PixelShuffle面面观(附不同框架的pytorch等价实现)
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
看到上面这个图,大多小伙伴心里肯定会冒出来“这不就是Sub-Pixel(或PixelShuffle或depthtospace)吗”?是的,这篇文章要介绍分享的就是PixelShuffle这一个操作。但是,各位小伙伴都清楚该操作的详细原理吗?都清楚不同框架的实现吗?不同框架之间的差异有哪些?不同框架之间如何取等价转换呢?又怎么去应用呢?是的,这篇文章就是来解决这些问题的,如果感兴趣不妨停下来跟我一起来仔细研究一下。
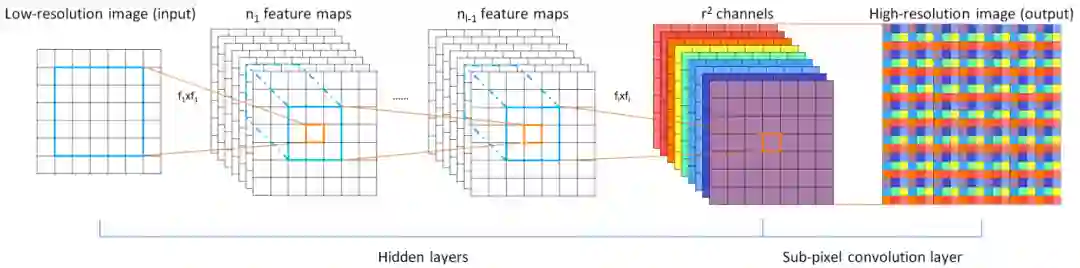
我们从两个方面进行简单的分析与研究:(1) 基于PixelShuffle的上采样;(2) 基于PixelShuffle的下采样;(3) 不同框架的实现及差异;(4) 基于Pytorch的等价转换(干货源码)。
PixelShuffleUp
首先,给出PixelShuffleUp的公式:
公式看上去非常的复杂,也不是那么容易理解,还是看图更容易理解。简单的的解释如下:
PixelShuffle上采用通过多通道像素重复达到分辨率提升的目的。以输出单通道为例,假设我们期望的分辨率提升倍率为r,那么输入的特征图的的通道数应当为 。以输出特征图的坐标为参考,那么每个位置对应的信息可以描述为:
示意图可以参考如下:
PixelShuffle最初提出是用于图像超分,它也是当前图像超分领域用的最后的一种上采样方案。比如EDSR、RCAN、WDSR等均采用PixelShuffle与卷积的组合进行特征图像的分辨率提升。相关的实现可以参考:EDSR-上采样,https://github.com/thstkdgus35/EDSR-PyTorch/blob/master/src/model/common.py#L60。使用形式主要有两种:(1) PixelShuffle+Conv:PixelShuffle进行分辨率的上采样,Conv进行最终的复原;(2) Conv+PixelShuffle+Conv:前两个达成分辨率上采样的目的,最后的Conv达成图像复原的目的。在这种两种应用形式中以第二种最多。具体可以参考前面提到的EDSR实现链接。
PixelShuffleDown
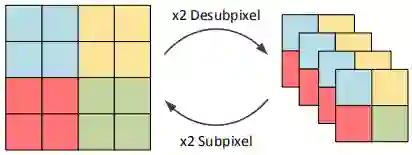
上图给出了PixelSHuffleDown与PixelSHuffleUp的可视化关系图,很明显两者是互逆操作。也就是说,两者满足这样的约束: 。以PixelShuffleUp中的示意图为例,那么其逆过程(即PixelShuffleDown)输出结果应当是如下形式。
PixelShuffleDown早期是2018年被用于加速图像增强、图像超分(见参考2,3),后来也有被用于图像分类,作为分类网络的Stem模块(见参考4,5)。
在图像复原里面,直接在输入图像分辨率层面计算的话,会导致计算量过大,而采用stride=2的卷积、Maxpool等方式进行下采样则会造成信息损失与性能下降,故而PixelShuffleDown是一种不错的选择。
类似的,在图像分类领域,之前的分类网络大多采用stride=2的卷积、MaxPool进行特征下采样,这无疑会造成信息损失,而PixelShuffleDown不仅不会造成信息,同时具有更低的计算量、参数量。所以各位小伙伴可以尝试一下PixelShuffleDown。
Difference
前面介绍了PixelShuffleDown与PixelShuffleUp两者之间的关联、示意图。那么如何来实现上述操作呢?这里仅以Pytorch、Tensorflow、Caffe三个应用面最广的框架进行说明。
对于PixelShuffleUp而言,现有各大深度学习框架基本都有支持。比如喜爱Pytorch的小伙伴可以使用代码F.pixel_shuffle(inputs, upscale_factor)达到该目的;喜欢Tensorflow的小伙伴可以使用代码tf.depth_to_space(inputs, upscale_factor)达到该目的;喜欢C安安分分的小伙伴就需要多费点事咯,可以参考RealSR,https://github.com/csjcai/RealSR/tree/master/Layer/Shuffle中的实现。
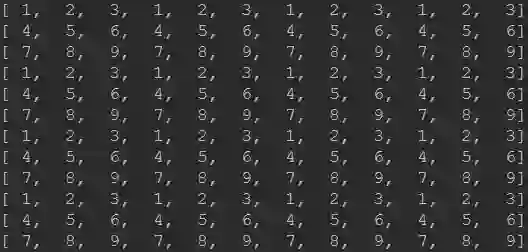
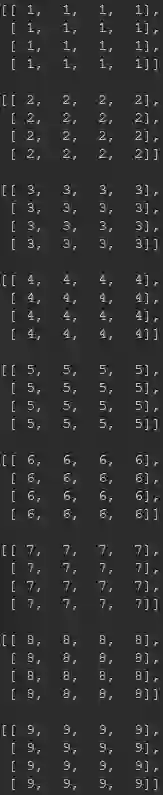
你以为关于PixelShuffle的介绍到此就结束了吗?No!No!No!前面都只是热身,下面才是真正的重点所在。还是以前面的示意图为例进行说明,假设输入特征图的尺寸为 ,每个通道的数值为通道索引+1,即1-27。采用上Pytorch、Tensorflow以及Caffe代码进行特征图上采样后大家会发现结果是不相同的。
Pytorch的实现结果如下所示:
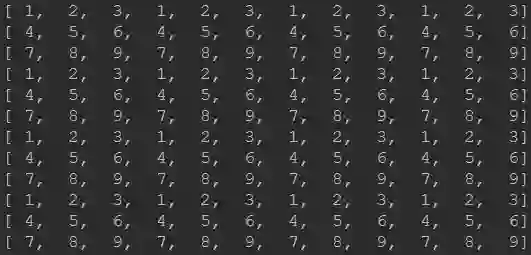
而Tensorflow的实现结果是:
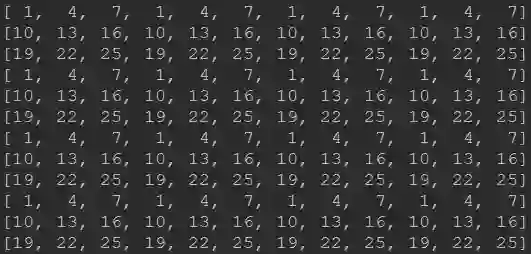
Caffe的实现结果是:
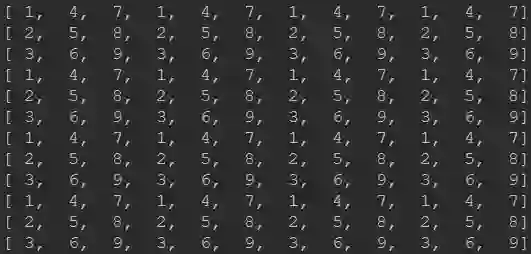
有没有感觉Pytorch与Tensorflow的差别非常大!笔者也是在去年7-8月份进行不同版本的超分模型转换时发现的,在进行RealSR中的Lp-KPN由Caffe模型转Pytorch过程中发现两者的PixelShuffle存在一些区别,相关转换后的Pytorch代码可以参考之前的文章图像超分:RealSR,https://zhuanlan.zhihu.com/p/80552632,上述代码可以完美的复现作者Caffe版的效果(因为模型参数就是从作者的模型转过来的);笔者在之前转换小米的FALSR,https://github.com/xiaomi-automl/FALSR)预训练模型时发现了Tensorflow与Pytorch在实现上的区别,当时也写过关于如何将其他框架预训练模型导入Pytorch框架的指南纯干货:如何将其他框架训练模型导入到pytorch中?https://zhuanlan.zhihu.com/p/75601879。
那么是什么原因导致三者在实现结果上的差异呢?经过分析发现,这与三者的底层逻辑存在一定关联。
Pytorch与Tensorflow的区别主要源自两者数据排布方式导致,Pytorch中的数据排布方式为NCHW,而Tensorflow中的数据排布方式为NHWC。这就导致了底层实现时的差异:(1) Pytorch先进行空间层面的数据处理,所以Pytorch表现出近邻通道局部块排布;(2) Tensorflow先进行通道层面的数据处理,所以Tensorflow表现出跨通道局部块排布。
Pytorch与Caffe的区别主要是源自底层代码实现过程的行主序还是列主序(注:两者均是NCHW的数据排布方式)。反应的公式上来讲,Pytorch是按照前述公式(行主序)进行处理,而Caffe中的实现则有一点点的改动(变成了列主序,可能与作者的团队喜欢用MATLAB有关吧,猜测的哈),其公式如下:
好了,关于PixelShuffle的关键性介绍基本上到此就要结束了。前面也分析介绍了PixelShuffle的不同框架实现、不同框架之间的区别所在。最后的最后,附上Pytorch、Tensorflow、Caffe等PixelShuffle的Pytorch等价实现。
Reference Code
# Same as RealSR# https://github.com/csjcai/RealSRdef shuffle_down(inputs, scale):N, C, iH, iW = inputs.size()oH = iH // scaleoW = iW // scaleoutput = inputs.view(N, C, oH, scale, oW, scale)output = output.permute(0, 1, 5, 3, 2, 4).contiguous()return output.view(N, -1, oH, oW)# Same as RealSR# https://github.com/csjcai/RealSRdef shuffle_up(inputs, scale):N, C, iH, iW = inputs.size()oH = iH * scaleoW = iW * scaleoC = C // (scale ** 2)output = inputs.view(N, oC, scale, scale, iH, iW)output = output.permute(0, 1, 4, 3, 5, 2).contiguous()output = output.view(N, oC, oH, oW)return output# Same as Pytorchdef shuffle_up_torch(inputs, scale):N, C, iH, iW = inputs.size()oH = iH * scaleoW = iW * scaleoC = C // (scale ** 2)output = inputs.view(N, oC, scale, scale, iH, iW)output = output.permute(0, 1, 5, 2, 4, 3).contiguous()output = output.view(N, oC, oH, oW)return output# InvPixelShuffle of Pytorchdef shuffle_down_torch(inputs, scale):N, C, iH, iW = inputs.size()oH = iH // scaleoW = iW // scaleoutput = inputs.view(N, C, oH, scale, oW, scale)output = output.permute(0, 1, 3, 5, 4, 2).contiguous()return output.view(N, -1, oH, oW)# Same as depthtospace of Tensorflowdef shuffle_up_tf(inputs, scale):N, C, H, W = inputs.size()inputs = inputs.view(N, scale ** 2, -1, H, W).transpose(2, 1).contiguous()inputs = inputs.view(N, C, H, W)return F.pixel_shuffle(inputs, scale)# Inv DepthtoSpace (should be same as spacetodepth of Tensorflow, not test)def shuffle_down_tf(inputs, scale):output = shuffle_down_torch(inputs, scale)N, C, H, W = output.size()output = output.view(N, -1, scale * scale, H, W)output = output.transpose(2, 1).contiguous().view(N, -1, H, W)return output
参考文献
CVPR2016. Real Time Single Image and Video Super Resolution using an Efficient Sub-Pixel Convolutional Neural Network.
ECCV2018. Fast and Efficient Image Quality Enhancement via Desubpixel Convolutional Neural Network.
ICCV2019 Toward Real-World Single Image Super-Resolution A New Benchmark and A New Model.
Arxiv2019. Non-discriminative data or weak model? On the relative importance of data and model resolution.
Arxiv2020. TResNet: High Performance GPU-Dedicated Architecture.
推荐阅读:

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~



