BERT轻量化:最优参数子集Bort,大小仅为BERT-large16%
郑集杨 发自 凹非寺
量子位 报道 | 公众号 QbitAI
近期,亚马逊 Alexa 团队发布了一项研究成果:研究人员对BERT模型进行参数选择,获得了BERT的最优参数子集——Bort。
研究结果表明,Bort大小仅为BERT-large的16%,但是在CPU上的速度却快了7.9倍,在NLU基准测试上的性能也优于BERT-large。
这是在NLP模型快速“膨胀”,模型轻量化迫切需求的背景下,一次比较成功的结果。
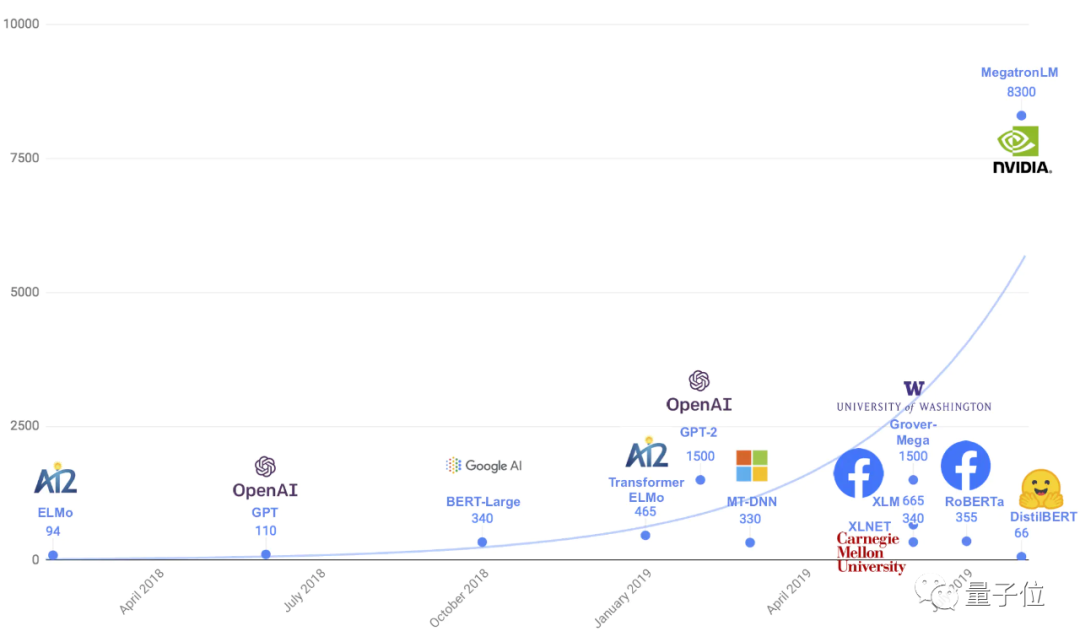
NLP模型大小 △图源:DistilBERT
与ALBERT、MobileBERT进行的模型结构优化不同,Bort是在原本的模型架构上进行最优子集选择。
简单来说就是:「瘦身」。
那么,研究人员又是怎么给BERT「瘦身」的呢?
接下来便让我们带大家来仔细看看。
FPTAS助力「瘦身」
首先需要明确的是,这并不是研究人员第一次尝试给BERT「瘦身」了。
因为BERT的规模大,推理速度慢,并且预处理过程复杂,所以先前已经有部分研究人员便尝试对其进行瘦身,取得了一定的成果:保持了其前身的相同性能、简化了预训练过程同时减少了推理时间。
不过,在准确性上,瘦身后的子集总是不太尽如人意——达不到原本BERT的性能。

而这次的研究,研究人员使用了完全多项式时间近似算法(FPTAS)进一步优化这个问题,因为该算法最近被证明:在某些条件下,能够有效地提取此类最优子集。
对此,研究人员说道:
这种条件被称为strong AB^nC propert,我们证明了BERT满足了这一组条件。
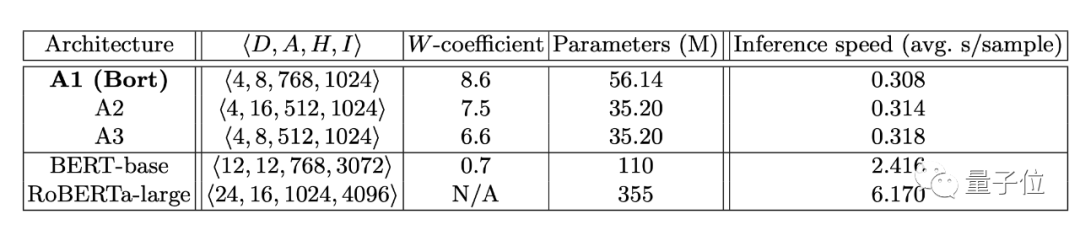
研究人员列举了三个指标:推理速度,参数大小和错误率,在使用FPTAS下,从一个高性能的BERT中提取一个最优子集,这便是Bort。
在随后初步的测试中,Bort有着不俗的表现。在CPU上,其执行推理的速度比BERT-large快了7.9倍。
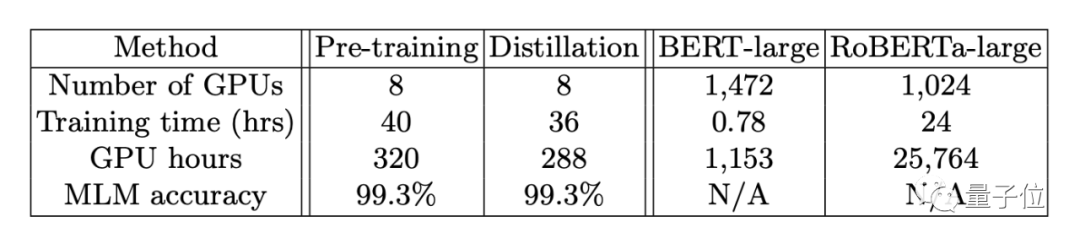
此外,在相同的硬件上,对相同的数据集进行预训练,Bort只花费了288个GPU hours。而相比之下,BERT-large花费了1153个GPU hours,而RoBERTa-large则需要25764个GPU hours。
「瘦身」成功!
变「瘦」了,也变强了
瘦身后,是不是就像之前类似的研究一样,能力下降了呢?这是一个非常关键的问题。
为了验证Bort的泛化能力,研究人员在GLUE和SuperGLUE基准以及RACE数据集上对Bort同其他模型进行了测试。
首先是在GLUE上测试:
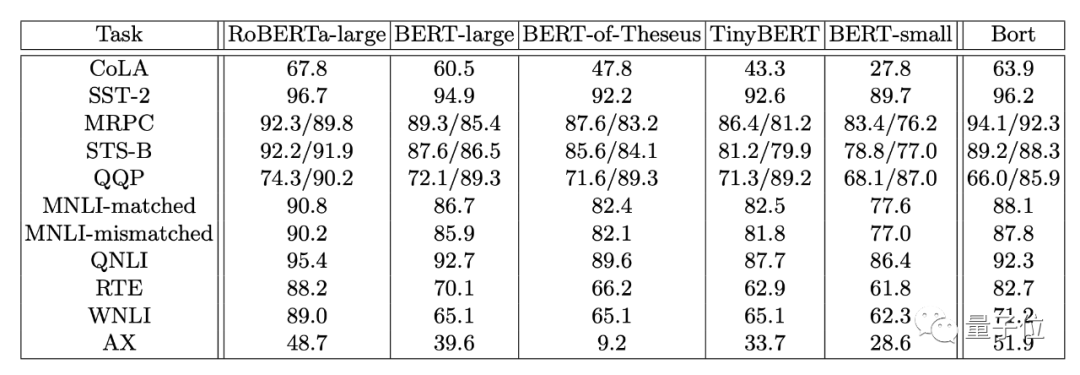
Bort在几乎所有任务中都取得了优异的成绩:除了QQP和QNLI之外,它的性能都比其他几个同样基于BERT的同类模型好得多。
值得一提的是,对于BERT-large而言,Bort的性能提高了0.3%至31%。
其次是在SuperGLUE上的测试:
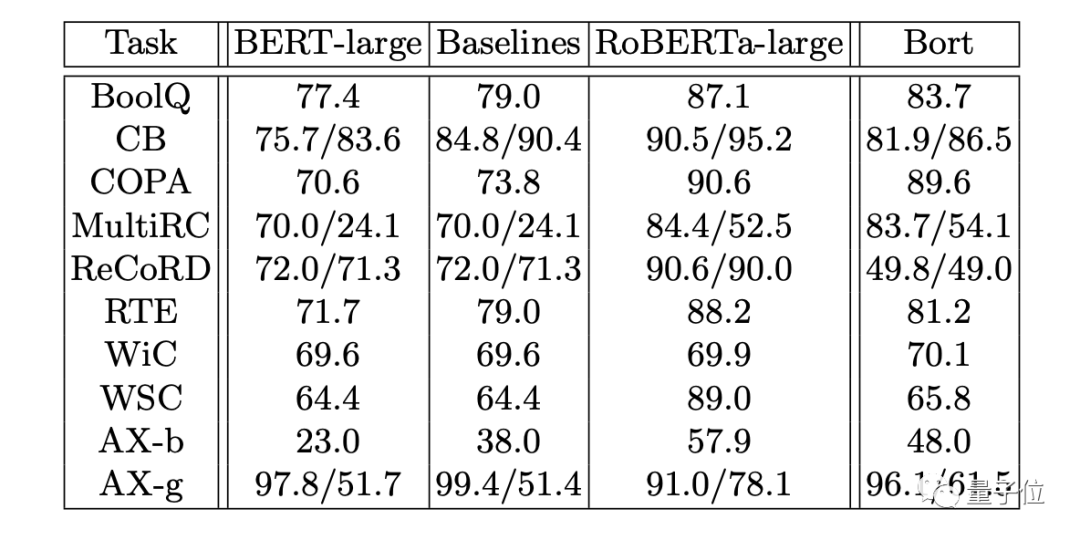
Bort同样取得了不错的成绩,除了一项任务(ReCoRD)之外,其他所有任务上都展现了优于或等同于BERT-large的性能。
最后,是在RACE上的测试:
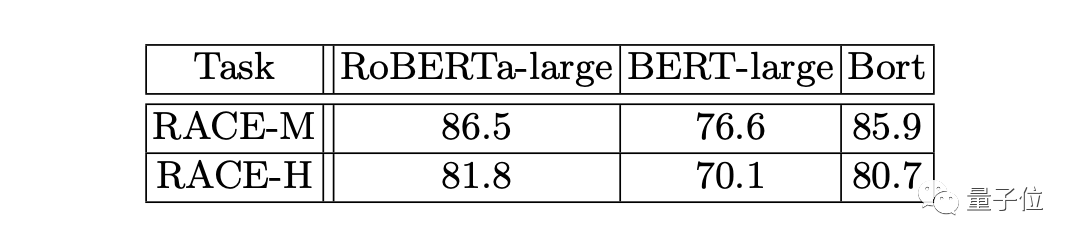
总的来说,Bort获得了良好的结果,在这两项任务上的性能比BERT-large高出9-10%。
对于NLU测试结果,研究人员总结道:
在GLUE,SuperGLUE和RACE的NLU基准测试上,Bort相对于BERT-large在各个方面的性能都有着提升,范围从0.3%到31%不等。
最后,研究人员还在Github公布了Bort的代码。论文和代码地址如下,需要的读者自取哦。
论文链接:
https://arxiv.org/pdf/2010.10499.pdf
代码地址:
https://github.com/alexa/bort
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
量子位年度智能商业峰会启幕,
李开复等AI大咖齐聚,
邀你共探新形势下智能产业发展之路


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~


