深度解读MIT TR10“全球十大突破性技术”之对抗性神经网络
近日,《麻省理工科技评论》正式揭晓 2018 年“全球十大突破性技术”(10 Breakthrough Technologies),这份全球新兴科技领域的权威榜单至今已经有 17 年的历史。

图 | 2018 年《麻省理工科技评论》全球十大突破性技术榜单包括:给所有人的人工智能(云端 AI)、对抗性神经网络、人造胚胎、基因占卜、传感城市、巴别鱼耳塞、完美的网络隐私、材料的量子飞跃、实用型 3D 金属打印机、零碳排放天然气发电共 10 大突破性技术。
回看过去几年的上榜技术,我们发现一个明显的趋势:越来越多的人工智能相关技术入选榜单,其中包括:2008 年机器学习、2009 年的 Siri、2013 年的深度学习、2014 年的神经形态芯片、2016 年的语音接口与知识分享型机器人,以及 2017 年的自动驾驶卡车与强化学习。
2018 年,我们在人工智能领域看到最具开创性的突破点,就在于人工智能将脱离需要大量资料喂养设定的框架,取得足以自行演化出更精细结果的能力。我们认为,今年最具突破性的人工智能技术是对抗性神经网络(Dueling Neural Networks)/ 对抗式生成网络(GAN)—— 通过两个 AI 系统的竞争对抗,极大化加速机器学习的过程,进而赋予机器智能过去从未企及的想像力。
十大突破性技术 中国新兴科技势力不容忽视
在 2018 年“十大突破性技术”榜单中,《麻省理工科技评论》中美编辑部经过深入调研与反复斟酌后,在针对中国发布的榜单内容中,为了避免以偏概全,也加入了来自中国本土的主要研究者,尤其是在人工智能相关领域等。不可否认,中国的科技研发能力已经成为全球最重要的势力之一,在某些领域已经可以与全球顶尖科技公司一决高下。
对抗性神经网络 位列“十大突破性技术”
入选理由:两个 AI 系统通过玩“猫捉老鼠”游戏来获得想象力
技术突破:两个 AI 系统可以通过相互对抗来创造超级真实的原创图像或声音,而在此之前,机器从未有这种能力
重大意义:这给机器带来一种类似想象力的能力,因此可能让它们变得不再那么依赖人类,但也把它们变成了一种能力惊人的数字造假工具
主要研究者:Google Brain、DeepMind、英伟达、中科院自动化所、百度、阿里巴巴、腾讯、商汤科技等
成熟期:现在

GAN在2017年实现四大突破 未来可能对计算机图形学产生冲击
商汤—香港中文大学联合实验室教授李鸿升解读:GAN 未来可能对计算机图形学产生冲击,发展三年多的 GAN,在已经发展了 60 年的人工智能领域中,虽然还是很新的技术,不过已经有各种变体或进阶版出现,而且在诸多研究人员及企业的投入下未来仍有许多的可能性。例如有机会从二维的图片进展到三维的视频等等,在更远的将来,有可能会对图形学产生冲击或挑战。
生成对抗网络(GAN,Generative Adversarial Networks)由 Ian Goodfellow 提出后,引起众多的研究者和开发人员进一步设计出诸多的 GAN 变体,使得 GAN 在去年成为讨论度最高的深度学习技术之一,商汤-香港中大联合实验室教授李鸿升接受 DeepTech 采访,深度解析 GAN 在去年的发展迎来的四大突破以及在三个层面带来的影响。
李鸿升认为去年 GAN 的发展可以说有四项重要的突破:第一,数篇很重要的论文提出了更适合训练GAN 的损失函数(或称目标函数),进而提升了 GAN 的数据生成能力。
由 Facebook 人工智能研究院(FAIR)和纽约大学科朗数学研究所(CIMS,Courant Institute of Mathematical Sciences)合作发表的《Wasserstein GAN》(简称 WGAN),以及由知名的蒙特利尔学习算法研究所(MILA,Montreal Institute for Learning Algorithms)、CIMS、加拿大高等研究院(CIFAR)合作提出的《Improved Training of Wasserstein GANs》(简称Improved WGAN)。
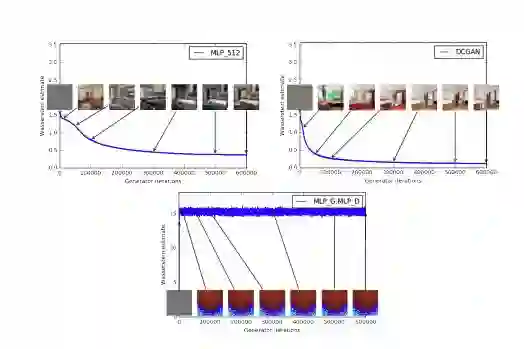
图丨《Wasserstein GAN》实验数据
这两篇论文的成就在于将最初GAN 突变的、不光滑的损失函数加以修改,提出了更合适的损失函数,并且引起了Google 和 OpenAI 的快速跟进,各自又发表了《The Cramer Distance asa Solution to Biased Wasserstein Gradients》和《Improve GAN using optimal transport》论文,都使得 GAN 训练的稳定性、鲁棒性和最终效果得到了很好的加强。
第二个突破就是许多机构跟企业设计出更适合生成复杂高维度数据的 GAN 神经网络结构。
过去 GAN 是用来生成一维信号(例如语言、语音)以及简单二维信号(例如黑白数字图像),想要生成复杂的高维度信号(例如自然图像)的难度很高,后续有研究者提出了深度卷积生成对抗网络(DCGAN,Deep Convolutional Generative Adversarial Networks),可以相对更有效的生成二维的图像信号。这是 GAN 首次在图像生成取得很大的进步,此后使用 GAN 生成图像的研究纷纷涌现,GAN的研究也因此走红。
尽管有了 DCGAN,得以让 GAN 进入了二维世界,可惜的是生成出来的图像分辨率仍然很小,多数只有 64*64 或 128*128。直到去年出现了更大的突破,首先是商汤-香港中文大学联合实验室与罗格斯大学等机构提出了 StackGAN 算法,发明了更好的神经网路结构,将生成图像的分辨率从 128*128 大幅提升到 256*256,稍后 NVIDIA 一篇以名人的脸孔为训练素材,生成出相当逼真的假名人照的论文,将分辨率一举拉高到 1024*1024,立刻令外界惊叹,GAN 一战成名。

图丨StackGAN++算法生成的教堂和猫
李鸿升指出,GAN 是属于生成模型的一种,其目标是逼近真实的数据分布。由于 GAN 做到了让数据逼近从一维发展到二维、复杂性的数据分布,所以在目前的 GAN领域里,无论是研究理论或应用,有 50% 以上都是从图像出发,或是以图像来验证新理论的可行性。现在也有人希望利用GAN 来做三维信号,例如视频。不过,现阶段即使是二维的图像效果,GAN 还不够完美,因此三维信号生成的效果还处于很初始的探索阶段。
第三个突破是对于 GAN 神经网络有新的训练方式,特别是 Conditional GAN 训练方式的突破。
最初 GAN 的概念是基于随机噪声向量(random noise)生成图像,此种称为 Unconditional GAN,NVIDIA 生成假名人照就是此类。而 Unconditional GAN 的特点是无法控制,使用者无法知道生成器究竟会产生出什么样的内容。但是,当你想要“控制”GAN 生成的内容时又该怎么办呢?因此,有研究人员提出了新的方式,也就是 Conditional GAN,生成出符合设定条件的图像。
举例来说,当我们希望生成出来的人脸都具备大眼睛、瓜子脸、高鼻子、黑头发等条件,在训练模型时,机器就会根据这些既定的条件去做,而不会生成出条件以外(如小眼睛、圆脸等)的人脸。
不过,要训练 Conditional GAN 的前提是需要成对数据(paired data)。去年加利福尼亚大学伯克利分校(UC Berkeley)提出了 CycleGAN,解决了这个难题。
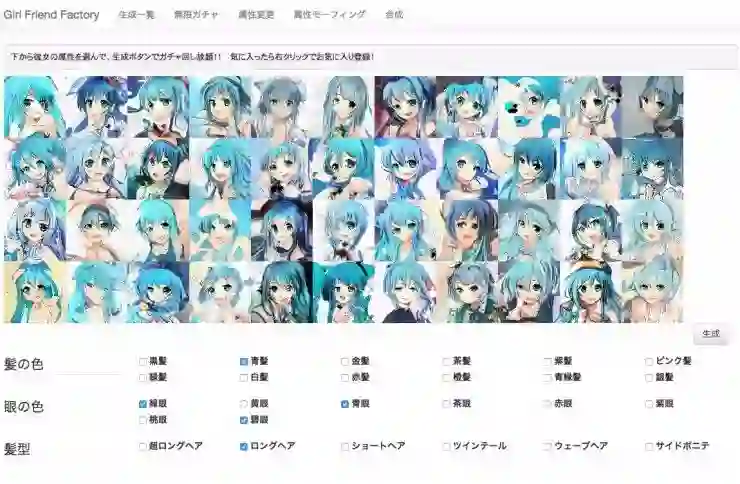
图丨Conditional GAN生成的动漫角色
该论文的内容是输入一张“马”的图片,让机器可以生成“斑马”的图片,过去 Conditional GAN 的作法是需要马和斑马的图像,而且要让机器知道两者之间细致的对应关系,例如马的头对应斑马的头在哪里,马的脚对应斑马的脚又在哪里,这就是所谓的成对数据。但是要建立这种细致的关系并不容易,一是耗费时间,二是很可能难以取得这些资料,而 CycleGAN 的作法是给予一堆马和一堆斑马的图像,先从马训练到斑马,之后让机器从斑马再训练回马。
CycleGAN 打破了以往 Conditional GAN 需要有细致成对标签的限制,不必在原始领域和目标领域之间建立训练数据一对一的映射,就可以达到图片转换的效果,因此一问世后引起了很大的反响。
第四个关键突破则是越来越多的深度学习应用引入对抗式思想,增强了原始应用的性能。

图丨李鸿升教授
一开始外界普遍认为 GAN 只是一个生成模型,不过其实对抗性的思想对于改进现有 AI 算法同样很有帮助。举例来说,传统的深度学习算法可以看作 GAN 的生成器,引入鉴别器后,可以改良原有模型的任务表现,让现有 AI 算法做的更好、生成更接近真实的结果。商汤-香港中大联合实验室教授吕建勤从事研究 GAN 进行图像超分辨率,不仅是把低分辨率的图像提高,将其变为高分辨率图像,还可以近一步自动美化图像的风格和细节。
另一位商汤-香港中大联合实验室教授林达华则是以 GAN 增强图像标题生成的真实性。图像标题生成主要是希望通过计算机看懂图像,并且用自然语言来描述图像内容,加入鉴别器可以判断这句话是人类撰写还是电脑生成的,借由这种方式让原来 AI 模型生成的标题更有“人味”、更自然。也有许多从业者将 GAN 引入机器翻译、人脸识别、信息检索等方向,在去年取得很好的突破。
问世三年多带来的三大影响
谈完了 GAN 在去年的突破,进一步来看这项技术为什么如此受到关注,“主要是带来了不少层面的影响,而且未来的潜力还很大。”李鸿升一语道出重点。
第一,从理论上来讲,生成模型是用来逼近真实数据分布,传统的生成模型如贝叶斯模型、变分自动编码器(Variational Auto Encoder)等,但在过去十多年,这些技术还是没办法逼近真实的、维度很高的数据分布,图像生成仍是一个很难的任务,一直到 GAN 的出现。

图丨由StackGAN算法生成的图像
为什么大家重视 GAN,李鸿升认为:“就在于其表现出很强的潜力,到现在还在不断提高逼近真实数据分布的能力,而且确实也有一些突破。”例如上述提及的图像生成,去年中分辨率达到256*256,年底进步到 1024*1024,尽管 1024*1024 还不够实用,但短时间之内就看到明显的进化,因此很多人认为 GAN 还有很大的发展潜力。但是,若细看 GAN 生成出来的图像还是可以发现瑕疵,也就是说尚未达到人类的能力,因此也有一派意见认为 GAN 其实没那么厉害,甚至有点被夸大其词了。两派声音各有观点。
第二个影响就是让研究人员在研究 AI 时有了更新的思路,“它教育了我们这一批研究者,是不是在一系列深度学习算法的设计中考虑引入对抗式思想、怎么引入、又该如何适当的引入,进而提高传统 AI 算法执行任务的表现。”李鸿升说。提供更多的研究思路及方式,改善 AI 的效果,这对于人类未来继续推动 AI 往前走是很重要的。
第三个就是可以基于少量数据进行半监督的学习。大家都知道要训练神经网络需要庞大的数据量,GAN 提供了一个新的思路—训练GAN 来模拟真实数据分布。在有些情况下,研究人员会遇到真实数据不够,或是难以取得数据的情况,此时可以试图训练 GAN 来模拟真实数据分布,如果模拟得够好,GAN 就可以生成更多的训练数据,这有助于解决深度学习小数据量的难题。目前已经有许多研究朝此方向努力,取得了一些成果。
例如获 CVPR 2017 最佳论文提名奖的苹果首篇论文《Learning from Simulated and Unsupervised Images through Adversarial Training》,就是使用 GAN 来生成更多接近真实的训练数据。
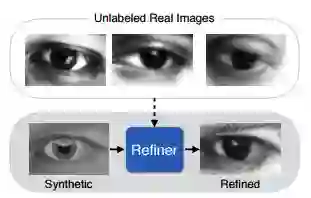
图丨Learning from Simulated and Unsupervised Images through Adversarial Training 中的演示
苹果论文研究的任务,是希望让机器通过人的眼球图片就能判断人的凝视方向。传统方式需要对人眼拍照,再手工标注,往往需要耗费很大的人力及时间成本,或者是使用计算机图形学(Computer Graphics)生成出人的眼球照片。最原始简单的方式,就是把真人的照片以及计算机图形学创造出来的照片混在一起训练。但计算机生成的图像不够真实,在训练过程中就容易出现训练数据和测试数据来自不同领域(domain)而引起的 domain gap 问题,造成效能低落,影响最终神经网络的识别性能,所以苹果通过引入 GAN 提高合成图像的真实性,缩小 domain gap对最终性能的影响。
GAN 未来可能对计算机图形学产生冲击
简单来说,目前 GAN 应用有两种方法,一是完全从无到有的生成:输入随机产生的噪声变量,输出人、动物等各种图像,这类应用难度较高;另一个则是利用 GAN 来改进已有或传统的 AI 应用,例如超分辨率、照片自动美化、机器翻译等,难度相对较低,效果也很实用。
发展三年多的 GAN,在已经发展了 60 年的人工智能领域中,虽然还是很新的技术,不过已经有各种变体或进阶版出现,而且在诸多研究人员及企业的投入下未来仍有许多的可能性。例如有机会从二维的图片进展到三维的视频等等,李鸿升也提出他的看法,“在更远的将来,有可能会对图形学产生冲击或挑战,现在虽然还没看到很明确的现象,但放胆想像的话,是有可能的。”
例如,电影产业中想要生成一个名人图像,原始做法是针对明星的人脸进行三维建模,再加上材料、物理特性的设计,再通过计算机进行渲染,这是很长的一段流程;或是也有人尝试以三维建模打造逼真的自动驾驶的训练虚拟环境。未来都可能用 GAN 就能达到。目前 GAN 生成的图像以及视频分辨率还是很低,人眼也能看出明显的瑕疵。未来几年若有新的结构、训练方式出现,就有机会做到以假乱真。如果 GAN 的研究无法保持高速的发展,就可能无法取代三维建模的流程。
在海外包括 Google、OpenAI、纽约大学等都投入大量资源进行 GAN 的研究,目前中国的学术机构也有针对 GAN 的理论展开研究,例如香港中文大学、上海交通大学、清华大学研究机构等。企业则是以 GAN 的应用为主,比如,商汤以GAN 做图像超分辨率已经产品化,客户包括了诸多手机厂商、图像处理 APP 厂商等。