给AI一张高清照片,分分钟还你细节满满的3D人体模型,GitHub标星3.6k | 在线可玩
鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
手动对人体进行3D建模并非易事。
但现在,只给AI一张高清照片,它还真就能分分钟搞定这件事。
甚至还挺高清,衣服褶皱、面部表情,细节一点不少。

这项新研究来自南加州大学和Facebook,中选CVPR 2020。
并且已经在GitHub上开源,标星3.6k,还在一天内就涨了207颗星,登上GitHub热榜。
一起来看看,这究竟是如何实现的。
多级像素对齐隐式函数
这只AI名叫PIFuHD,其基础框架是ICCV 2019上已经登场的像素对齐隐式函数PIFu。不过,PIFu以分辨率为512×512的图像作为输入,输出的3D模型分辨率不高。
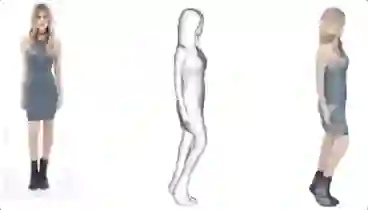
为了得到高分辨率的输出,在这项研究中,研究人员在PIFu的基础之上,额外叠加了一个像素对齐的预测模块。
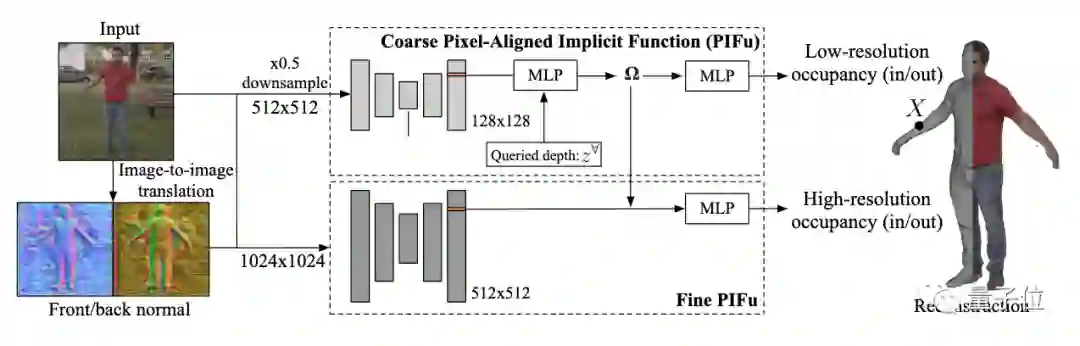
如图所示,顶部粗层次像素对齐预测器捕捉全局的3D结构。高分辨率的细节则由下面的Fine模块添加。
具体而言,fine模块将1024×1024的图像作为输入,并将其编码成高分辨率的图像特征(512×512)。
此后,高分辨率特征嵌入和第一个模块中得到的3D嵌入被结合起来,用以预测占位概率场。
为了进一步提高重建的质量和保真度,该方法还会在图像空间中预测正反两面的法线图,并将其作为额外的输入反馈给网络。
细节捕捉高手
所以,跟前辈们相比,PIFuHD究竟进步了多少?
研究人员在People Snapshot dataset数据集上将其与此前的SOTA方法进行了定性比较。
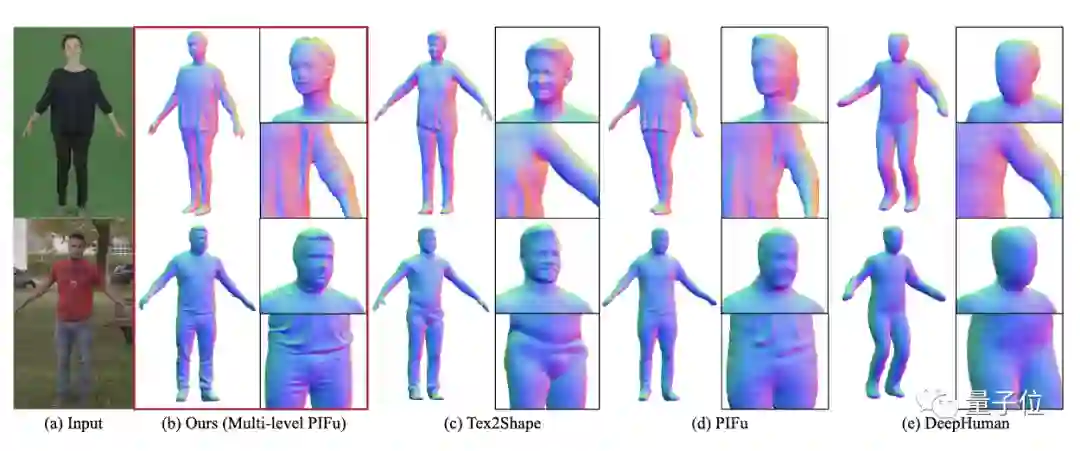
可以明显看出,由于PIFuHD充分利用了基础形状和精细形状,能够直接在像素级别上预测3D几何形状,它对输入图像的细节把握更加精准,重建出来的3D人体模型分辨率更高。
Demo可玩
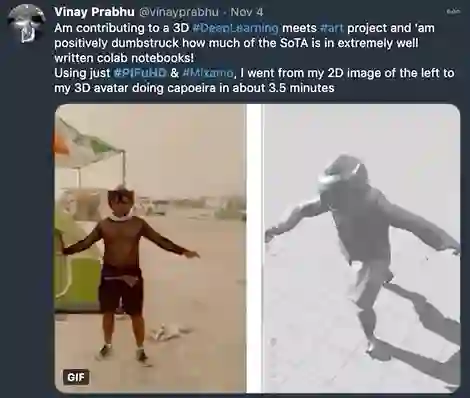
论文代码已经开源,并且,研究团队还在Colab上提供了在线试玩。
输入一张你自己的照片,几分钟之内就能收获一个数字3D的你。
真·3D建模师福音。
结合可以让3D模型动起来的Mixamo食用,网友们都玩嗨了。

赶快上手玩起来吧~
最后,附上作者简介。
论文一作斋藤俊辅(Shunsuke Saito),目前在Facebook Reality Labs担任研究科学家,致力于深度人类数字化的有效数据表征研究。
他在南加州大学工作期间,曾与计算机图形学领域知名华人教授黎颢合作。

传送门
GitHub地址:
https://github.com/facebookresearch/pifuhd
Demo地址:
https://colab.research.google.com/drive/11z58bl3meSzo6kFqkahMa35G5jmh2Wgt?usp=sharing#scrollTo=afwL_-ROCmDf
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
榜单征集!7大奖项锁定AI TOP企业


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~




