首发 | 三角兽被 EMNLP 录取论文精华导读:基于对抗学习的生成式对话模型浅说
AI 科技评论按:近日,三角兽科技 AI Lab 的一篇论文,被世界顶级自然语言处理会议 EMNLP 高分录取,论文题目为:Neural Response Generation via GAN with an Approximate Embedding Layer,由三角兽研究团队与哈工大 ITNLP 实验室合作完成。论文中提出了一种新的对话文本对抗生成学习框架,目的是解决文本生成过程中的采样操作带来的误差无法反向传导的实际问题,从而实现基于对抗学习的聊天回复生成模型。

以下为三角兽研究团队所写的论文精华导读,AI 科技评论授权首发:
引言
在最近几年里,深度学习 (Deep Learning, DL)在自然语言处理领域不断攻城略地,使得过去被认为很难取得突破的研究方向的难度有所降低,其中最为人们所津津乐道案例的当属 Sequence-to-Sequence (S2S) 在对统计机器翻译(Statistical Machine Translation, SMT)领域的颠覆性突破,进而产生了全新的基于神经网络的机器翻译(Neural Machine Translation, NMT)范式[1, 2]。这个新范式的影响甚至已经波及到了其他相关领域,其中就包括本文即将讨论的生成式自动聊天系统(Generation based Chatting System)[3, 4, 5]。
通常认为自动聊天系统(Automatic Chatting Systems)可以通过两种技术路线实现:一种是将信息检索系统构建于大规模对话数据集之上,通过建立有效的问句匹配和问答相关度量化模型实现对用户 query的合理回复[6],本文不做赘述;另一种技术路线则试图通过构建端到端(End-to-End)的深度学习模型,从海量对话数据中自动学习 query 和 response 之间的语义关联,从而达到对于任何用户 query 都能够自动生成回复的目的。如果说基于信息检索的技术路线偏重工程实现的话,那么基于生成的技术路线则显得更加学术。
生成式聊天模型的提出与 NMT 有着极为紧密的关联,这种关联可以追溯到深度学习尚未如此风行的年代:在早期的问答系统(Question Answering Systems)的相关研究中,人们就已经把SMT 的相关模型和方法应用在答案筛选排序模块里,并取得了不错的效果[7]。这背后的原因是,为一个问题寻找答案的过程可以看作是一种特殊的翻译过程,在这个特殊的翻译过程中,问题和答案分别位于翻译模型的两端,如此一来,一个 question-answer pair 实际上等价于 SMT 需要处理的一条平行语料,而 SMT 的训练过程实际上也就等价于构建问题和答案当中词语的语义关联过程。在 NMT 取得巨大成功之后,这种新的范式很自然的被应用在聊天回复的自动生成上,于是本文所要讨论的第一个直观思维产生了:聊天可以看作是一种特殊的不以获取信息为目的的问答,同时 SMT 可以用来寻找答案,且 NMT 是 SMT 的一种高级形态,那么 NMT 模型可望用来实现聊天回复的自动生成。如今,我们把这种新的自动聊天模型架构命名为 Neural Response Generation(NRG)。
NRG 面临的挑战
不可否认,采用 NRG 模型生成的一部分聊天回复在主题上确实能够做到与相应的 query 吻合,甚至会有个别语义相关度较高且可读性很好的回复可以被生成出来,饶是如此,恐怕不会有人认为 NRG 复制了 NMT 模型在机器翻译领域的成功,其主要原因就是,这种端到端模型生成的绝大多数答案严重趋同,且不具有实际价值,即无法让人机对话进一步进行下去,例如,对于任何的用户 query,生成的结果都有可能是“我也觉得”或“我也是这么认为的”。无论模型在中文数据还是在英文数据上进行训练,这种现象都非常明显,由于模型生成的绝大多数结果对于任何 query 都勉强可以作为回复,于是我们把这种生成结果形象的命名为 safe response[8]。
显而易见,safe response 的大量存在将使自动聊天系统显得索然无味,使用户失去与系统互动的热情,因此目前的实用聊天系统仍然是以信息检索模型为主要架构。简而言之,NRG 模型如果想要在实际产品中发挥作用,避免 safe response 的生成是必须要解决的问题,无可回避。
Safe response 问题的产生可能是多种因素共同作用的结果,本文仅从最直观的方向切入这个问题。这里不妨思考这样一个问题:在同样的数据组织形式,同样的模型结构,合理的假设的情况下,为什么 NMT模型没有遇到如此明显的 safe translating result 的问题?这时候回顾 NMT 模型的工作流程是很有必要的:NMT 模型由两个部分组成,一部分负责对 source sentence 进行语义表示,将其压缩成指定维度的语义向量,因此可以称其为 encoder;另一部分负责接收 encoder 提供的语义向量,并在语义向量的“指导”下,逐个挑选词语组成 target sentence,这个部分通常被称作 decoder。一言以蔽之,encoder 负责提供输入信号的语义表示,decoder则实际上实现了一个以该语义表示为初始条件的语言模型。
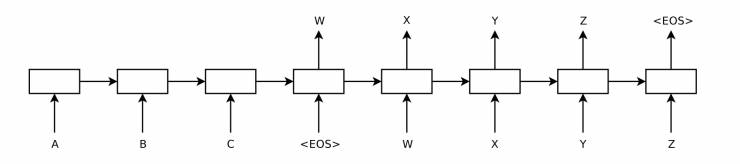
图1 经典的 Sequence-to-Sequence 模型[1]
如此一来,safe response 的症结之一就呼之欲出了:如果比较机器翻译和聊天的训练数据就不难发现,聊天数据中词语在句子不同位置的概率分布具有非常明显的长尾特性,这一特性通常在句子开头几个词语上体现得尤为明显,例如,相当大比例的聊天回复是以“我”“也”作为开头的句子,相对地,对于主要以正规文本为数据源形成的 SMT 平行语料来说,这种情况出现的可能会依数量级地减少。在这样的情况下,词语概率分布上的模式会优先被 decoder 的语言模型学到,并在生成过程中严重抑制 query 与 response 之间词语关联模式的作用,直观来看,即便有了 query 的语义向量作为条件,decoder 仍然会挑选概率最大的“我”作为 response 的第一个词语,又由于语言模型的特性,接下来的词语将极有可能是“也”……以此类推,一个 safe response 从此产生。
一个直观的解决方案
NRG 模型产生 safe response 的问题可以说是意料之外情理之中的事情,于是人们坚定地对这个难题发起了挑战。常见的解决方案包括:通过引入 attention mechanism 强化 query 中重点的语义信息[4],削弱 decoder 中语言模型的影响[8],从广义上来说,引入 user modeling 或者外部知识等信息也能够增强生成回复的多样性[9, 10]。
而当我们跳出对于模型或者数据的局部感知,从更加全局的角度考虑 safe response 的问题的时候,一个非常直观的方案扑面而来:产生 safe response 的 S2S 模型可以认为是陷入了一个局部的最优解,而我们需要的是给模型施加一个干扰,使其跳出局部解,进入更加优化的状态,那么最简单的正向干扰是,告知模型它生成的 safe response 是很差的结果,尽管生成这样的结果的 loss 是较小的。
一个直观的思想,开启了生成式对抗网络(Generative Adversarial Networks, GAN)[11]在生成式聊天问题中的曲折探索。
知易行难
将 GAN 引入聊天回复生成的思路显得如此水到渠成:使用 encoder-decoder 架构搭建一个回复生成器G,负责生成指定 query 的一个 response,同时搭建一个判别器 D 负责判断生成的结果与真正的 response 尚存多大的差距,并根据判别器的输出调整生成器 G,使其跳出产生 safe response 的局部最优局面。
然而当我们试图通过对抗学习实现文本生成的时候,一个在图像生成的 GAN 模型中从未遇到的问题出现在面前,那就是如何实现判别器D训练误差向生成器G的反向传播(Backpropagation)。对于基于 GAN的图像生成模型来说,这种误差的反向传播是如此的自然,因为 G 生成图像的整个过程都是连续可导的,因此 D 的训练误差可以从 D 的输出层直接传导到 G 的输入层。而对于文本的生成来说,一个文本样本的生成必然伴随 G 在输出层对词语的采样过程,无论这种采样所遵循的原则是选取最大概率的 greedy思想还是 beam searching,它实际上都引入了离散的操作,这种不可导的过程就像道路上突然出现的断崖,阻挡了反向传播的脚步,使对于 G 的对抗训练无法进行下去。
为了解决文本生成过程中的采样操作带来的误差无法传导的实际问题,从而实现基于对抗学习的聊天回复生成模型,三角兽研究团队在论文 Neural Response Generation via GAN with an Approximate Embedding Layer 中提出了一种新的对话文本对抗生成学习框架,目前本论文已经被 EMNLP 2017 录用。
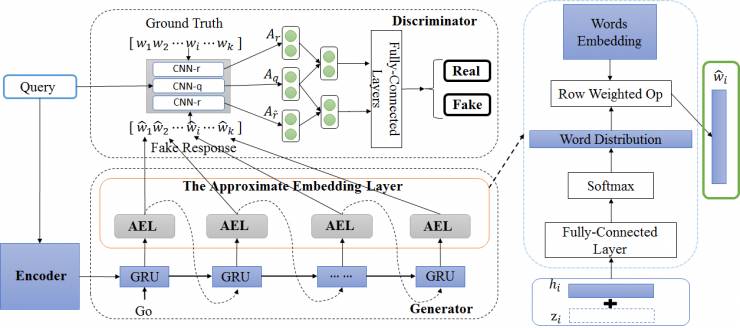
图2 基于GAN-AEL的对抗学习框架
图2展示了论文提出的 GAN with an Approximate Embedding Layer (GAN-AEL)的基本框架。我们使用 GRU 构建回复生成模型 G 的主体,用 CNN 构建判别器 D 用以判断 query 与(真实存在的或模型生成的)response 之间的语义是否相关。在给定一个 query 的情况下,模型 G 通过 encoding-decoding 过程生成一个 fake response,这个 fake response 将与 query 构成一个负样本,同时,query 在与训练数据里的真正的 response 构成一个正样本,判别器 D 的训练目标即是尽可能的区分上述正负样本。
如前文所述,引入对抗学习改善文本生成的关键问题是如何解决文本生成过程中由采样带来的不可导问题,从而实现判别器误差向生成器的正确传播。本文直面此问题,为生成器 G 构建了一个 Approximate Embedding Layer (AEL 如图中红色矩形框中所示,其细节在图右侧部分给出),这一层的作用是近似的表达每次采样过程,在每一个 generation step 中不再试图得到具体的词,而是基于词语的概率分布算出一个采样向量。这个操作的具体过程是,在每一个 generation step 里,GRU 输出的隐状态 h_i 在加入一个随机扰动 z_i 之后,经过全连接层和 softmax 之后得到整个词表中每个词语的概率分布,我们将这个概率分布作为权重对词表中所有词语的 embedding 进行加权求和,从而得到一个当前采样的词语的近似向量表示(如图2中右侧绿框所示),并令其作为下一个 generation step 的输入。同时,此近似向量同样可以用来拼接组成 fake response 的表示用于 D 的训练。不难看出,这种对于采样结果的近似表示操作是连续可导的,并且引入这种近似表示并不改变模型 G 的训练目标。
我们的一小步
作为生成器和判别器的耦合媒介,AEL 的建立保证了对抗学习框架在面向聊天的 response generation 问题上应用的合理性。为了验证这种合理性,我们在目前常见的中英文对话数据上对我们的模型进行了验证,其结果如下表所示:
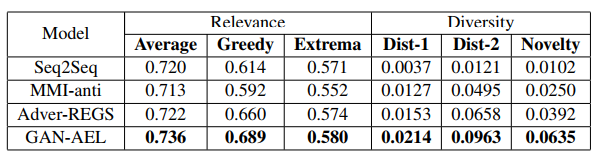
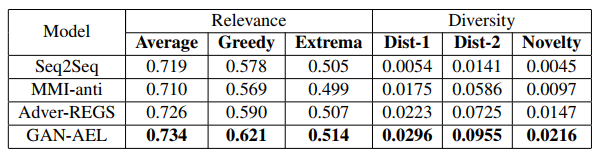
表格中的 Seq2Seq、MMI-anti 和 Adver-REGS 分别代表经典 encoder-decoder、引入 anti-language model 机制的 S2S 和一种基于强化学习的 GAN 模型架构。我们试图从生成结果的语义相关性(Relevance)和多样性(Diversity)两个方面对比几个模型,可以看到本文提出的 GAN-AEL 在保证语义相关性的情况下,明显提高了生成 response 的多样性。
为了直观的展现模型在多样性方面的提升,我们给出了一些实际生成结果的样例,如下表所示。
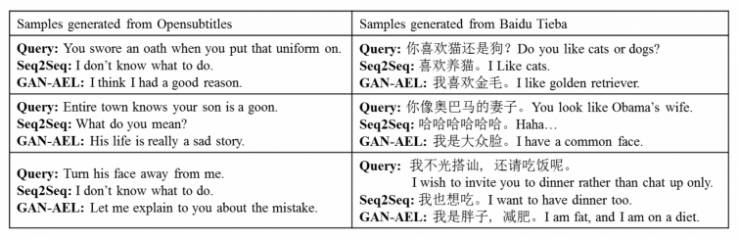
我们的模型给出了有关模型的理论细节、评测指标以及baseline方法的具体描述,有兴趣的读者可以持续关注我们放出的论文。
结语
两个直观的 idea,开启了基于深度学习模型的端到端自动聊天系统的研究,引出了对抗学习在聊天回复生成中的曲折探索。诚然,当前最引人关注的模型配上最热的研究方向,对于任何的研究者来说都具有很强的吸引力,但是,要做到直面关键问题,潜心寻找解决问题的途径,需要的则是务实的钻研,任何浮躁的心态都有可能让研究工作最终沦为无聊的灌水。
让机器自动生成任何 query 的回复是一个极其困难的问题,因为我们试图挑战的是人类的语言能力。挑战难题的过程就像登山,任何一个新的方法的提出未必代表我们铺建了通往山顶的路,而是给人们提供了一根登山杖,让人们走得更远。
参考文献
[1] Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, NIPS’14, pages 3104–3112, Cambridge, MA, USA. MIT Press.
[2] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using rnn encoder–decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1724– 1734, Doha, Qatar. Association for Computational Linguistics
[3] Baotian Hu, Zhengdong Lu, Hang Li, and Qingcai Chen. 2014. Convolutional neural network architectures for matching natural language sentences. In Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, pages 2042–2050
[4] Lifeng Shang, Zhengdong Lu, and Hang Li. 2015. Neural responding machine for short-text conversation. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, pages 1577–1586, Beijing, China. Association for Computational Linguistics.
[5] Alessandro Sordoni, Michel Galley, Michael Auli, Chris Brockett, Yangfeng Ji, Margaret Mitchell, Jian-Yun Nie, Jianfeng Gao, and Bill Dolan. 2015. A neural network approach to context-sensitive generation of conversational responses. In NAACL HLT 2015, pages 196–205
[6] Bowen Wu, Baoxun Wang, and Hui Xue. 2016. Ranking responses oriented to conversational relevance in chat-bots. In COLING 2016, 26th International Conference on Computational Linguistics, Proceedings of the Conference: Technical Papers, December 11-16, 2016, Osaka, Japan, pages 652–662.
[7] Delphine Bernhard and Iryna Gurevych, Combining Lexical Semantic Resources with Question & Answer Archives for Translation-Based Answer Finding
[8] Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016a. A diversity-promoting objective function for neural conversation models. In Proceedings of NAACL-HLT, pages 110–119.
[9] Jiwei Li, Michel Galley, Chris Brockett, Georgios P. Spithourakis, Jianfeng Gao, and William B. Dolan. 2016b. A persona-based neural conversation model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, August 7-12, 2016, Berlin, Germany.
[10] Xing Chen, Wu Wei, Wu Yu, Liu Jie, Huang Yalou, Zhou Ming, and Ma Wei-Ying. 2017. Topic aware neural response generation. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA., pages 3351–3357.
[11] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680.



