新设备:用个人电脑就能处理大规模图数据!
导读
近日,美国麻省理工学院计算机科学与人工智能实验室(CSAIL)设计出一种新设备,采用了在智能手机中使用的廉价闪存(Flash),只需要一台个人电脑就可以处理大规模图数据。
背景
如今,人类已进入大数据时代。在大数据时代,我们需要更加快速、有效、节能地处理和存储数据。
下面,让我们先来认识一种特殊的数据结构:图(graph),它是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。在图中的数据元素,我们称之为顶点(Vertex),顶点集合有穷非空。在图中,任意两个顶点之间都可能有关系,顶点之间的逻辑关系用边来表示,边集可以是空的。
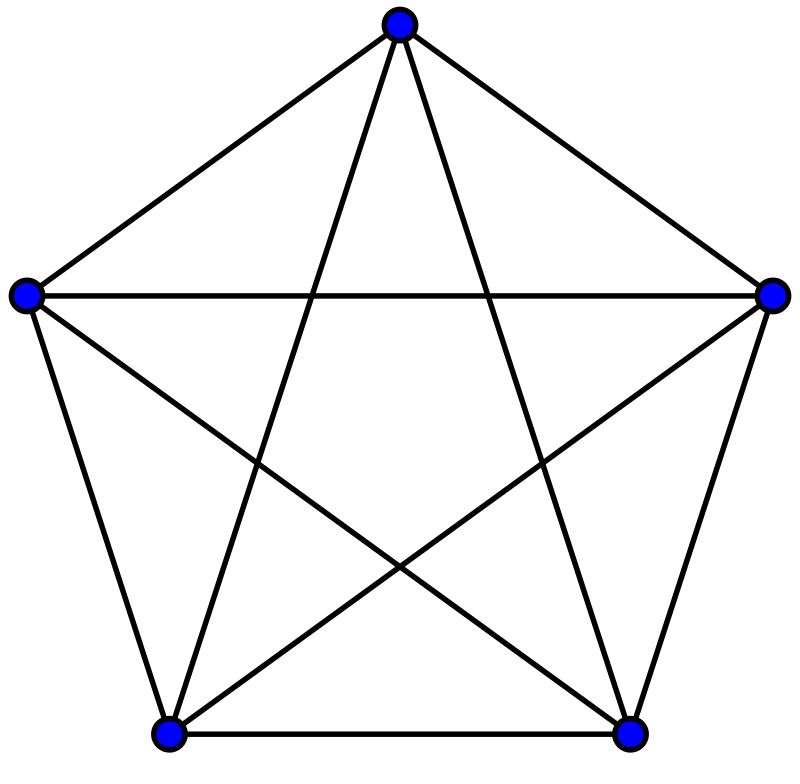
(图片来源:维基百科)
分析图这种数据结构将带来广泛的应用,例如:网页排名、社交网络分析、大脑中神经结构的绘制等等。然而,大型的图可以由数以亿记的顶点与边组成,其数据容量可以达到太字节。一般来说,图的数据处理需要多个耗电的服务器,在昂贵的动态随机存取存储器(DRAM)中进行。
创新
近日,美国麻省理工学院计算机科学与人工智能实验室(CSAIL)设计出一种新设备,采用了在智能手机中使用的廉价闪存(Flash),只需要一台个人电脑就可以处理巨型的图。

(图片来源:MIT)
一般来说,在图的数据处理方面,Flash比DRAM慢许多。但是,研究人员开发出一种由Flash芯片阵列和计算“加速器”组成的设备,有望帮助Flash达到类似DRAM的性能。
这个设备强大之处在于一个新算法,它可以将图的所有数据访问请求,排序为顺序次序,便于Flash快速简单地访问。它也可以合并一些请求来减少排序开销(计算时间、存储器、带宽和其他计算资源的结合)。
描述该设备的相关论文发表于计算机体系结构国际研讨会(ISCA)。
技术
研究人员将设备处理几种巨型图的表现,与几个传统的高性能系统相比较,这些大型图包括巨型的网络数据共享超链接图(Web Data Commons Hyperlink Graph),它含有35亿个顶点和1280亿条边。为了处理这个图,传统的系统都需要价值几千美元且含有128吉字节DRAM的服务器。然而,研究人员将两个设备(1吉字节的DRAM和1太字节的Flash)插入到计算机中,就实现了同样的性能。更进一步说,通过结合几个设备,他们可以处理的巨型图将达到40亿个顶点和1280亿条边,而128吉字节服务器上的其他系统无法处理这种巨型图。
(图片来源:MIT)
论文第一作者、CSAIL 研究生 Sang-Woo Jun 表示:“底线是,我们能够通过更小、更少、更冷(温度和功耗方面)的机器保持住性能。”
论文合著者之一、计算机科学工程系教授 Arvind 表示:“图处理是一个非常普遍的想法。网页排名与基因检测有什么共同之处?对于我们来说,它们是同一个计算问题,只是不同的图具有不同的意义。开发出的应用程序的类型将决定它对社会的影响。”
在图分析中,一个系统主要基于该顶点与其他顶点之间的联系,搜索并更新顶点的值。例如,在网页排名中,每个顶点代表一个网页。如果顶点A具有很高的值,并连接到顶点B,然后顶点B的值也会增加。
传统系统将所有的图数据存储于DRAM中,从可以更快速地处理数据,但是这样也会增加成本和能耗。某些系统会将一些数据存储到Flash中,虽然Flash更加便宜,但是它却更慢且效率更低。研究人员设计出的设备运行于他们称为“排序-归约”(sort-reduce)的算法之上,这种算法解决了采用Flash作为主存储源的主要问题:浪费。
图分析系统需要跨越海量稀疏的图结构,访问相互之间距离非常遥远的顶点。系统通常需要直接访问4到8个字节的数据来更新顶点值。DRAM提供了一种非常快速的直接访问。然而,对于Flash来说,只能在4千字节到8千字节的数据块中访问数据,但仍然只是更新几个字节的数据。对于每次请求,跨越巨型的图反复访问,会浪费带宽。Jun 表示:“如果你需访问整个的8千字节,却只使用8字节,并丢弃其余的,你最终将丧失1000倍的性能。”
取而代之的是,“排序-归约”算法会接收所有的直接访问请求,并通过标识符将它们按顺序排列。标识符显示出请求的目的地,例如将对于顶点A的所有更新分为一组,然后顶点B的再分为一组,以此类推。然后,Flash 可以一次响应几千次请求,访问千字节大小的数据块,从而使得效率提高许多。
为了进一步节约计算机的能耗与带宽,算法同步地将数据结合到最小的分组中。无论算法什么时候记录匹配的标识符,都会将那些加到单个数据包中,例如A1和A2变成A3。它持续地这么做,创造出越来越小的含有匹配标识符的数据包,直到创造出最小的数据包用于排序。这样可以显著地减少重复请求的访问量。
在两个巨型图上采用“排序-归约”算法,研究人员将Flash中需要更新的数据总量减少了约90%。
“排序-归约”算法对于主机来说是计算密集型的,然而研究人员在设备中实现了一个定制的加速器。加速器可作为主机和Flash芯片之间的中间点,为算法执行所有的计算。这样使得许多功耗都由加速器来承担,从而可以采用一个低功耗的个人电脑或笔记本电脑充当主机,管理经过排序的数据和执行其他小型任务。Arvind 表示:“加速器可以帮助主机计算,但是我们已经【通过计算】取得了很大进展,主机已变得不那么重要。”
价值
在一系列应用中,这种新型设备可用于降低与图分析相关的成本和能耗,甚至改善性能。例如,研究人员目前正在设计一个可以识别引发癌症的基因的程序。大型技术公司例如谷歌,利用这种设备可以降低能源足迹,因为运行这种分析所需的机器要少很多。
美国德克萨斯大学阿灵顿分校的计算机科学教授 Keshav Pingali 表示:“MIT 的研究展示了一种在巨型图上展开分析的新途径。他们研究利用Flash存储图,并利用‘现场可编程门阵列’【定制集成电路】以一种巧妙的方法展开分析和数据处理,从而更有效地利用Flash。从长远来看,这将带来能在笔记本电脑或台式机上更加有效地处理大量数据的系统,变革我们处理大数据的方法。”
Jun 表示,因为主机的功耗可以变得如此的低,长期目标就是为客户创造出通用平台和软件库,使他们可以为图分析以外的应用开发自己的算法。他说:“你可以将这个平台插入到笔记本电脑中,下载【软件】,并在你的笔记本电脑上写一些简单程序,获取某些服务器类的性能。”
关键字
参考资料
【1】http://news.mit.edu/2018/device-allows-personal-computer-process-huge-graphs-0531

了解更多前沿技术文章,请点击“阅读原文”。咨询和交流,请联系微信:JohnZh1984



