论文笔记 : Dual Neural Personalized Ranking
作者:阿瑟_f7b5
链接:www.jianshu.com/p/0d959d2e11e7
来源:简书
本文是自己在推荐系统研究中研读的论文翻译及解读,本篇笔记非标准译文,其中包含了笔者自己对问题的部分理解,仅供参考,欢迎学习交流。

背景
-
DualNPR利用用户和物品的成对排名发现用户和物品之间的真实相关性,缓解了数据稀疏问题。 不需要额外的辅助信息,仅需要用户-物品交互矩阵。 -
其基于深度矩阵分解Deep Matrix Factorization来捕获用户/物品表示的可变性。 特别是,它选择原始用户/物品向量作为输入,学习潜在用户/物品表示。 -
使用动态负采样方法提升了推荐效果。
相关知识
BPR
 ,它表示对用户u来说,i的排序要比j靠前。
,它表示对用户u来说,i的排序要比j靠前。
 符号表示用户u的偏好,
可以表示为:
符号表示用户u的偏好,
可以表示为:

在排序关系的基础上,BPR的优化目标是最大化后验概率
省略部分推导 具体的总结可见:https://www.cnblogs.com/pinard/p/9128682.html
在实际模型中,对应到相应的Loss:

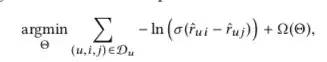
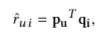
NPR
那么所谓的NPR的概念则是在BPR的基础上,加上神经网络
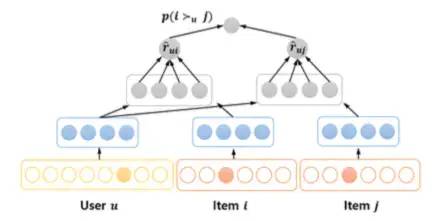
对于模型输入,通过embedding矩阵 ,这些参数用来转换得到用户和物品的向量表示,是模型训练的目标参数
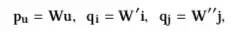
对于模型预测而言,即在原来的基础上加上非线形操作
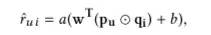
,而具体的目标函数与上面BPR所列相同,整个过程类似于Deep Matrix Factorization,虽然NPR相较于BPR,效果有很大的提升,但它并没有解决以下问题:
(1)物品侧三元组也是一个有用的训练资源,NPR并没有利用
(2)更广义的DMF可以用来表示潜在的用户/物品向量,
(3)负采样是学习BPR及其变体的关键组成部分之一,而NPR并没有进行讨论/改进 这一点在论文中有点牵强
DualNPR 模型设计
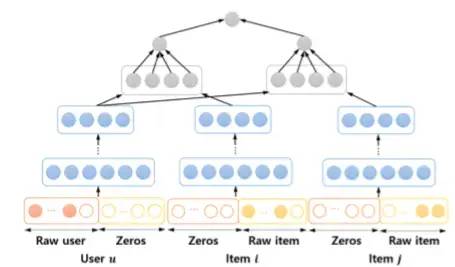
输入层设计
对于例子 用户
比起
更喜欢
,有7个用户,5个物品的话,
表示为:





相应的形式化表示为:
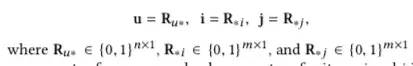
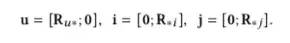
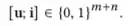
Embedding
在NPR和DMF的基础上,将经过多层隐含层的处理,模型中采用了共享权重的设计,可以加速训练,但是否有利于提高模型效果,原文并未给出解释
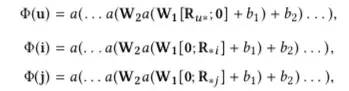
Scoring Layer
具体的评分函数则比较简单,有多种设计方式:
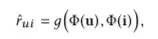

而双层设计的思想则体现在模型的输出上,包含两个输出:
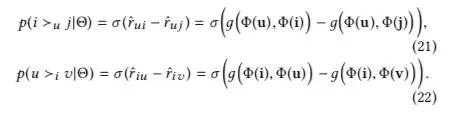
那么相应的Loss对应如下,包含用户侧误差项和物品侧误差项:
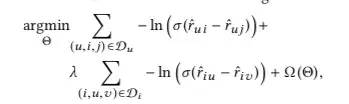
具体模型使用/预测的时候,只用计算即可
模型训练
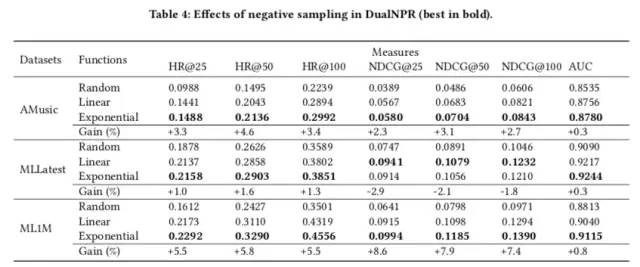
动态负采样 Dynamic Negative Sampling
模型训练中所需数据为三元组形式<u,i,j>,<i,u,v>,需要通过负采样获取负例,常见做法是从未交互过的物品/用户中等概率选取一定数量的样本作为负样本,本文提出使用动态负采样,对负例计算其排序重要程度,在此基础上计算其被采样概率,使得同一三元组中的正负样例差异增大,加快训练提升效果。
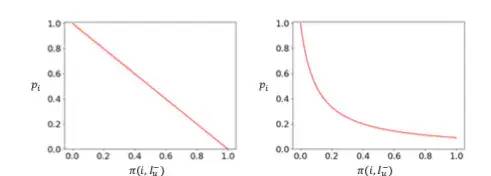
该部分细节仍在学习理解中,后续更新补充
整体流程如下:

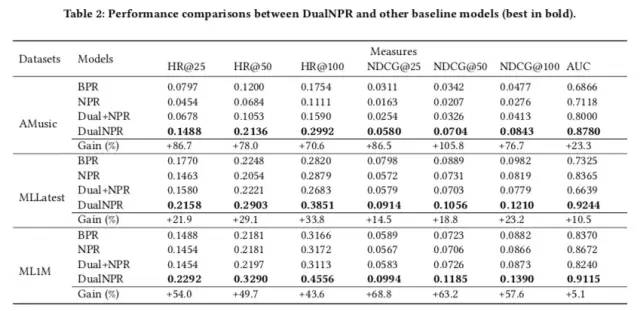
实验结果
部分实验结果如下: