想吃透监控系统,就这一篇够不够?
经济高速发展的今天,我们处于信息大爆炸的时代。随着经济发展,信息借助互联网的力量在全球自由地流动,于是就催生了各种各样的服务平台和软件系统。

图片来自 Pexels
由于业务的多样性,这些平台和系统也变得异常的复杂。如何对其进行监控和维护是我们 IT 人需要面对的重要问题。就在这样一个纷繁复杂地环境下,监控系统粉墨登场了。
今天,我们会对 IT 监控系统进行介绍,包括其功能,分类,分层;同时也会介绍几款流行的监控平台。
监控系统的功能
在 IT 运维过程中,常遇到这样的情况:
某个业务模块出现问题,运维人员并不知道,发现的时候问题已经很严重了。
系统出现瓶颈了,CPU 占用持续升高,内存不足,磁盘被写满;网络请求突增,超出网关承受的压力。
以上这些问题一旦发生,会对我们的业务产生巨大的影响。因此,每个公司或者 IT 团队都会针对此类情况建立自己的 IT 监控系统。
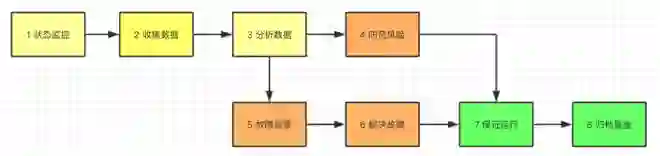
监控系统工作流程图
对服务,系统,平台的运行状态实时监控。
收集服务,系统,平台的运行信息。
通过收集信息的分析结果,预知存在的故障风险,并采取行动。
根据对风险的评估,进行故障预警。
一旦发生故障,第一时间发出告警信息。
通过监控数据,定位故障,协助生成解决方案。
最终保证系统持续、稳定、安全运行。
监控数据可视化,便于统计,按照一定周期导出、归档,用于数据分析和问题复盘。
监控系统的分类
日志类
调用链类
度量类
日志类
这些信息会与事件做相关,例如:用户登录,下订单,用户浏览某件商品,一小时以内的网关流量,用户平均响应时间等等。
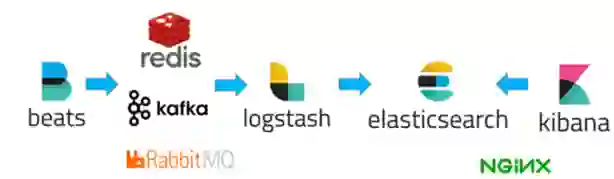
这类以日志的记录和查询的解决方案比较多。比如 ELK 方案(Elasticsearch+Logstash+Kibana),使用ELK(Elasticsearch、Logstash、Kibana)+Kafka/Redis/RabbitMQ 来搭建一个日志系统。
调用链类
①Java 探针,字节码增强
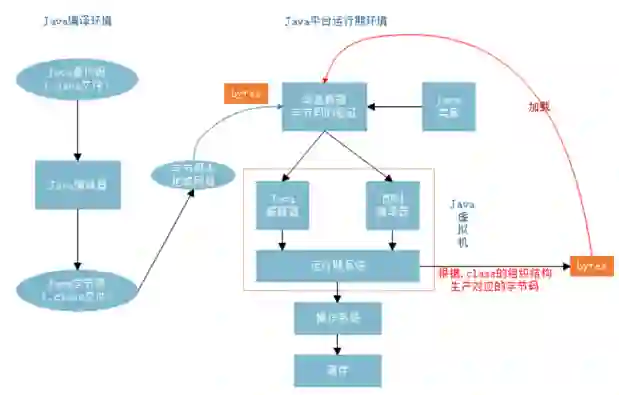
最后将相应耗时文件取下来,转化为 xml 格式并进行解析,通过浏览器将代码分层结构展示出来。
Sleuth 提供链路追踪。由于一个请求会涉及到多个服务的互相调用,而这种调用往往成链式结构,经过多次层层调用以后请求才会返回。常常使用 Sleuth 追踪整个调用过程,方便理清服务间的调用关系。

Server Received 是服务器接受,也就是服务端接受到请求的意思。
Client Sent 是客户端发送,也就是这个服务本身不提供响应,需要调用其他的服务提供该响应,所以这个时候是作为客户端发起请求的。
Server Sent 是服务端发送,看上图SERVICE 3 收到请求后,由于他是最终的服务提供者,所以作为服务端,他需要把请求发送给调用者。
Client Received 是客户端接受,作为发起调用的客户端接受到服务端返回的请求。
每次发起请求或者接受请求的状态分别记录成 Server Received,Client Sent,Server Sent,Client Received 四种状态来完成这个服务调用链路的跟踪的。

度量类
整个监控的数据库称为“Metric”,它包含了所有监控的数据。类似关系型数据库中的 Table。
每条监控数据,称为“Point”,类似于关系型数据库中的 Row 的概念。
每个“Point”都会定义一个时间戳“Timestamp”,将其作为索引,表明数据采集的时间。
“Tag”作为维度列,表示监控数据的属性。
“Field”作为指标列,作为测量值,也就是测量的结果。

接收写入请求的 memtable 文件(内存中)
不可修改的 immutable memtable 文件(内存中)
磁盘上的 SStable文件(Sorted String Table),有序字符串表,这个有序的字符串就是数据的key。SStable 一共有七层(L0 到 L6)。下一层的总大小限制是上一层的 10 倍。
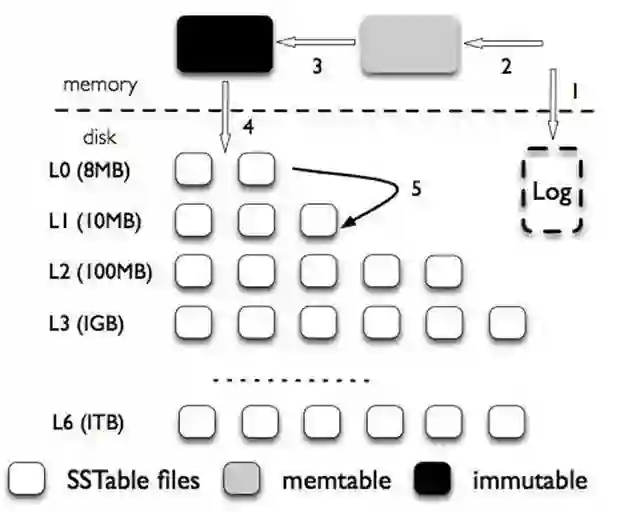
将数据追加到日志 WAL(Write Ahead Log)中,写入日志的目的是为了防止内存数据丢失,可以及时恢复。
把数据写到 memtable 中。
当 memtable 满了(超过一定阀值),就将这个 memtable 转入 immutable memtable 中,用新的 memtable 接收新的数据请求。
immutablememtable 一旦写满了, 就写入磁盘。并且先存储 L0 层的 SSTable 磁盘文件,此时还不需要做文件的合并。
每层的所有文件总大小是有限制的(8MB,10MB,100MB… 1TB)。从 L1 层往后,每下一层容量增大十倍。
某一层的数据文件总量超过阈值,就在这一层中选择一个文件和下一层的文件进行合并。
如此这般上层的数据都是较新的数据,查询可以从上层开始查找,依次往下,并且这些数据都是按照时间序列存放的。
监控系统的分层

客户端监控,用户行为信息,业务返回码,客户端性能,运营商,版本,操作系统等。
业务层监控,核心业务的监控,例如:登录,注册,下单,支付等等。
应用层监控,相关的技术参数,例如:URL 请求次数,Service 请求数量,SQL 执行的结果,Cache 的利用率,QPS 等等。
系统层监控,物理主机,虚拟主机以及操作系统的参数。例如:CPU 利用率,内存利用率,磁盘空间情况。
网络层监控,网络情况参数。例如:网关流量情况,丢包率,错包率,连接数等等。
流行的监控系统
Zabbix
Prometheus
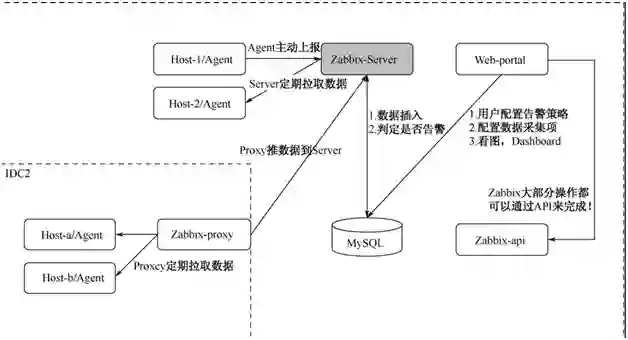
Zabbix
Agent 负责收集数据,并且传输给 Server。
Server 负责接受 Agent 的数据,进行保存或者告警。
Proxy 负责代理 Server 收集 Agent 传输的数据,并且转发给 Server。Proxy 是安装在被监控的服务器上的,用来和 Server 端进行通信,从而传输数据。
Prometheus(普罗米修斯)
Prometheus Server,用于收集和存储时间序列数据,负责监控数据的获取,存储以及查询。
监控目标配置,Prometheus Server 可以通过静态配置管理监控目标,也可以配合 Service Discovery(K8s,DNS,Consul)实现动态管理监控目标。
监控目标存储,Prometheus Server 本身就是一个时序数据库,将采集到的监控数据按照时间序列存储在本地磁盘中。
监控数据查询,Prometheus Server 对外提供了自定义的 PromQL 语言,实现对数据的查询以及分析。
Client Library,客户端库。为需要监控的服务生成相应的 Metrics 并暴露给 Prometheus Server。
当 Prometheus Server 来 Pull 时,直接返回实时状态的 Metrics。通常会和 Job 一起合作。
Push Gateway,主要用于短期的 Jobs。由于这类 Jobs 存在时间较短,可能在 Prometheus 来 Pull 之前就消失了。为此,这些 Jobs 可以直接向 Prometheus Server 端推送它们的 Metrics。
Exporters,第三方服务接口。将 Metrics(数据集合)发送给 Prometheus。
Exporter 将监控数据采集的端点,通过 HTTP 的形式暴露给 Prometheus Server,使其通过 Endpoint 端点获取监控数据。
Alertmanager,从 Prometheus Server 端接收到 Alerts 后,会对数据进行处理。例如:去重,分组,然后根据规则,发出报警。
Web UI,Prometheus Server 内置的 Express Browser UI,通过 PromQL 实现数据的查询以及可视化。

Prometheus Server 定期从 Jobs/Exporters 中拉 Metrics。同时也可以接收来自 Pushgateway 发过来的 Metrics。
Prometheus Server 将接受到的数据存储在本地时序数据库,并运行已定义好的 alert.rules(告警规则),一旦满足告警规则就会向 Alertmanager 推送警报。
Alertmanager 根据配置文件,对接收到的警报进行处理,例如:发出邮件告警,或者借助第三方组件进行告警。
WebUI/Grafana/APIclients,可以借助 PromQL 对监控数据进行查询。
最后将两个工具进行比较如下:
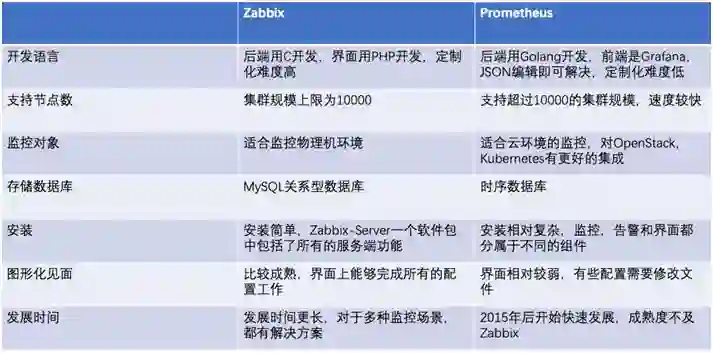
Zabbix 的成熟度更高,上手更快。高集成度导致灵活性较差,在监控复杂度增加后,定制难度会升高。而且使用的关系型数据库,对于大规模的监控数据插入和查询是个问题。
Prometheus 上手难度大,定制灵活度高,有较多数据聚合的可能,而且有时序数据库的加持。
对于监控物理机或者监控环境相对稳定的情况,Zabbix 有明显优势。如果监控场景多是云环境的话,推荐使用 Prometheus。
总结

简介:十六年开发和架构经验,曾担任过惠普武汉交付中心技术专家,需求分析师,项目经理,后在创业公司担任技术/产品经理。善于学习,乐于分享。目前专注于技术架构与研发管理。
编辑:陶家龙、孙淑娟
征稿:有投稿、寻求报道意向技术人请联络 editor@51cto.com

精彩文章推荐: