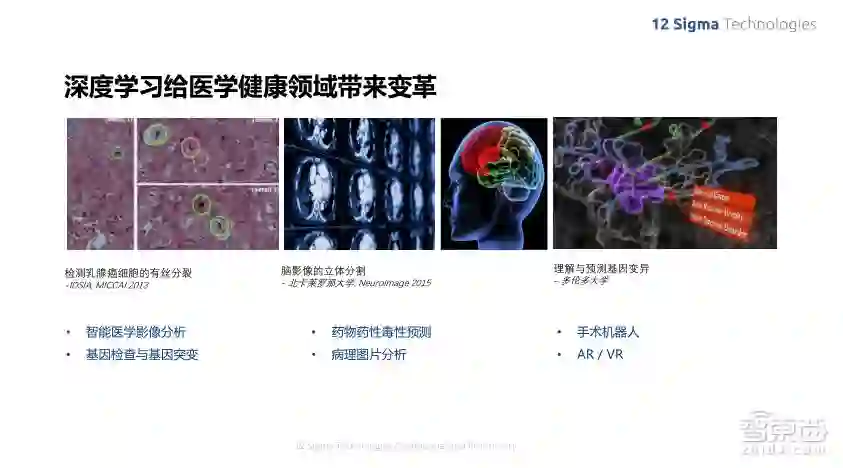
深度学习在医疗上已经取得了非常广泛的应用,比如各种Pathology的图像、脑影像的立体分割、基因序列预测、眼底视网膜成像,还有最新的Nature杂志上的皮肤癌诊断等。
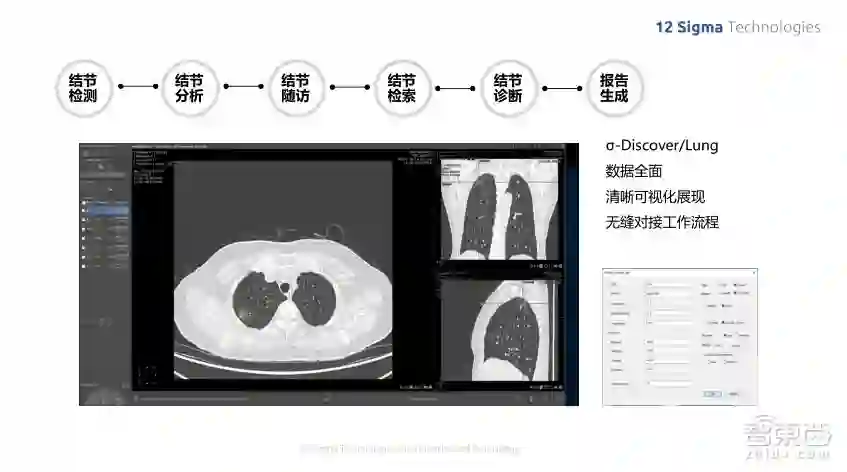
我们的肺结节诊断系统实现了多个功能,就像前面列的在医疗场景里的应用一样,我们需要帮助医生实现好几个不同的功能,包括结节的检测、对结节进行分割,然后给一些定量定性的分析,也可以对结节的不同时期的随访病人跟踪其每个结节在时间上的变化,然后是结节的检索,可以看出过去类似结节的分析结果,以及对结节做出最终的良恶性判断,判断它是哪个类型的,是良性还是恶性,最后还可以自动生成报告,整个流程极大地加速了医生的诊断过程。
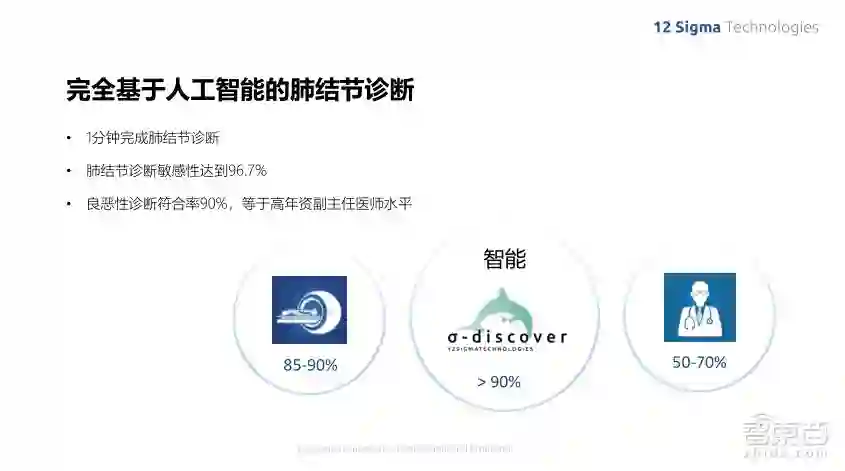
整个系统花一分钟左右的时间就能够完成所有肺结节的诊断,而对肺结节诊断的敏感性达到96.7%,良恶性判断的准确率为90%,相当于高年制副主任医师的水平。
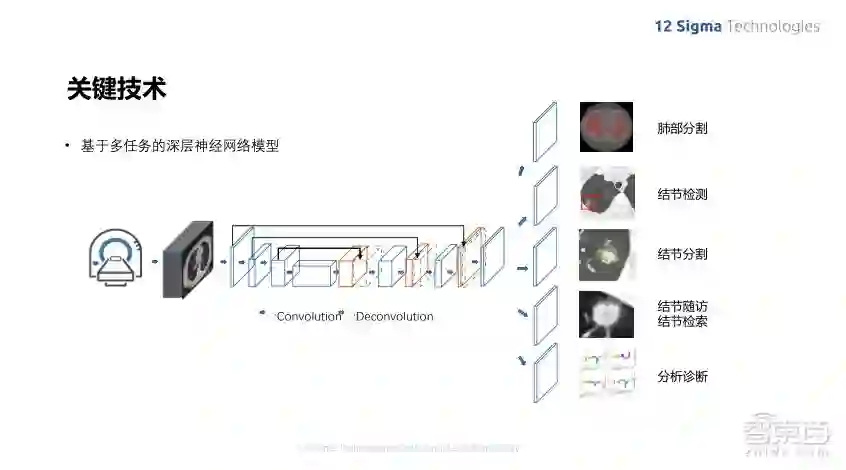
这是我们模型设计的框架,是基于多任务的深层神经网络模型来做的。为了做整个结节的检测,我们需要完成多个任务,包括肺部的分割、结节的检测、结节的分割,然后进行结节的随访和检索,以及结节的定量定性分析,比如判断结节的种类、良恶性。这些任务都有它们自己的训练数据,但是它们之间共享深度学习网络层的特征,只是在最后进行不同的任务而已。在训练的时候,根据不同的任务,它的训练标注模式也是不一样。
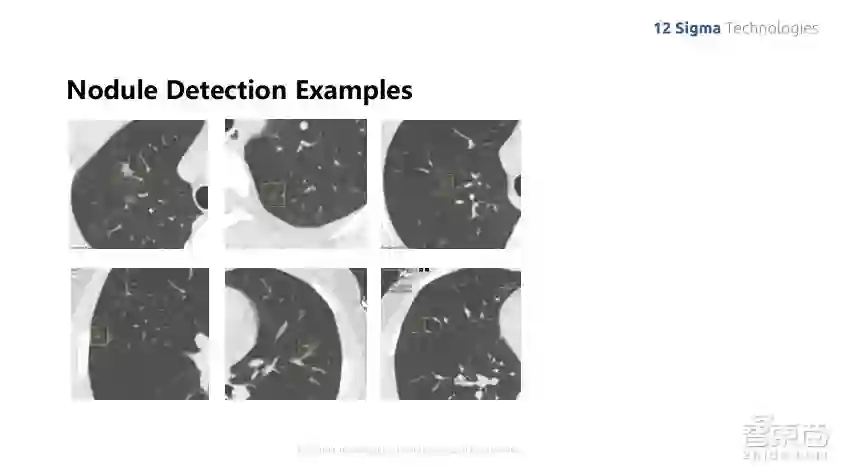
上面这张图就显示了几个我们检测到的结节,一般结节看起来是什么样子的呢?我们可以看到,肺部的结节种类是非常多的,尤其是在中国,有不少毛玻璃类型的结节,他们之间的对比度非常弱,也非常小,我们可以看到它跟边上的血管、气管对比度要弱很多,但是由于我们是利用深度学习训练出来的模型进行识别,它是自动进行的,可以看到3D的图像,不光是在二维层面去看这个图像,同时可以制造上下层之间的关系,利用整个空间信息来最终实现结节的诊断。
目前我们的肺结节诊断系统已经安装了超过一百家医院。在试用期间已经处理了超过90万的病例,帮助避免漏诊20000个左右的结节,我们之前也在CCR做过“医生+AI”和“医生”的比较,发现“医生+AI”能够节省80%的读片时间,同时还能降低漏诊率,因为我们在看到结节非常微小的时候,是很容易漏诊的。在医生划过整个CT volume的时候,是非常容易漏诊掉的。

上面这张图里面就是我们在试用的过程中找到的一些结节,其中有一些做了病理的检测。我们可以看到,对于这个病例的第一个结节,算法认为它是中等风险,最后病理检测出来确实是良性的,是不典型增生。
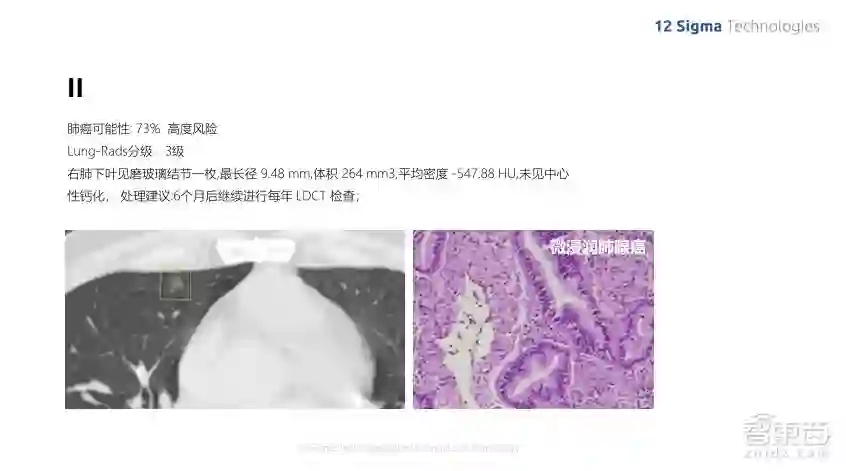
这是另外一个病例,虽然这个结节的尺寸也非常小,还不到一厘米。但是它是磨玻璃的形状,我们的算法分析出它的风险度比较高,最后实际的病理测试证明它确实是恶性的微浸润肺腺癌。
所以从整个的使用情况来看,我们非常高兴看到计算机辅助诊断确确实实能够很大地提高医生的诊断率,提高医生的效率,以及防止漏诊和误诊等。我们写出来的算法并不是要去替代医生,而是希望能更好地去辅助医生,提升医生的工作效率,能够集中精力去确定病人的治疗方案,而不是花在很多计算机轻易就能做得很好的一件事情上。
今天的内容基本上就是这些了。非常高兴能有机会和大家交流深度学习在图像上的应用。希望感兴趣的人可以跟我们公司联系。谢谢大家!
另外,陈韵强博士在Q&A环节针对「智能医疗」社群六位用户的提问进行了回答,以下是实录:
问题一
赵兵强 浙江省嘉善县中医医院放射科主任
1、低剂量胸部扫描是否同样能识别结节的良恶性?
2、高分辨率模式重建和标准窗重建对结节识别有什么区别?
陈韵强:1、第一个问题,答案是肯定的,我们知道美国肿瘤协会公布了大量的肺癌数据,都是低剂量胸部扫描的数据,我们的算法在这方面测试识别的准确率还是相当高的。
2、关于第二个问题,我们在实际训练的时候,不同重建模式的数据都会放在训练数据里面,这些重建的参数会影响图像的特征,所以我们把这些不同的重建模式都放在训练数据里面,可以实现更加通用的检测算法。
问题二
汪翼 太原航空仪表工程师
目前医疗影像领域识别肝细胞癌(CT或者MRI)最新的和主流的深度学习模型是什么?3DU-net在医疗影像的应用前景如何?
陈韵强:现在识别大多数还是用的是ResNet,DenseNet等识别模型。3DU-net还是比较适合医疗影像的图像分割的,现在取得的成绩也相当不错。大多数人会采用改良的3DU-net来做医疗影像分割。
问题三
刘春雷-连心医疗深度学习算法工程师
医学图像分割相对传统图像分割有哪些难点?目前表现突出的用于医疗图像分割的网络模型有哪些?
陈韵强:就我个人感觉,医学图像主要是人体各种疾病的诊断,所以它上下文的信息是非常重要的。即使医生在看医学图像的时候,也需要知道他在看哪个器官的哪类疾病,然后来帮助诊断出病灶;另外一个比较重要的是高分辨率的图像信息,通常来说病灶都是非常微小的,如果做了任何down-scaling 这种事情的话,信息就会丢掉很多,就变得很难找到,所以现在表现比较突出的医疗分割网络,比如U-net结构,它可以比较有效地集成不同尺度的信息。
问题四
陈嘉伟 南方医科大学
影像数据的预处理环节对于整个模型训练过程中有多大关键影响,能否以一个实例分析一下吗?
陈韵强:我觉得预处理这个环节,基本上跟传统CAD的做法很像,通过人的先验知识去找到一个特定的特征空间来帮助算法检测目标。实际上如果在训练数据比较多的时候,深度学习很可能自己学出来;如果在训练数据比较小的时候,预处理就会显得比较重要一些。
问题五
卢红阳 中科院医工所
深度学习在磁共振成像中的应用如何?
陈韵强:深度学习在不同的医学成像、模组里面都有很大的应用范围。深度学习在核磁共振里面,我看到相关的研究方向有脑部分割、做肝结节检测、心脏功能分析等,涉及到这方面的工作也非常的多。
问题六
陈章 Thomas Jefferson Hospital
请问医疗影像数据一般如何获取?
陈韵强:大家也都发现,大量的数据训练深度学习网络能够做出更好的结果,去造福广大患者,增加医疗准确性。现在数据获取已经远远不像以前那么困难,当然医疗数据还是比较敏感的,所以一定要匿名化,这些操作如果符合内化的规则,数据还是可以获取到的。
如需本期实战营课件及音频,可以在智东西公众号回复关键字“实战营”获取。
#智东西出品#本周五晚8点,NVIDIA实战营第三期将在「智能安防」社群开讲,西安交通大学人工智能和机器人研究所博士陶小语、NVIDIA高级系统架构师易成将围绕《智能监控场景下的大规模并行视频分析方法》这一主题展开深度讲解,长按二维码报名(或者点击底部「阅读原文」填写主群申请表),免费入群听课。