GNNets:自然场景下文字检测的几何归一化网络 | ICCV 2019

作者 | 商汤科技
编辑 | 唐里
本文简要介绍商汤科技研究团队在 ICCV2019 上录用的一篇文章:Geometry NormalizationNetworks for Accurate Scene Text Detection(GNNets),针对自然场景下文字检测的几何归一化网络。

该文章通过对待处理图像的特征图进行几何变换,从而将待处理图像中几何分布差异较大的文本框归一化到一定的几何分布范围内,提高了自然场景下文本测检的效果。
一、研究背景
随着深度学习的迅速发展,计算机视觉技术对实际生产具有影响越来越重要的影响。对图像中的文本进行检测和识别,有助于计算机理解视觉内容。
由于卷积神经网络(CNN)方法的通用性,自然场景文本检测受益于常规物体检测而快速发展。但由于自然场景中的文本在实际应用场景中具有较大的几何变化(例如宽高比或文字方向),所以其自身仍存在巨大的挑战。
对于尺度变化问题,现有方法一般通过使用一个检测头(detection header)对不同层级的特征进行检测,利用 NMS 融合结果后作为输出或者使用类似 FPN [1] 的网络将多尺度特征融合然后进行文本检测。
对于角度变化问题,现有方法一般通过直接回归文本框角度或使用对方向敏感的卷积来预测任意方向。
但目前的方法中要求检测头(detection header)需要学习到文字巨大的几何差异或者检测头(detectionheader)仅在所有训练样本中一个子集进行学习,这可能导致性能欠佳。
作者研究了几何分布对场景文本检测的影响,发现基于 CNN 的检测器只能捕获有限的文本几何分布,但充分利用所有训练的样本可以提高其泛化能力。
为了解决上述难题,作者提出了一种新颖的几何规范化模块(GNM)。每个自然场景图片中的文本实例可以通过 GNM 归一化到一定的几何分布范围内。这样所有训练样本均被归一化为有限的分布,因此可以有效地训练一个共享的文本检测头。
本文提出的 GNM 是通用的,可以直接将该模块插入到任何基于 CNN 的文本检测器中。为了验证提出方法的有效性,作者针对文字方向的差异性新建了一个测试集(Benchmark)并发布。
二、方法描述
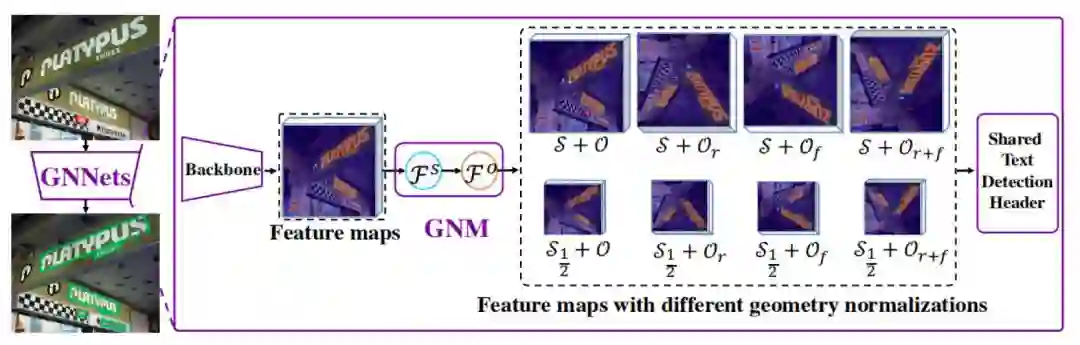
Fig.1. Overall architecture.
Fig. 1 是 GNNets 的整体网络结构图。
总体网络结构由 Backbone,GNM,SharedText Detection Header 组成。通过 Backbone 提取的特征图会被输入到具有多个分支的几何规范化模块(GNM)中,每个分支由一个尺度归一化单元(SNU)和方向归一化单元(ONU)组成。
SNU 有两个不同比例的尺归一化单位(S,S1/2)和四个方向归一化单位(O,Or,Of,Or + f)。通过 SNU 和 ONU 的不同组合,GNM 会生成不同的几何归一化特征图,这些特征图将被输入到一个共享文本检测标头中。
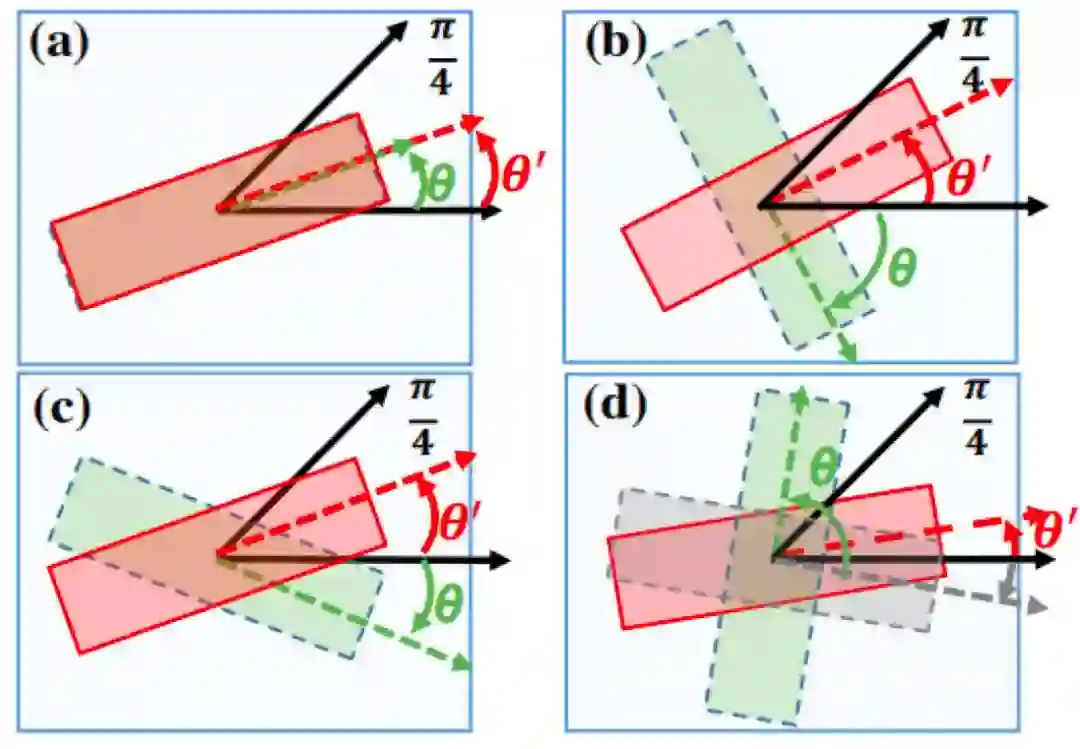
Fig.2. ONU.
Fig.2 是作者提出的 ONU 模块的示意图。通过应用 ONU 可以更改文本框方向。如图所示「绿色」框是原始框,「灰色」框是转换过程中的中间框,「红色」框是 ONU 的输出的结果框。
θ和θ' 分别是原始框和结果框的角度。(a),(b),(c)和(d)分别是 O,Or,Of,Or + f 的过程的示意图。由上图可以简单明了的表示 ONU 具有将 [0,π/4],[-π/2,-π/4],[-π/4,0] 和 [π/4,π/2] 角度的文本转换为在 [0,π/4] 角度的文本。
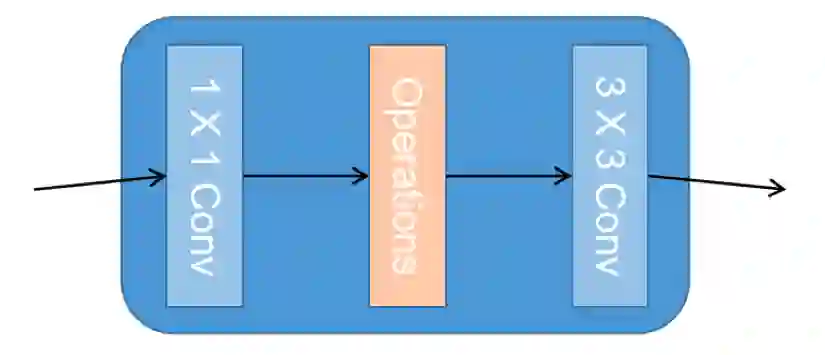
Fig.3. Architecture of GNM.
Fig. 3 展示了 GNM 在网络中的结构设置。对于 SNU 中的 S 使用 1x1 的卷积操作和 3x3 的卷积操作;S1/2 使用 1X1 的卷积,步长为 2 的下采样以及 3x3 的卷积。对于 ONU 中的 O,Or,Of,Or + f 中的 Operations 则分别采用不操作,旋转 feature maps,翻转 feature maps 和旋转后再翻转 feature maps。
由于多分支网络的影响,作者提出了一个针对 GNNets 的抽样训练策略。
在训练期间,作者随机采样一个文本实例,并通过旋转和调整大小 7 次来对其进行扩充,以使 GNM 的每个分支在每批次中都具有有效的文本实例用于训练。这样可以对 GNM 的所有分支进行统一训练。并且在训练过程中如果文本实例不在预先设定的几何区间内,则忽略分支中的该文本实例。
在测试过程中,作者将 GNM 中所有分支输出文本框相应地反向投影到原始比例和方向。不在分支预先设定的几何区间内的文本框会被丢弃。其余的文本框通过 NMS 合并。
三、实验结果
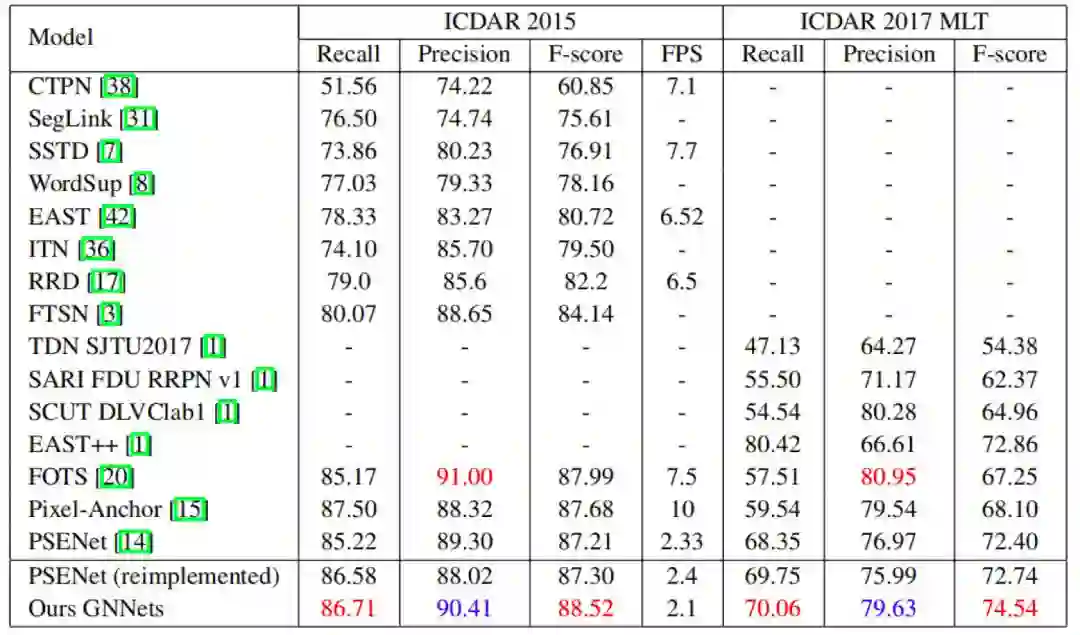
Table 1. Comparison with the state-of-the-art methods on both ICDAR 2015 and ICDAR 2017MLT.
与原始的 PSENet[2] 相比,作者提出的 GNNets 在 ICDAR 2015[3] 和 ICDAR 2017 MLT [4] 上分别实现了约 1.3%和 2.1%的性能提升。
与 ICDAR 2015 上的 EAST[5] 和 ITN [6] 相比,GNNet 的 F-score 比它们分别高出 8%和 9%。与 FTSN [7] 相比,获得了 4.5%的性能提升。GNNets 在 ICDAR 2015 上的表现优于 FOTS [8],在 ICDAR 2017 MLT 上的 F-score 更超出其 7.3%。并且 FOTS 使用了文字识别的数据。
在单尺度测试中,作者提出的 GNNets 在 ICDAR 2015 和 ICDAR2017 MLT 上均达到了 state-of-the-art 的性能。Fig. 5 可视化了 GNNets 和其他文本检测方法在 ICDAR 2015 和 ICDAR 2017 MLT 上的检测结果。

Fig.5. Qualitative results on ICDAR2015 and ICDAR 2017 MLT. The right column shows GNNets results.
四、总结及讨论
1、在本文中,作者提出了一种新颖的几何归一化模块(GNM)以生成多个几何感知特征图。并且 GNM 是通用的,可以应用到任何基于 CNN 的检测器中,以构建端到端的几何归一化网络(GNNet)。
实验表明,GNNet 在检测几何分布较大的文本实例方面相较于 baseline 表现出出色的性能。并且,GNNet 在两个文字检测主流的数据集上较最新的方法获得了显著的性能提升。
2、文中研究了几何分布对场景文本检测的影响,发现基于 CNN 的检测器只能捕获有限的文本几何分布,但充分利用所有训练的样本可以提高其泛化能力,对后续文字检测以及其他相关领域有启发性影响。
3、综上所述,文本检测是 OCR 任务的首要前提,但自然场景下文字的字体变化、悬殊的宽高比、任意角度给检测任务带来巨大的挑战,本文为我们提出了目前研究方向上忽略的点,并提供了一个新颖的解决方法,但是相较与常规物体检测,文本检测领域仍然有其特殊性以及较大的提升空间。





