实体链接:信息抽取中的NLP的基础任务

作者:Sundar V
编译:ronghuaiyang
构建知识库的必备技能之一。
我相信大多数人都遇到过命名实体识别(NER)。NER是一种基本的自然语言处理(NLP)任务,具有广泛的用例。本文不是关于NER的,而是关于一个与NER密切相关的NLP任务。
**你知道什么叫实体链接吗?它如何帮助信息提取、语义Web和许多其他任务?**如果没有,也不要担心。本文将回答这些问题,并提供一个基本的NEL实现。
在研究NEL之前,我们首先要了解信息提取。根据维基百科,
”信息提取是从非结构化和/或半结构化文档中自动提取结构化信息的任务。在大多数情况下,这个活动是通过NLP来处理人类语言文本。“
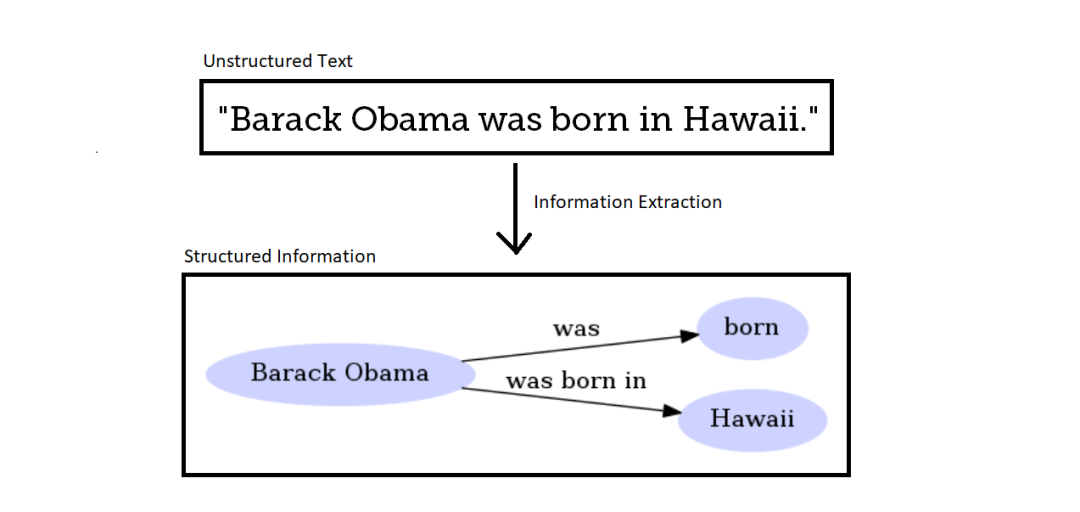
在下面的信息抽取示例中,将非结构化文本数据转换为结构化语义图。信息提取的一个通用的目标是从非结构化数据中提取知识,并将获得的知识用于各种其他任务。
什么是命名实体链接?
信息提取由多个子任务组成。在大多数情况下,我们将有以下子任务。它们的执行是为了,从非结构化数据中提取信息。
-
命名实体识别(NER) -
命名实体链接(NEL) -
关系抽取
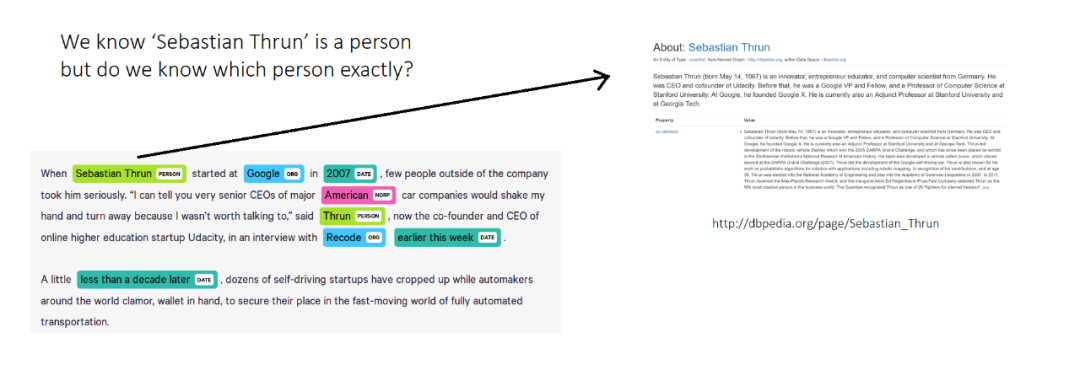
一个命名的实体是一个真实世界的对象,比如人,地点,组织,等等。NER识别并将文本中出现的命名实体分类为预定义的类别。NER被建模为为句子中的每个单词分配标签的任务。下面是一个来自NER系统的示例结果。

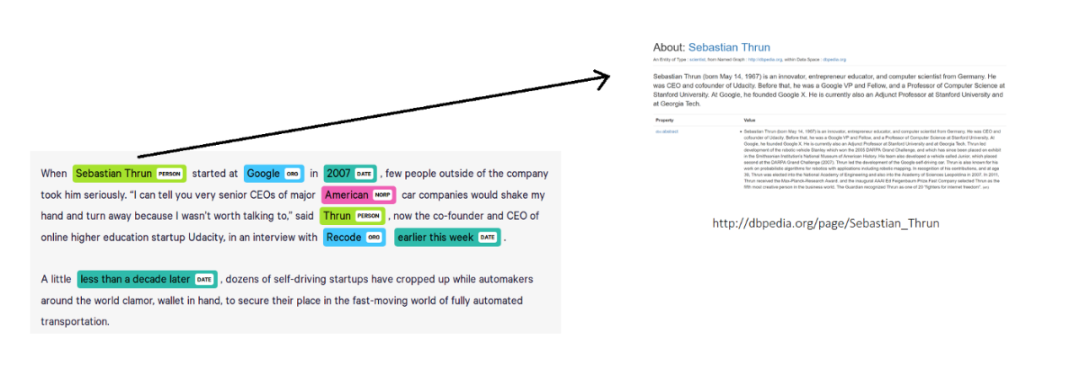
NER会告诉我们哪些词是实体以及它们的类型。在上面的例子中,NER会把“Sebastian Thrun”标记为person。但我们仍然不知道确切的“Sebastian Thrun”文本在上面的例子中说的是哪个人。NEL是将回答这个问题的下一个子任务。
NEL将为文中提到的实体分配唯一标识。换句话说,NEL是将文本中提到的实体与知识库中对应的实体链接起来的任务。目标知识库取决于应用,但是我们可以为开放域文本使用来自Wikipedia的知识库。在上面的示例中,通过将实体链接到DBpedia,我们可以找到确切的“Sebastian Thrun”。DBpedia是从Wikipedia中提取的结构化知识库。将实体链接到维基百科的过程也称为维基化。
NEL也被称为实体链接、命名实体消歧(NED)、命名实体识别和消歧(NERD)或命名实体规范化(NEN)。NEL除了信息提取外,还有广泛的应用。NEL应用于信息检索、内容分析、智能标注、问题回答系统、推荐系统等。
NEL在语义Web中也扮演着重要的角色。语义web是由Tim Berners-Lee创造的一个术语,指可以由机器处理的数据网络。语义Web的一个关键问题是用新提取的事实自动填充和丰富现有的知识库。NEL本质上被认为是知识库群体的基本子任务。
使用DBpedia Spotlight实现NEL
有许多库可用于实现NEL,但这里我们将使用DBpedia Spotlight。这里NEL的目标知识库是DBpedia。DBpedia Spotlight是一个使用DBpedia uri自动注释文本文档的系统,开发它是为了将文档Web与数据Web互连。
DBpedia Spotlight被部署为Web服务,我们可以使用提供的Spotlight API来实现NEL。你甚至可以检查DBpedia Spotlight服务器的状态。下面是一个使用Spotlight API执行NEL的python客户端的例子。
import requests
from IPython.core.display import display, HTML# An API Error Exception
class APIError(Exception):def __init__(self, status):
self.status = statusdef __str__(self):
return "APIError: status={}".format(self.status)
# Base URL for Spotlight API
base_url = "http://api.dbpedia-spotlight.org/en/annotate"# Parameters
# 'text' - text to be annotated
# 'confidence' - confidence score for linking
params = {"text": "My name is Sundar. I am currently doing Master's in Artificial Intelligence at NUS. I love Natural Language Processing.", "confidence": 0.35}# Response content type
headers = {'accept': 'text/html'}# GET Request
res = requests.get(base_url, params=params, headers=headers)
if res.status_code != 200:
# Something went wrong
raise APIError(res.status_code)# Display the result as HTML in Jupyter Notebook
display(HTML(res.text))
Output:
My name is Sundar. I am currently doing Master’s in Artificial Intelligence at NUS. I love Natural Language Processing.
正如你在上面的例子中看到的,DBpedia Spotlight正在将定位的实体链接到DBpedia知识库。因此,我们得到了带标注的文本。Spotlight支持多种语言和多种响应内容类型,包括HTML、JSON、XML、N-Triples等。如果你不熟悉Spotlight API,可以使用DBpedia Spotlight的REST接口编写的公开包装器。
通用的方法
由于名称变化和歧义问题,NEL不是一个简单的任务。命名多样化是指一个实体可以以不同的方式被提及。例如,实体Michael Jeffrey Jordan可以使用许多名字来指代,如Michael Jordan、MJ和 Jordan。然而,歧义问题与这样一个事实有关,即名称可能根据上下文引用不同的实体。这里有一个模棱两可的例子,名字 Bulls 可以在维基百科中应用到多个实体,如NBA球队Chicago Bulls,橄榄球球队Belfast Bulls等。
一般来说,一个典型的实体链接系统由候选实体生成、候选实体排序和不可链接的提及预测三个模块组成。下面给出了每个模块的简要描述。
-
候选实体生成 —— 在这个模块中,NEL系统的目标是通过过滤知识库中不相关的实体来检索一组候选实体。检索到的集合包含可能引用实体提到的实体。 -
候选实体排名 —— 在这里,利用不同种类的证据对候选实体进行排名,以找到最可能的实体。 -
不可链接的提及预测 —— 此模块将验证前一个模块中确定的排名最高的实体是否是给定提及的目标实体。如果不是,那么它会返回NIL。基本上,这个模块处理不可链接的提及。
回到spotlight。DBPedia spotlight使用Apache OpenNLP标识提到的实体。Spotlight中的消歧使用生成概率模型进行。
NEL是一项重要的NLP任务,应该给予更多的重视。最近,人们开始使用深度学习技术来提高NEL系统在标准数据集上的性能。我相信,今天出现的大量链接开放数据为未来的人工智能提供了一个难以置信的机会。考虑到NEL在信息提取和语义Web中的作用,我们需要在这方面做更多工作。

英文原文:https://medium.com/analytics-vidhya/entity-linking-a-primary-nlp-task-for-information-extraction-22f9d4b90aa8
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




