KDD20 | 图模型的信息融合专题
1 引言
使用图模型解决问题时,面对实际环境中来源多样、形式复杂的数据,怎样将多种信息进行合理融合是一个值得关注的问题。本文将介绍两篇发表于KDD 2020的与图模型信息融合相关的工作。
第一篇工作为《HGMF: Heterogeneous Graph-based Fusion for Multimodal Data with Incompleteness》,该工作主要是基于异质图来解决多模态学习中在信息融合时会遇到的模态缺失问题。
第二篇工作为《Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion》,该工作通过引入两个外部知识图谱丰富会话的语义信息,并通过互信息最大化弥补知识图谱间的语义鸿沟以提升会话推荐系统的表现。
2 HGMF: Heterogeneous Graph-based Fusion for Multimodal Data with Incompleteness

2.1 引言
多模态数据指的是从多种来源收集到的异构数据,例如人机交互场景中识别人类行为与情感时收集到的视觉、声音、语言数据;进行生物医学数据分析时收集的实验、基因序列以及医疗记录数据等。多模态数据能为实际问题提供相互补充的信息,对其进行学习具有很高的价值。多模态学习包含多模态数据融合、多模态情感分析以及图像问答等多个分支,本文关注的是多模态数据的融合任务,即将高度交互的多种模态数据进行合理融合后用作下游任务的决策。
然而,在实际的多模态数据收集过程中,由于传感器故障、数据损坏以及人为失误等多种原因,最终收集的数据常常存在不同程度的模态缺失。下图展示了一个具有模态缺失问题的三模态数据集。
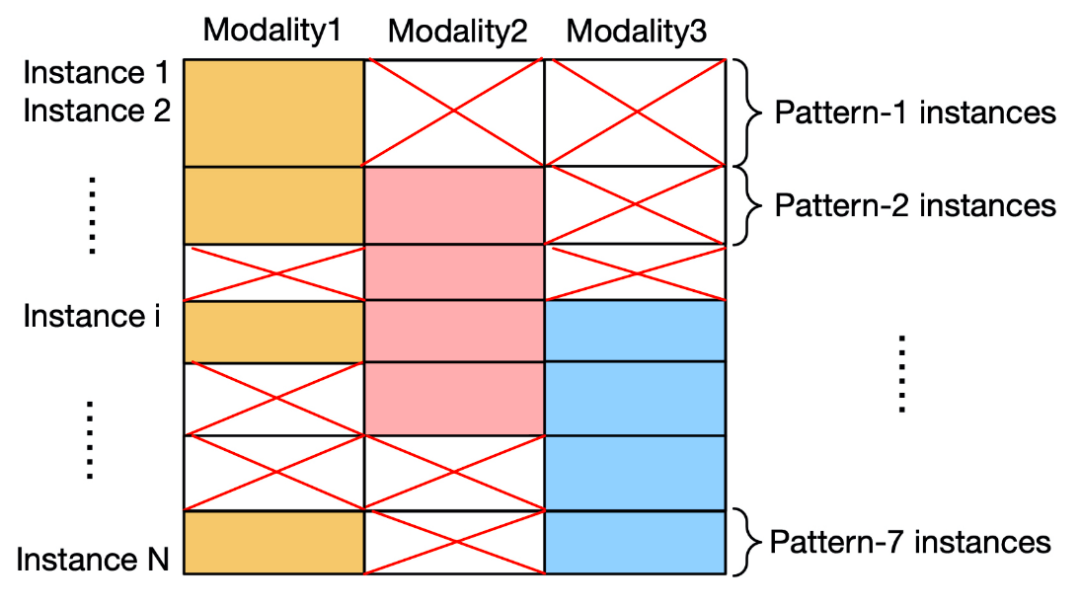
模态缺失导致多模态数据在融合过程中会遇到以下三个技术挑战:
-
数据丢失降低了可用数据规模 -
样本具有不同程度的模态丢失,从而具有不一致的特征空间以及维度 -
有效的多模态融合需要同时学习模态内部特有以及多模态间的交互信息
总之,如何有效地将不完整并高度交互的多模态数据进行融合仍是一个极具挑战性的问题。与已有的基于不完整数据的直接删除或数据插补(data imputation)的解决方案不同的是,本文提出了一种通过构建异质图并在异质图嵌入的同时实现不完整多模态数据融合的方法。
2.2 模型
作者提出的Heterogeneous Graph-based Multimodal Fusion(HGMF)模型总览如下:

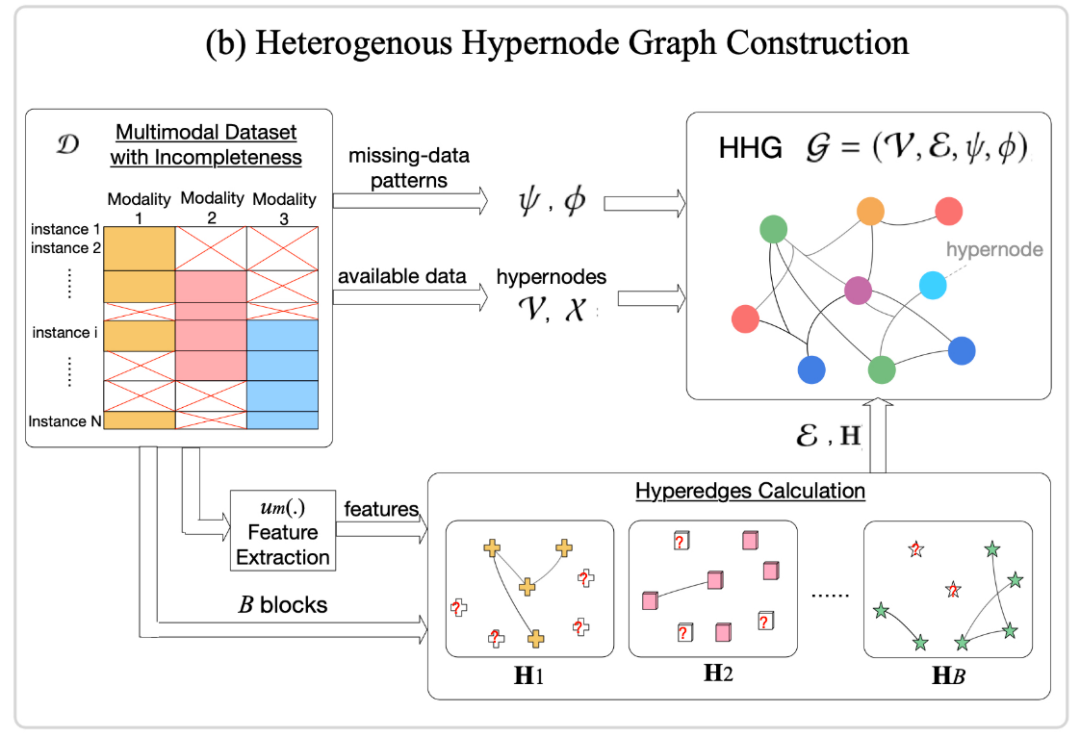
2.2.1 异质超点图的构建
异质超点图中的节点具有不同数量以及维度的特征,被称为超点;一条边可同时连接
本文中,作者定义不完整模式为模态的一种组合方式。对于一个具有模态缺失问题的
作者首先将数据集中的所有数据按照可用模态的不同组合方式分为
将所有块分别构建得到的子图统一到一个图中,可以得到最终的异质超点图。注意到,在这样的一种构图方法中,两个数据点的部分公共模态特征相近就可能被超边连接,即缺失某种模态的数据点与含有该种模态的数据点可能被连接,从而在一定程度上减轻模态不完整的问题。
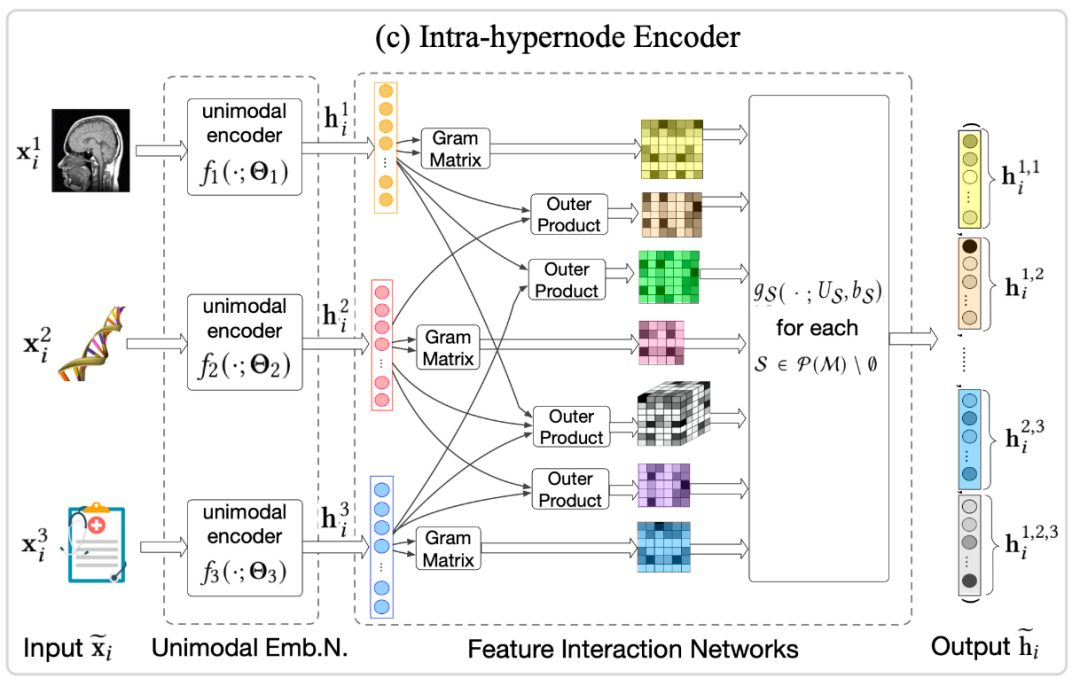
2.2.2 节点内编码器
每个超节点内部本身就包含高度交互的多模态内容,作者对这部分内容进行了编码。
作者首先使用CNN、Bi-LSTM或全连接网络等DNN对单模态特征进行嵌入,得到第
若
若
编码器通过对节点内部模态内部以及模态间交互的捕捉,将原始的模态特征集
2.2.3 多折双层图注意力
由于不同节点的模态组合不同,上步编码之后得到的图仍是异质的。为实现异质图上的多模态信息融合,作者使用双层图注意力机制。首先聚合同种模式下邻居的信息,接着聚合不同模式信息。
-
模式内聚合
对于节点
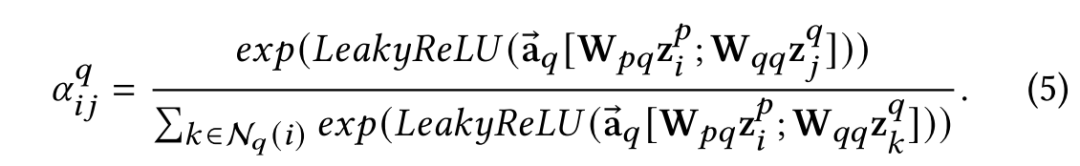
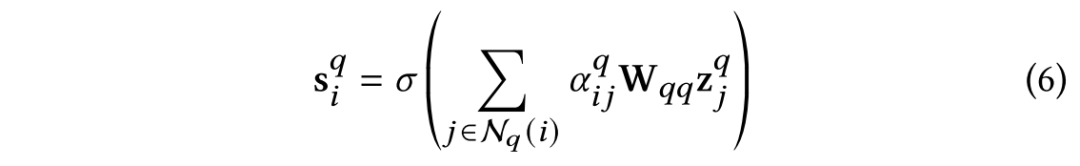
-
模式间聚合
在聚合完模式内部信息之后,下一步是学习不同模式之间的关系,使得有不同模态缺失情况的数据点可以彼此学习,弥补缺失信息。聚合一个数据点的不同模式表示采用类似的注意力机制:
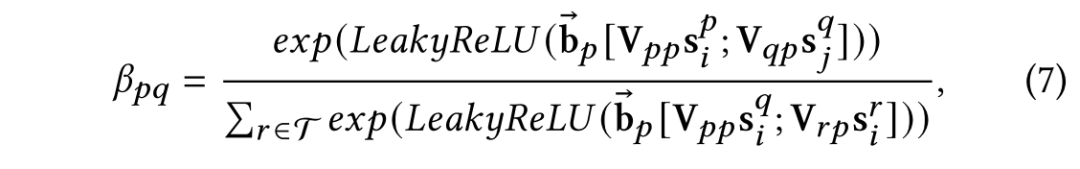
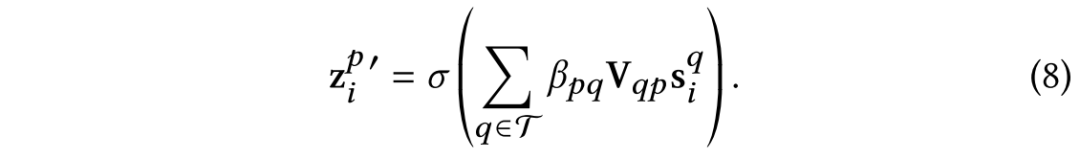
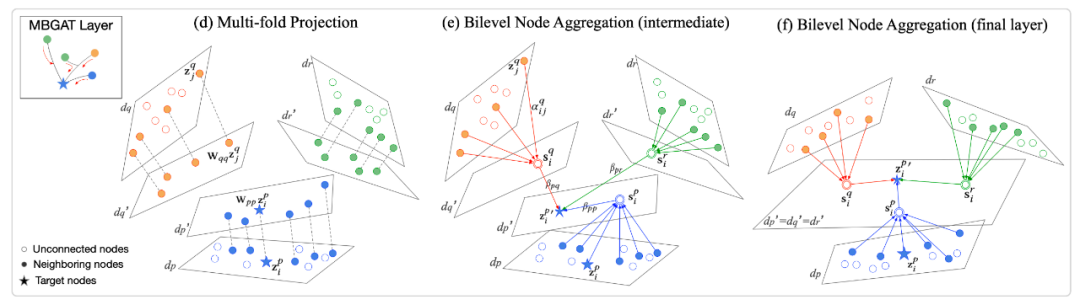
堆叠多个以上双层图注意力层以实现异质多模态数据的层级交互与融合。
2.3 实验
实验包含3D物体识别以及情感识别两个任务,前者使用双模态数据集ModelNet40以及NTU进行,后者选择三模态数据集IEMONAP进行。为了模拟实际应用中可能出现的模态缺失情况,作者设置了多模态不完整比例
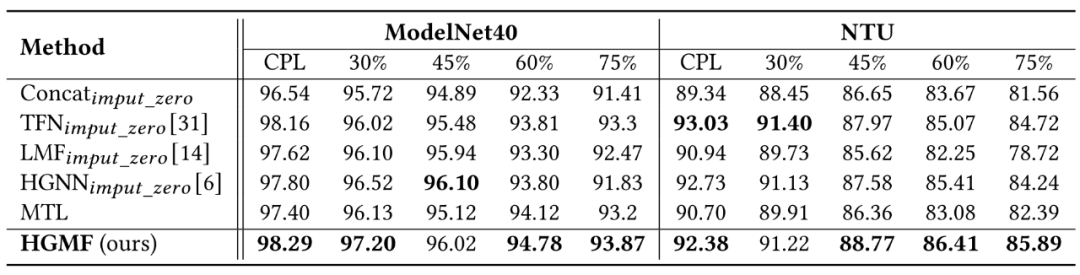
HGMF以及其他baseline在不同多模态不完整比例下进行3D物体识别实验的结果如下(CPL代表模态数据完整):
三粒度情感识别的实验结果如下:
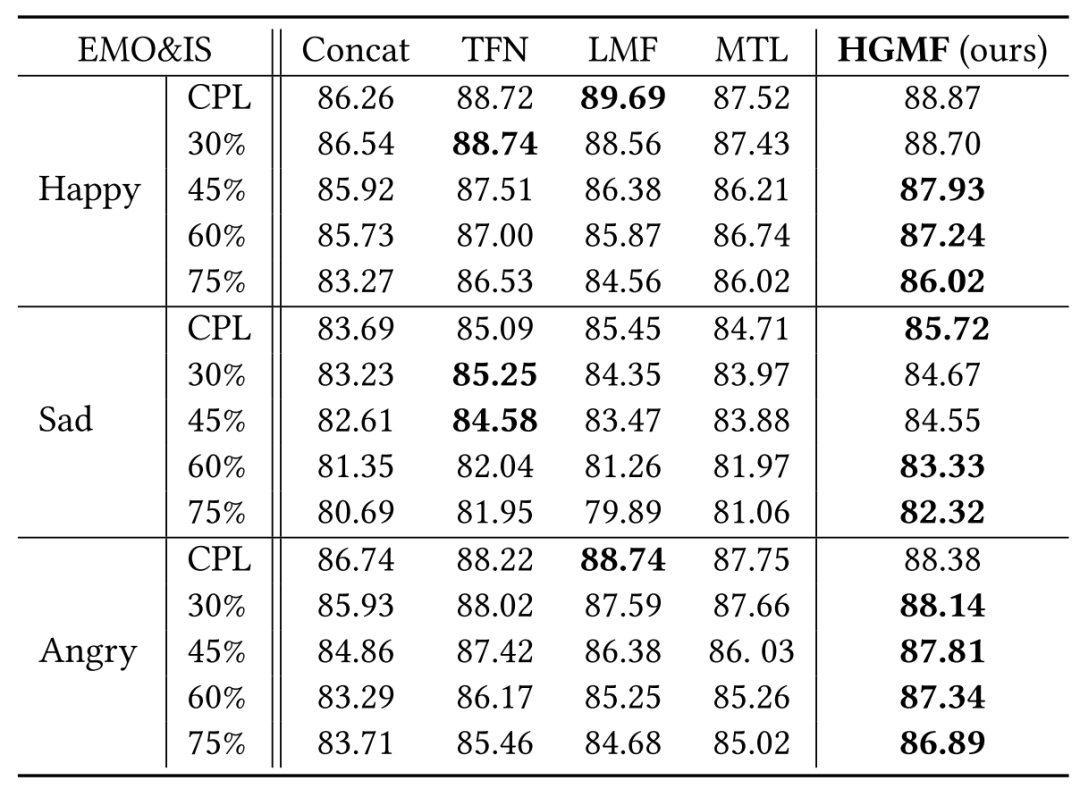
可以看到,HGMF在模态不完整比例较高时的表现与其他baseline相比得到了稳定提升,说明其确实具有缓解模态缺失问题的能力。
3 Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion

3.1 引言
会话推荐系统(Conversation Recommender System, CRS)作为一种通过与用户的交互式对话生成高质量推荐商品的推荐系统,近年来越来越多地受到人们的关注。一个电影推荐场景下的CRS工作示例如下所示。

CRS需要推荐模块和对话模块的无缝整合。对话模块负责理解用户意图,并生成恰当的回复语句;而推荐模块负责学习用户偏好,并基于上下文内容为用户推荐高质量商品。目前针对CRS的研究中主要存在以下两个问题需要解决。
-
与传统推荐系统能够利用用户的历史交互序列或用户属性不同的是,CRS使用的对话数据缺少足够的上下文内容帮助精确理解用户偏好; -
对话以自然语言的形式展示,而实际的用户偏好是反映在商品或实体上的。这两类数据信号间存在天然的语义鸿沟。
为解决上述问题,本文提出了基于知识图谱的语义融合模型KG-based Semantic Fusion(KGSF),通过引入面向词语的知识图谱ConceptNet和面向商品的知识图谱DBPedia丰富对话信息,并通过互信息最大化消除两个知识图谱之间的语义鸿沟。基于对齐之后的语义表示,作者还设计了KG增强的推荐模块用于生成精确推荐以及KG增强的对话模块用于在回复文本中生成信息量丰富的关键词或商品。
3.2 模型
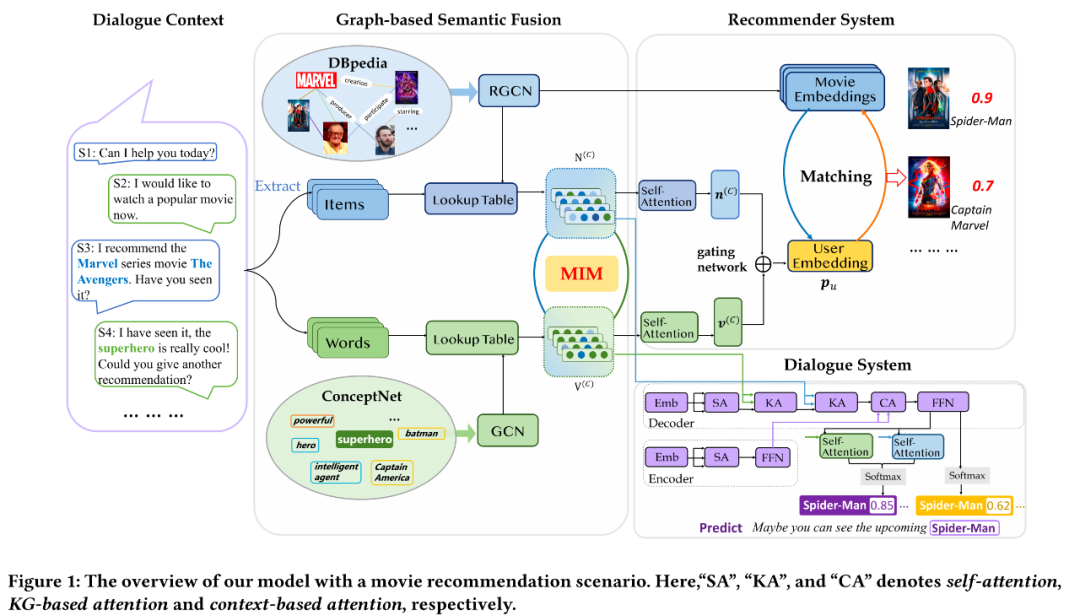
3.2.1 编码外部知识图谱
-
编码面向word的知识图谱
本文使用GCN编码ConceptNet,每次更新时执行以下聚合操作:
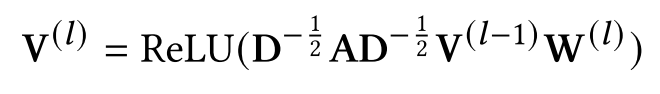
-
编码面向item的知识图谱
Item间的关系比词语间要复杂的多,本文使用关注节点间关系的R-GCN来学习item的表示:
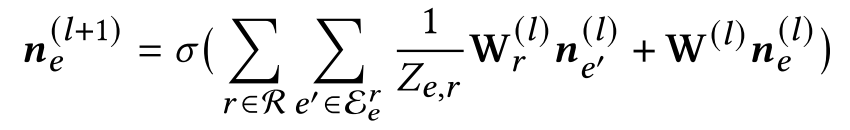
3.2.2 使用互信息最大化的知识图谱融合
消除word与item在表示上的语义鸿沟的核心思想在于使对话中共现的word和item在知识图谱中有相近的节点表示,这样能够统一两个语义空间中的数据表示。本文使用互信息最大化的方法达到以上目的。
给定两个变量
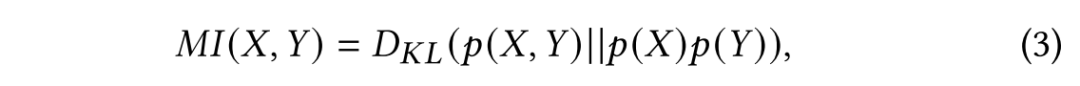
其中,
互信息的准确数值通常很难计算得到,通常转化为计算其下界,通过抬高互信息下界值来间接使得互信息最大化:
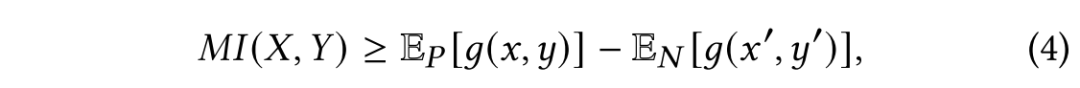
其中,
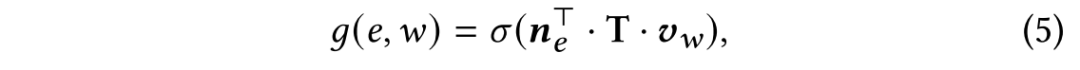
由(4)式和(5)式,可以得到知识图谱嵌入模块的优化目标函数。
3.2.3 知识图谱增强的推荐模块
本文将对话经知识图谱嵌入并使用自注意力机制后得到的词向量
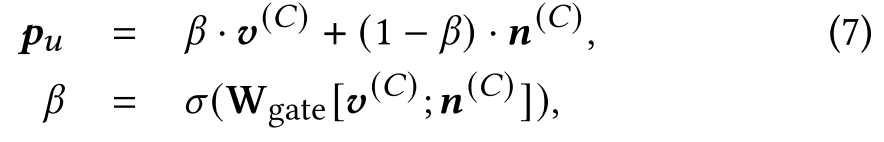
商品被推荐给用户的概率为:
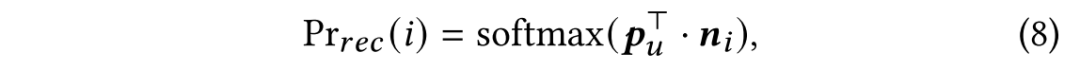
使用如下交叉熵损失函数学习参数:
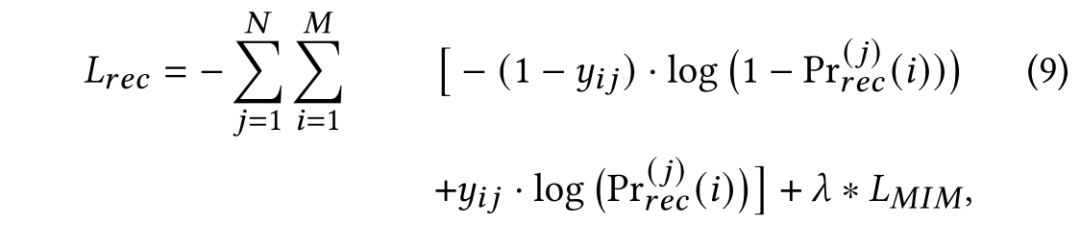
其中,
3.2.4 知识图谱增强的回复生成模块
本文沿用了Transformer的编码器-解码器架构,并对解码器进行了改进,在自注意力子层之后,又使用了两个融合知识图谱的注意力层:
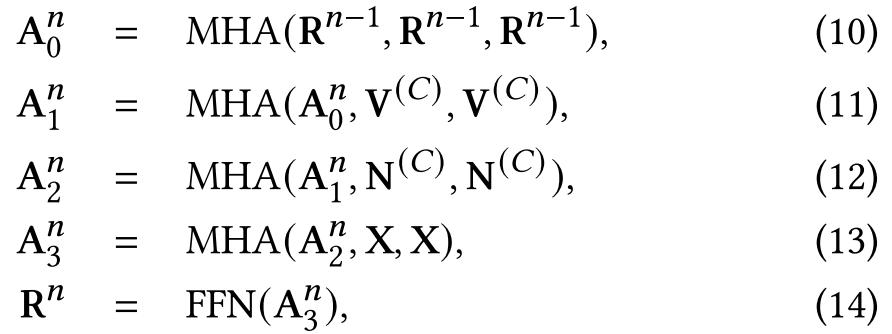
其中,
回复生成模块的损失函数如下:
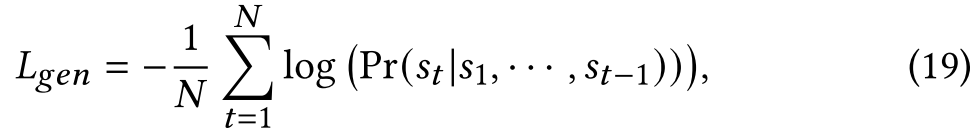
3.2.5 参数学习
参数学习的完整流程如下:
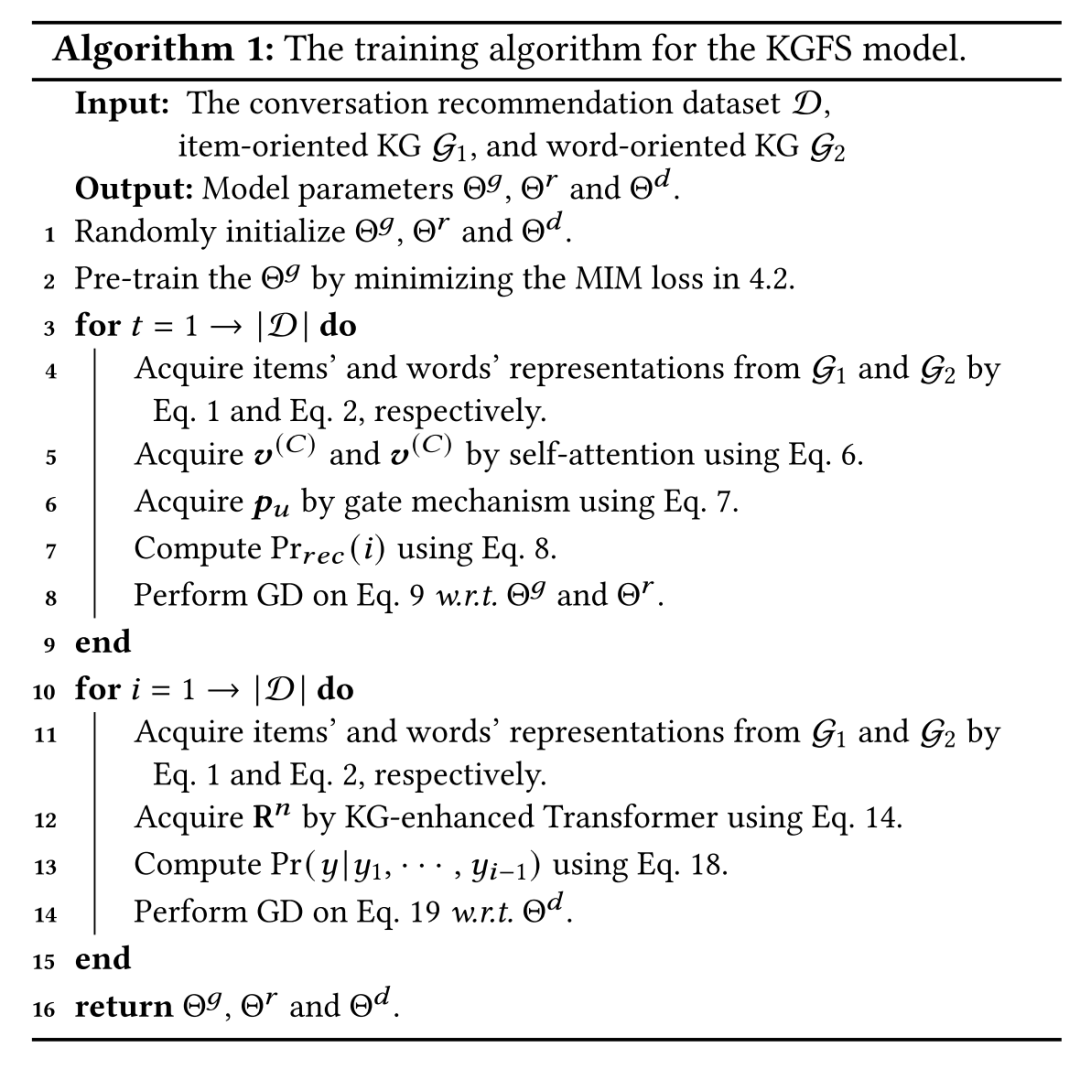
首先通过互信息最大化对两个知识图谱的嵌入图神经网络进行预训练;接下来通过推荐item的交叉熵损失学习推荐模块参数并同时微调图神经网络参数;最后是回复生成模块参数的单独学习。
3.3 实验
本文在CRS数据集ReDial上分别进行推荐任务以及对话生成任务实验,并对比了KGSF与其他baseline的表现。
3.3.1 推荐任务
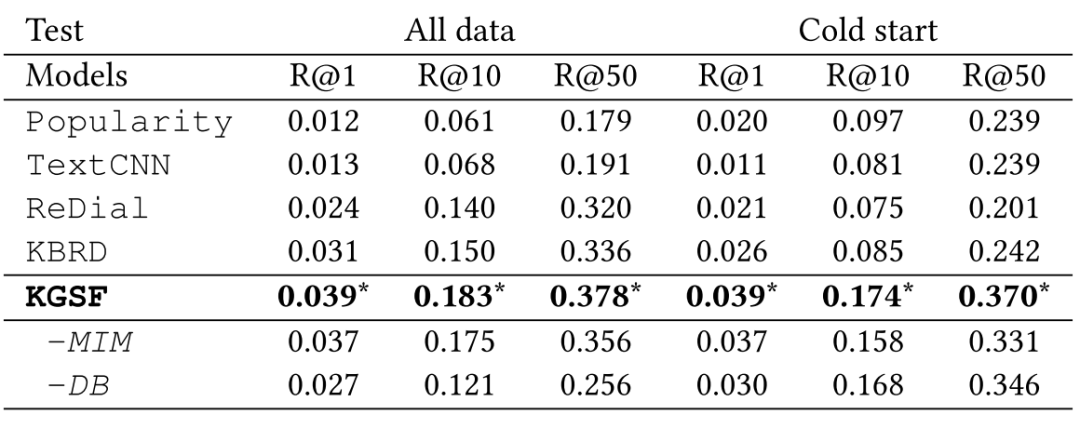
可以看到,不论是在常规推荐场景下还是冷启动(上下文未提及任何商品或属性)场景下,KGSF都能取得最优表现。
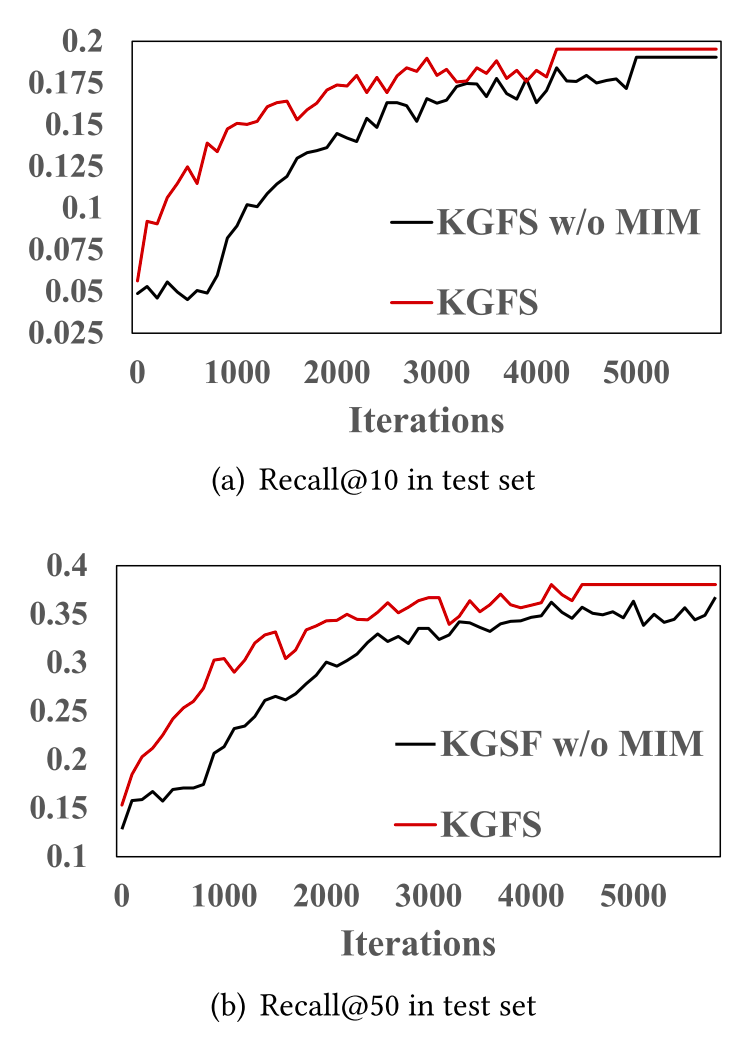
MIM模块在提升模型表现的同时,也能缩短模型的收敛时间。
3.3.2 对话生成任务
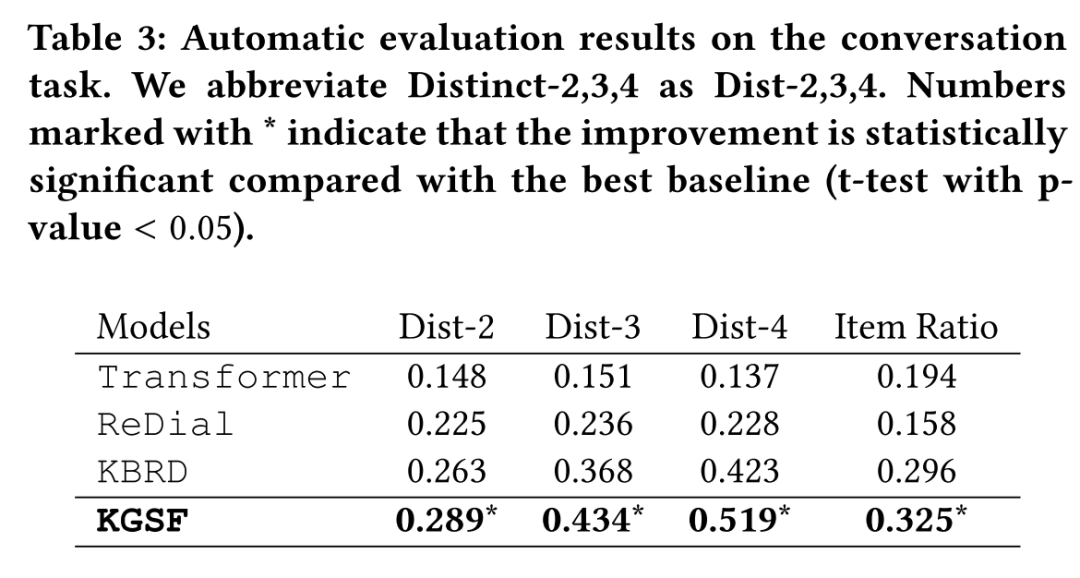
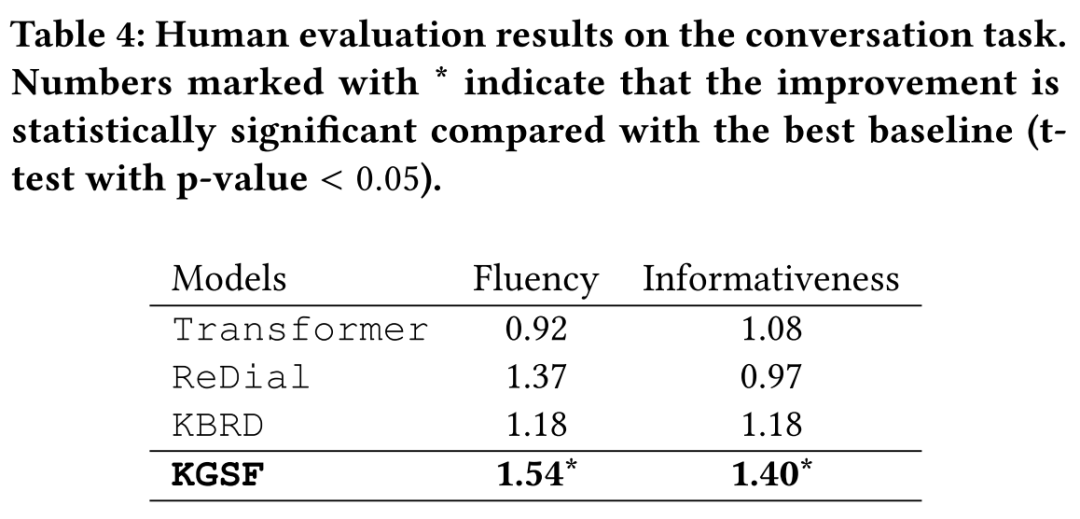
KGSF在对话生成任务上也能取得最优效果。
4 总结
本文介绍的第一篇工作研究如何将有模态缺失问题的多模态数据集构建成为异质图并在图上进行合理的多模态信息交互,达到相互补充与融合的效果;第二篇工作则在引入面向word以及面向item的两个知识图谱后,通过互信息最大化对齐这两个知识图谱在语义上的表示空间,从而提升会话推荐效果。
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!




