隐藏云 API 的细节,SQL 让这一切变简单

渗透测试人员、合规性审计员和其他 DevSecOps 专业人员花了大量时间编写脚本来查询云基础设施。人们喜欢用 Boto3(Python 版 AWS SDK)来查询 AWS API 并处理返回的数据。
它可以用来完成简单的工作,但如果你需要跨多个 AWS 帐户和地区查询数据,事情就变得复杂了。这还不包括访问其他主流云平台(Azure、GCP、Oracle Cloud),更不用说 GitHub、Salesforce、Shodan、Slack 和 Zendesk 等服务了。开发人员花了太多的时间和精力从这些 API 获取数据,然后将其规范化并开始真正的分析任务。
如果你可以用一种通用的方式查询所有 API 并处理它们返回的数据会怎样?Steampipe 就是用来做这个的。它是一个基于 Postgres 的开源引擎,你可以用它编写间接调用主要云平台 API 的 SQL 查询。它不是一个数据仓库。调用 API 生成的表是临时的,它们反映了基础设施的实时状态,你可以用 SQL 对它们进行实时的查询。
本文的案例研究将展示如何使用 Steampipe 来回答这个问题:我们的公共 EC2 实例是否有已被 Shodan 检测到的漏洞?我们需要使用 AWS API 列出 EC2 的公共 IP 地址,并使用 Shodan API 来检查它们。
如果使用传统的方法,你需要找到每个 API 的编程语言包装器,了解每种 API 的访问模式,然后编写代码来组合结果。在 Steampipe 中,一切都是 SQL。这两个 API,就像 Steampipe 的 API 插件 支持的所有 API 一样,被解析成 Postgres 数据库表。你可以用 SQL 对它们进行基本查询,甚至是连接查询。
图 1 描绘了我们案例研究的主要 API 连接。aws_ec2_instance 表是 Steampipe 通过调用 AWS API 构建的 数百个表 中的一个。类似地,shodan_host 表是 Steampipe 通过调用 Shodan API 构建的 十几个表 中的一个。SQL 查询将 aws_ec2_instance 的 public_ip_address 列与 shodan_host 的 ip 列连接起来。

在深入案例研究之前,我们先来仔细地看看 Steampipe 的工作原理。下面是 Steampipe 的高级架构视图。
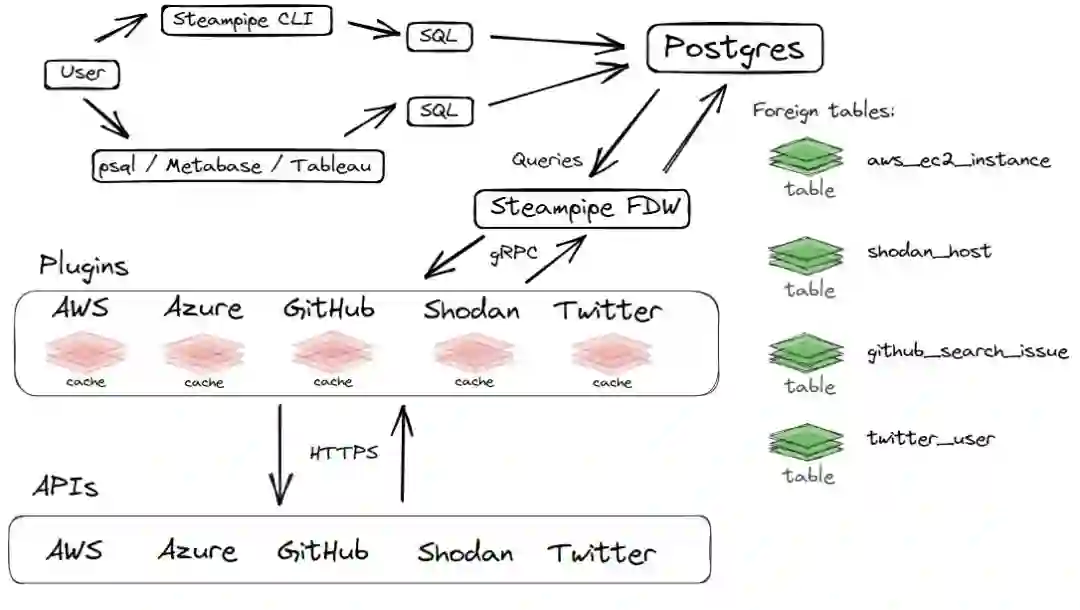
为了查询 API 并处理返回的结果,Steampipe 用户需要使用 Steampipe 的查询控制台(Steampipe CLI)或其他可以连接 Postgres 的工具(psql、Metabase 等)来编写 SQL 查询并提交给 Postgres。针对 Postgres 的关键增强特性包括:
Postgres 外部数据包装器;
各种 API 插件;
连接聚合器。
Postgres 已经有了长足的演进。如今,得益于不断增长的插件生态系统,Postgres 比你想象的要 强大得多。强大的扩展插件包括用于地理空间数据的 PostGIS、用于在 Kafka 或 RabbitMQ 中复制数据的 pglogical,以及用于分布式操作和列存储的 Citus。
外部数据包装器(FDW)是 Postgres 的一个插件类别,用于为外部数据创建数据库表。Postgres 的绑定 postgres_fdw 支持跨本地和远程数据库的查询。Steampipe 在运行时会启动一个 Postgres 实例,这个实例会加载另一种 FDW,叫作 steampipe-postgres-fdw,它会调用一系列 插件 为外部 API 创建数据库表。
这些外部表通常将 JSON 结果映射成简单的列类型:日期、文本、数字。有时候,如果 API 响应消息中包含复杂的 JSON 结构(如 AWS 策略文档),结果会显示成 JSONB 列。
这些插件是用 Go 编写的,回退 / 重试逻辑、数据类型转换、缓存和凭证由 插件 SDK 负责处理。有了这个 SDK,插件开发者可以将精力放在核心的任务上,也就是将 API 结果映射到数据库表。
这些映射可以是一对一的。例如,aws_ec2_instance 表与底层 REST API 相匹配。
在其他情况下需要构建合并了多个 API 的表。例如,为了构建完整的 S3 桶的视图,需要连接核心 S3 API 与 ACL、策略、复制、标签、版本控制等子 API。插件开发者负责编写函数来调用这些子 API,并将结果合并到表中。
下面是一个使用 Steampipe 列出 EC2 实例的示例。
安装 Steampipe;
安装 AWS 插件:steampipe plugin install aws;
配置AWS 插件。
插件配置使用了标准的身份验证方法:配置文件、访问密钥和秘钥文件、SSO。因此,Steampipe 的客户端验证与其他类型的客户端验证是一样的。完成这些之后,就可以查询 EC2 实例。
示例 1:列出 EC2 实例
selectaccount_id,instance_id,instance_state,regionfrom aws_ec2_instance;+--------------+---------------------+----------------+-----------+| account_id | instance_id | instance_state | region |+--------------+---------------------+----------------+-----------+| 899206412154 | i-0518f0bd09a77d5d2 | stopped | us-east-2 || 899206412154 | i-0e97f373db22dfa3f | stopped | us-east-1 || 899206412154 | i-0a9ad4df00ffe0b75 | stopped | us-east-1 || 605491513981 | i-06d8571f170181287 | running | us-west-1 || 605491513981 | i-082b93e29569873bd | running | us-west-1 || 605491513981 | i-02a4257fe2f08496f | stopped | us-west-1 |+--------------+---------------------+----------------+-----------+
外部表 aws_ec2_instance 的文档提供了 模式定义 和 查询示例。
在上面的查询中,不需要显式地指定多个 AWS 帐户和区域就可以查到它们的实例。这是因为我们可以为 AWS 插件配置用于组合账户的 聚合器,还可以用通配符指定多个区域。在这个示例中有两个不同的 AWS 帐户,一个使用 SSO 进行身份验证,另一个使用 access-key-and-secret 方法,它们组合起来作为 select * from aws_ec2_instance 查询的目标。
示例 2:聚合 AWS 连接
connection "aws_all" {plugin = "aws"type = "aggregator"connections = [ "aws_1", aws_2" ]}connection "aws_1" {plugin = "aws"profile = "SSO…981"regions = [ "*" ]}connection "aws_2" {plugin = "aws"access_key = "AKI…RNM"secret_key = "0a…yEi"regions = [ "*" ]}
这种方法适用于所有的 Steampipe 插件,它抽象了连接细节,简化了跨多个连接的查询,还为并发访问 API 提供了可能性。
使用 Shodan 查找 AWS 漏洞
假设你想要用 Shodan 来检查一些公共 AWS 端点是否存在漏洞。下面是完成检查过程需要执行的伪代码。

传统的 Python 或其他语言的解决方案需要你使用两种不同的 API。虽然有针对这些原始 API 的包装器,但每个包装器都有不同的调用方式和结果。
下面是使用 boto3 来解决这个问题的示例。
示例 3:使用 boto3 查找 AWS 漏洞
import boto3import datetimefrom shodan import Shodanaws_1 = boto3.Session(profile_name='SSO…981')aws_2 = boto3.Session(aws_access_key_id='AKI…RNM', aws_secret_access_key='0a2…yEi')aws_all = [ aws_1, aws_2 ]regions = [ 'us-east-2','us-west-1','us-east-1' ]shodan = Shodan('h38…Cyv')instances = {}for aws_connection in aws_all:for region in regions:ec2 = aws_connection.resource('ec2', region_name=region)for i in ec2.instances.all():if i.public_ip_address is not None:instances[i.id] = i.public_ip_addressfor k in instances.keys():try:data = shodan.host(instances[k])print(k, data['ports'], data['vulns'])except Exception as e:print(e)
如果 API 被抽象为 SQL 表,你就可以忽略这些细节,并提取出解决方案的精华部分。下面是使用 Steampipe 解决这个问题的示例,即“Shodan 是否找到了 EC2 实例公共端点的漏洞?”
示例 4:使用 Steampipe 查找 AWS 漏洞
selecta.instance_id,s.ports,s.vulnsfromaws_ec2_instance aleft joinshodan_host sona.public_ip_address = s.ipwherea.public_ip_address is not null;+---------------------+----------+--------------------+| instance_id | ports | vulns |+---------------------+----------+--------------------+| i-06d8571f170181287 | | || i-0e97f373db42dfa3f | [22,111] | ["CVE-2018-15919"] |+---------------------+----------+--------------------+
你只需要针对 Postgres 表编写 SQL,不需要显式调用这两个 API,SQL 会临时存储隐式调用 API 的结果。这不仅更简单,而且更快。针对示例 2 中配置的两个 AWS 帐户的所有区域运行 boto3 版本的代码需要 3 到 4 秒,而 Steampipe 版本的只需要 1 秒钟。当你有数十或数百个 AWS 帐户时,这种差异会体现得更加明显。可见 Steampipe 是一个高并发的 API 客户端。
如果你定义了一个聚合了多个账户的 AWS 连接(如示例 2 所示),Steampipe 将会并发查询所有的账户。对于每一个帐户,它会同时查询所有指定的区域。因此,虽然示例 3 中初始查询花了大约 1 秒,但基于缓存 TTL(默认为 5 分钟)的后续查询只花费了几毫秒。
就像本例一样,我们通常可以基于缓存查询更多列或其他不同的列,并保持毫秒级的查询性能。这是因为 aws_ec2_instance 表是用单个 AWS API 调用的结果生成的。
对于其他情况,比如 aws_s3_bucket 表,Steampipe 组合了多个 S3 子 API 调用,包括 GetBucketVersioning、GetBucketTagging 和 GetBucketReplication,这些调用也都是并发的。与其他 API 客户端一样,Steampipe 也会受到速率限制。但它的并发性是主动式的,因此你可以快速对大量的云基础设施进行评估。
注意,在查询像 aws_s3_bucket 这样的表时,最好是只请求需要的列。如果你确实需要所有列,那么可以 select * from aws_s3_bucket。但如果你只关心 account_id、instance_id、instance_state 和 region 这些列,那么显式指定这些列(如示例 1 所示)可以避免不必要的子 API 调用。
如果你的端点只存在于 AWS 中,那么示例 3 已经可以很好地解决这个问题。现在,我们加入 GCP(谷歌云平台)。传统的解决方案要求你安装另一个 API 客户端,例如 谷歌云 Python 客户端,并学习如何使用它。
在使用 Steampipe 时,你只需安装另一个插件:steampipe plugin install gcp。它的工作原理与 AWS 一样:调用 API,将结果放入 外部数据库表 中,这样你就可以将精力放在解决方案的逻辑上。
只是此时的逻辑略有不同。在 AWS 中,public_ip_address 是 aws_ec2_instance 表 的一个列。在 GCP 中,你需要将查询计算实例的 API 和查询网络地址的 API 的调用结果组合起来。Steampipe 将它们抽象为两个表:gcp_compute_instance 和 gcp_compute_address。
示例 5:使用 Steampipe 查找 GCP 漏洞
with gcp_info as (selecti.id,a.addressfromgcp_compute_address ajoingcp_compute_instance iona.users->>0 = i.self_linkwherea.address_type = 'EXTERNAL'order byi.id)selectg.id as instance_id,s.ports,s.vulnsfromgcp_info gleft joinshodan_host s on g.address = s.ip;
这个查询使用了两个语言特性,这可能会让很久没有使用 SQL 的人感到惊讶。WITH 子句是一个公共表表达式(CTE),用于创建一个类似数据表的临时对象。用 CTE 管道形式编写的查询比单一查询更容易阅读和调试。
a.users 是一个 JSONB 列。->>操作符用于定位它的第 0 个元素。JSON 是数据库的一等公民,关系型风格和对象风格可以很好地混合在一起。这在将返回 JSON 数据的 API 映射到数据库表时就非常有用。插件开发者可以将一些 API 数据移到普通的列中,另一些移到 JSONB 列中。如何决定哪些数据移到什么类型的列中?这需要巧妙地平衡各种关注点,你只需要知道现代 SQL 支持灵活的数据建模。
查找多个云平台的漏洞
如果你在 AWS 和 GCP 中都有公共端点,那么你可能希望将到目前为止看到的查询都结合起来。现在你知道该怎么做了。
示例 6:查找 AWS 和 GCP 的漏洞
with aws_vulns as (-- 插入示例 4 的内容),gcp_vulns as (-- 插入示例 5 的内容)select * from aws_vulnsunionselect * from gcp_vulns;+-------+---------------------+----------+--------------------+| cloud | instance_id | ports | vulns |+-------+---------------------+----------+--------------------+| aws | i-06d8571f170181287 | | || aws | i-0e97f373db42dfa3f | [22,111] | ["CVE-2018-15919"] || gcp | 8787684467241372276 | | |+-------+---------------------+----------+--------------------+
我们已经将示例 4 和示例 5 作为 CTE 管道。要将它们组合起来,只需要一个老式的 SQL UNION。
现在,你已经掌握了足够多的知识,你也可以在 Oracle 云或 IBM 云上使用 CTE 管道。你可能还想用你的公共 IP 地址查询 Shodan 的数据。有些插件可以进行反向 DNS 查找,将 IP 地址映射到地理位置,并检查是否存在已报告的恶意活动的地址。这里的每一个映射都涉及另一个 API,但你不需要学习如何使用它们,它们会被建模成数据库表,你只需要用基本的 SQL 语句来查询这些表。
我们说过,Steampipe 不是一个数据仓库,为 API 调用结果创建的表只会被缓存一小段时间。针对这个系统所做的优化主要是为了实现对云基础设施的实时评估。Steampipe 实际上就是 Postgres,你可以完全把它当 Postgres 来用。如果你需要持久化实时数据,那就可以对它们进行持久化。
示例 7:将查询持久化为表
create table aws_and_gcp_vulns as-- 插入示例 6 的内容
示例 8:将查询保存为物化视图
创建物化视图 aws_and_gcp_vulns
-- 插入示例 6 的内容-- 然后定时刷新物化视图 aws_and_gcp_vulns
示例 9:使用 Python 拉取查询结果
import psycopg2, psycopg2.extrasconn = psycopg2.connect('dbname=steampipe user=steampipe host=localhost, port=9193')cursor = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)cursor.execute('select * from aws_and_gcp_vulns')for row in cursor.fetchall():print(row['cloud'], row['instance-id'], row['vulns'])
示例 10:使用 psql 连接数据库
psql -h localhost -p 9193 -d steampipe -U steampipe你也可以使用 Metabase、Tableau 或其他与 Postgres 兼容的工具连接数据库。
总的来说,Steampipe API 增强了整个 Postgres 生态系统。
专注于任务处理
DevSecOps 工程师的工作可能包括列出云资源、检查安全漏洞或审计合规性,这一切都需要用到云 API 返回的数据,而以可跟踪的形式获取这些数据通常会花费很多时间和精力。如果可以方便快速地访问 API,并有一个可以处理 API 返回的数据的通用环境,你就可以专注于列出资源清单、进行安全检查和审计等工作。API 噪音会对你和你的组织造成无法承受的干扰。不要让它们妨碍你真正的工作,即使你有了需要的数据,要做到这一点也是非常困难的。
作者简介:
Jon Udell 是前 BYTE 杂志执行编辑,一位独立的 Web 开发者,InfoWorld 的“首席博主”,微软布道者,hypothes.is 的整合总监。他苦 API 已久,现在他很高兴可以将这些繁重的工作委托给 Steampipe。他是 Steampipe 开源项目的社区负责人。
原文链接:
https://www.infoq.com/articles/steampipe-api-sql/
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
字节将大幅压缩招聘规模;滴滴被罚 80 亿,违法行为持续 7 年;各国软件开发者薪资统计:中国上榜全球开发者薪酬最低国家名单 | Q 资讯

点个在看少个 bug 👇



