学界 | 微软亚洲研究院CVPR 2017 Oral论文:逐层集中Attention的卷积模型
选自CVPR 2017
机器之心编译
参与:Smith、路雪、蒋思源
通过计算机视觉方法识别纹理细密的物体种类已经受到了学界的强烈关注。这一类任务往往是极具挑战性的,这是因为一些纹理细密的物体种类只能被该领域的专家所识别出来。与一般的识别不同,细粒度图像识别(fine-grained image recognition)是应该能够进行局部定位(localizing),并且能在其从属(subordinate)类别中表征很小的视觉差异的,从而使各种应用受益,比如专家级的图像识别、图像标注等等。
微软亚洲研究院梅涛研究员等人发表的论文是本次 CVPR 大会的亮点之一。
论文:Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition

论文链接:http://openaccess.thecvf.com/content_cvpr_2017/papers/Fu_Look_Closer_to_CVPR_2017_paper.pdf
识别纹理细密的物体类别(比如鸟类)是很困难的,这是因为判别区域定位(discriminative region localization)和细粒度特征学习(fine-grained feature learning)是很具有挑战性的。现有方法主要都是单独地来解决这些挑战性问题,然而却忽略了区域检测(region detection)和细粒度特征学习之间的相互关联性,而且它们可以互相强化。本篇论文中,我们提出了一个全新的循环注意力卷积神经网络(recurrent attention convolutional neural network——RA-CNN),用互相强化的方式对判别区域注意力(discriminative region attention)和基于区域的特征表征(region-based feature representation)进行递归学习。在每一尺度规模上进行的学习都包含一个分类子网络(classification sub-network)和一个注意力建议子网络(attention proposal sub-network——APN)。APN 从完整图像开始,通过把先期预测作为参考,由粗到细迭代地生成区域注意力,同时精调器尺度网络(finer scale network)以循环的方式从先前的尺度规格输入一个放大的注意区域(amplified attended region)。RA-CNN 通过尺度内分类损失(intra-scale classification loss)和尺度间排序损失(inter-scale ranking loss)进行优化,以相互学习精准的区域注意力和细粒度表征。RA-CNN 并不需要边界框或边界部分的标注,而且可以进行端到端的训练。我们实施了综合性实验,实验证明 RA-CNN 在 3 个细粒度任务中均表现不俗,在 CUB Birds,Stanford Dogs 和 Stanford Cars 上的相对精度增益分别为 3.3%、3.7%、3.8%。
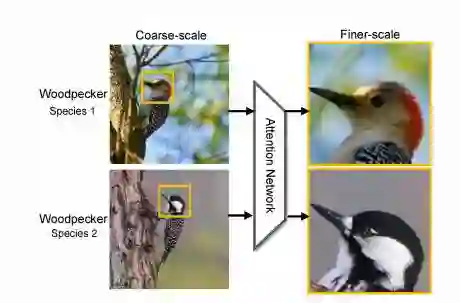
图 1. 两种啄木鸟。我们可以从高度局部区域(highly local regions),比如黄色框里的头部,观察到非常不易察觉的视觉差异,这是难以在原始图像规格中进行学习的。然而,如果我们可以学着去把注意区域放大到一个精细的尺度,差异可能就会更加生动和显著。
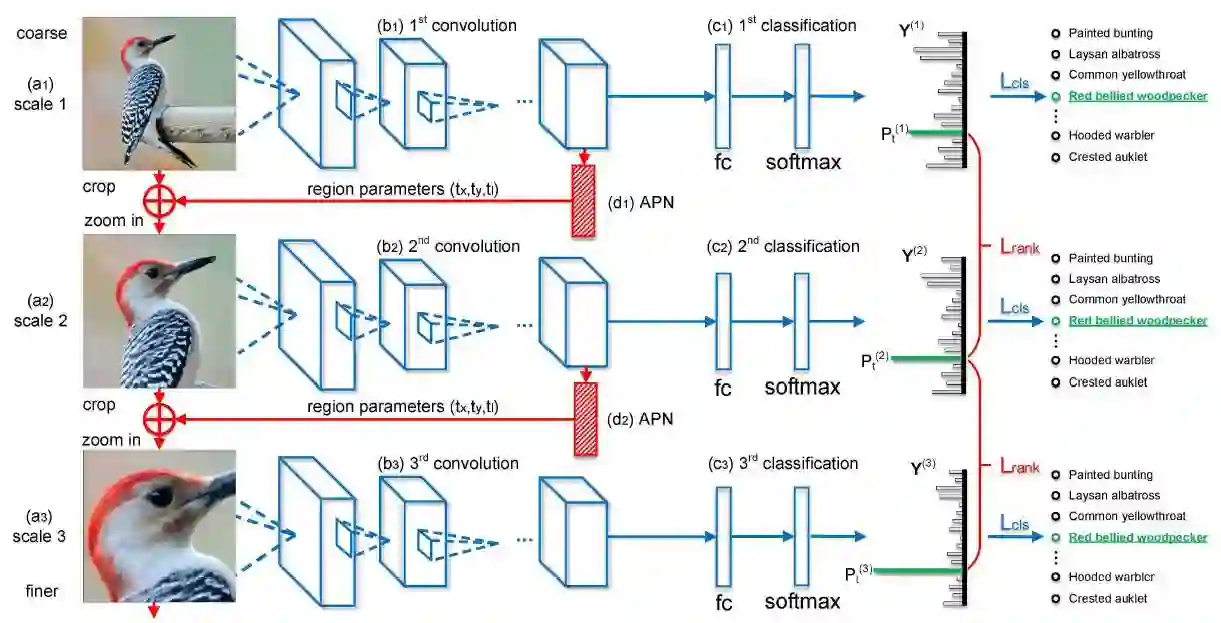
图 2. 循环注意力卷积神经网络的框架。
输入图像从上到下按粗糙的完整大小的图像到精炼后的区域注意力图像排列。不同的网络分类模块(蓝色部分)通过同一尺度的标注预测 Y(s) 和真实 Y∗之间的分类损失 Lcl 进行优化,注意力建议(红色部分)通过相邻尺度的 p (s) t 和 p (s+1) t 之间的成对排序损失 Lrank(pairwise ranking loss Lrank)进行优化。其中 p (s) t 和 p (s+1) t 表示预测在正确类别的概率,s 代表尺度。APN 是注意力建议网络,fc 代表全连接层,softmax 层通过 fc 层与类别条目(category entry)匹配,然后进行 softmax 操作。+代表「剪裁(crop)」和「放大(zoom in)」。
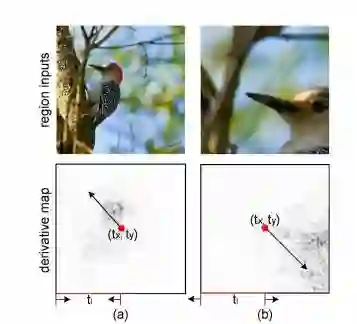
图 3. 区域注意力学习的相关说明。顶行指明了特定尺度下的两个典型区域输入,底行指明了反向传播到输入层的导数。黑色箭头显示了 tx、ty 和 tl 的优化方向,与人类的感知是一致的。

图 4. 不同尺度规格下,已学习区域注意力的五种鸟类。在逐渐放大到注意力区域(attended region)后,我们可以观察到清晰且显著的分类视觉线索。

表 2. 在 CUB-200-2011 数据集上,关于分类精度的注意力局部的对比。
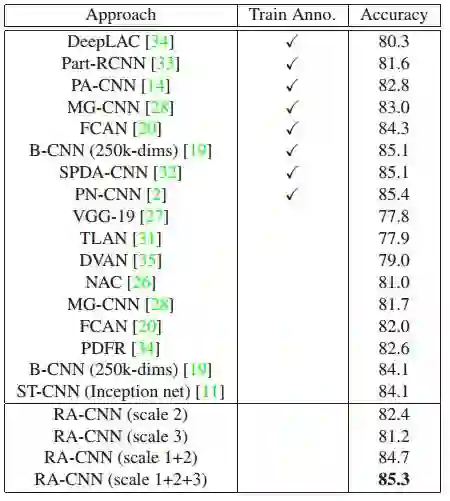
表 3. CUB-200-2011 数据集上的对比结果。Train Anno. 代表在训练中使用边界框或部分标注。

图 5. 在第三尺度规格对鸟类、狗类和猫类进行注意力定位。
从多种图像样本中进行学习的区域(每一行),都代表一个特定细粒度类别下的一致性注意力区域,可以从其它种类中对该类别进行辨别分类。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击阅读原文,查看机器之心官网↓↓↓