IJCAI20 | 数据选择偏差下的去相关聚类

题目: 数据选择偏差下的去相关聚类
会议: IJCAI 2020
论文链接: https://arxiv.org/pdf/2006.15874.pdf
论文代码: https://github.com/googlebaba/IJCAI2020-DCKM
目前提出的大多数的聚类算法没有考虑数据中的选择偏差。但是,在许多实际应用中,不能保证数据是无偏的。选择偏差可能会带来特征之间的非期望相关,而忽略这些非期望相关性会损害聚类算法的性能。因此,如何消除由选择偏差引起的那些非期望相关性是非常重要的,但在聚类中却尚未被广泛探索。在本文中,我们提出了一种新颖的去相关正则化K-means算法(Decorrelation regularized K-Means algorithm, DCKM),用于带有数据选择偏差的聚类。具体而言,去相关正则化器旨在学习能够平衡样本分布的全局样本权重,从而消除特征之间的相关性。同时,将学习的权重与k-means相结合,这使得重新加权后的k-means聚类在固有数据分布上,而没有非期望的相关性影响。此外,我们导出更新规则以有效地推断DCKM中的参数。在现实世界数据集上的大量实验结果很好地证明了我们的DCKM算法获得了显着的性能提升,表明有必要在聚类时消除由选择偏差引起的非期望特征相关性。
1 引言
传统机器学习中的一个常见假设是,数据是从无偏分布中提取的,其中特征之间存在弱相关性。但是,在许多实际应用中,我们无法完全控制数据收集过程,并且始终遭受数据选择偏差问题的困扰,这不可避免地导致特征之间的相关性。非期望的高相关性特征是不可取的,因为它不仅会带来特征上的冗余,而且还会导致算法不令人满意的结果。一些文献研究了在机器学习模型中消除特征相关效应的问题。他们主要致力于通过设计去相关组件来消除神经网络中的特征相关效应,这为表示学习带来了很大的好处。
尽管在神经网络中去相关性取得了巨大的成功,但是在无人监督的学习场景中,数据选择偏差的影响被严重低估了。通常,聚类也会遭受数据选择偏差问题。数据选择偏差可能会导致特征之间的虚假关联。假设一个虚假的特征被错误地识别为与一个重要的特征相关联,由于存在虚假相关,这种无意义的特征的作用将在不知不觉中得到增强,从而使固有的数据分布无法得到揭示。因此,对这些数据进行聚类将不可避免地导致性能下降。如图1中所示,给定一个图像数据集,其中有很多狗在草地上,有一些猫在各种背景下,很容易得出结论,草的特征与狗的特征高度相关,而猫的特征与与背景的相关性较低。因此,在对这种有偏向的数据集执行聚类算法时,草地上的任何对象(甚至是猫)都将很有可能被聚类到狗类。这意味着由于特征之间存在虚假相关性,很容易误导聚类算法。

图1 在高相关特征上聚类的例子
2 方法
在本文中,我们提出了一种新颖的去相关正则化的K -means(DCKM)模型,用于在具有选择偏差的数据上进行聚类。具体而言,为了将一个目标特征与其余特征解相关,引入了一个解相关正则化器,以通过学习全局样本权重矩阵来平衡其余特征分布。同时,使用权重矩阵对 k -means损失进行加权。这样,加权的k -means和解相关正则化器处于统一框架中,从而导致聚类结果不受非期望的相关特征的影响。此外,我们导出了有效的迭代更新规则,以优化模型参数。
单属性去相关正则化项
首先我们介绍如何去除某个特性 和对应剩余特征 (除 特征以外的所有特征)之间的相关性。根据 特征的取值将样本分为实验组 和对照组 , 一旦我们平衡了实验组 和对照组 之间的分布,就能够减少目标特征与相应剩余特征之间的相关性。具体而言,我们引入了样本权重 来调整矩值:
其中, 表示哈德马乘积。第一项 是加权的 矩,第二项是 加权的矩,通过优化上式,可以平衡两个项,达到去除目标特征 和其剩余特征 之间相关性的目的。
对于只包含id信息用户,则对其随机初始化得到用户初始特征表示 。由于这两种表示来自不同的语义空间,利用两个类型矩阵将 与 映射到同一空间中。
全局特征去相关正则化项
请注意,上述方法是移除单个目标特征 与其剩余特征 之间的相关性。但是,我们需要移除所有特征与相应剩余特征的相关性。这意味着我们需要学习 个样本权重,这在高维场景中显然是不可行的。但是,由于 组样本权重 用于调整同一组 个样本,所以对于不同目标特征的样本权重可以被共享。因此,我们引入了全局平衡方法作为去相关正则化项。具体地,我们将所有单个特征剩余特征平衡项加在一起,其中每个平衡项是通过将每个特征设置为目标特征来制定的,对于所有剩余特征平衡项,它们使用相同的样本权重 :
从上式可以看出,全局样本权重 同时平衡了所有剩余特征项,这导致所有特征之间的相关性趋于被去除。
去相关正则化的k-means (DCKM)
在传统的 k-means模型中,是在原始特征 上学习聚类中心 和聚类分配 。但是,非期望的高度相关的特征可能会使数据分布混乱,从而导致无法得到令人满意的聚类结果。因为从去相关正则项中获得的样本权重 能够全局解相关特征,所以我们提出使用权重来重新加权k-means损失并共同优化加权的k -means损失和去相关正则化项:
将每个样本权重约束为非负数。使用范数 ,我们可以减少样本权重的方差以实现稳定性。公式 避免所有样本权重均为0。
尽管DCKM仍然对数据 执行,但是每个 的权重不再相同。该权重调整了每个数据在整个损失中的贡献,因此可以在去相关特征上学习聚类中心和聚类分配,从而可以更好地揭示真实数据的分布。
优化
约束矩阵分解目标方程不是凸的,我们将其转化为三个子问题( 子问题, 子问题, 子问题)并对其进行迭代优化。详细优化过程见论文。
3 实验
文章在两个有偏差图像数据集上构造的7个子数据上进行了实验,并且对比了相关的聚类算法,k-means以及基于kmeans的两阶段去相关方法,还有无监督特征选择方法,实验结果如下:
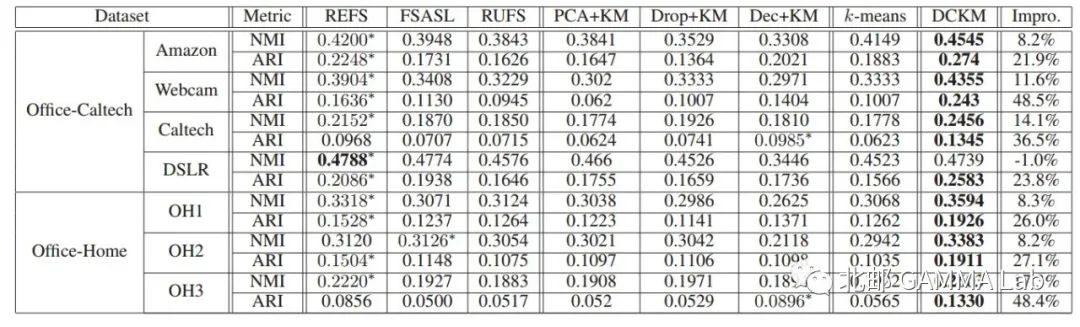
表1 在两个数据集上进行聚类结果。''*''表示基准的最佳性能。所有方法的最佳结果以粗体显示。最后一列表示与最佳基准相比,所提出的方法相比最佳对比方法所获得的改进百分比。
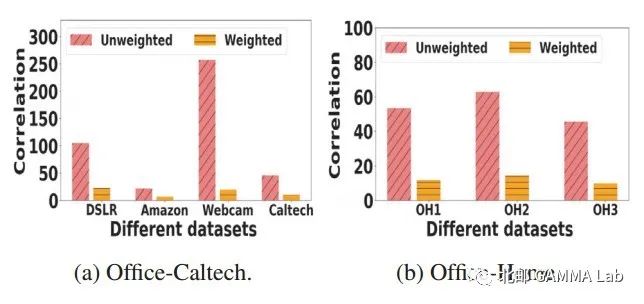
图2 在加权和不加权数据集上特征去相关分析
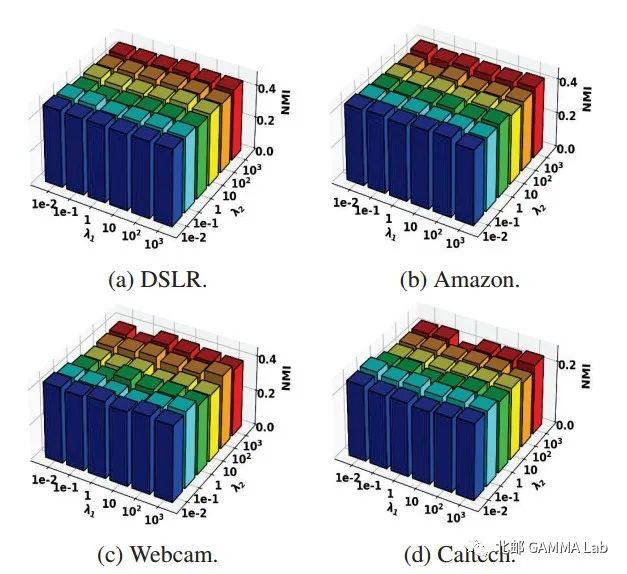
图3 在Office-caltech数据集上保持 不同 和 下DCKM的效果
图2 是加权数据和不加权数据相关性对比,可以看出我们的模型可以有效去除特征相关性。图3是参数实验,证明了参数的鲁棒性。
长按下图并点击“识别图中二维码”
即可关注北邮 GAMMA Lab 公众号