【AAAI2021】Lipschitz终生强化学习

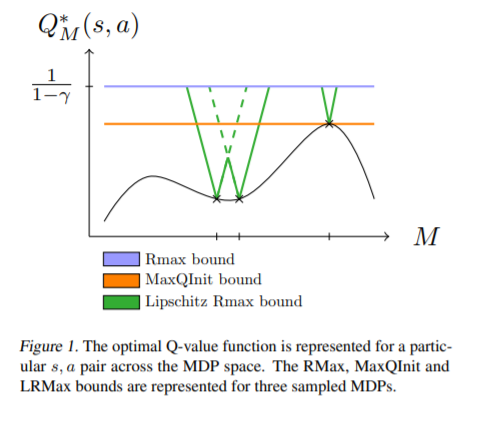
我们研究了智能体在面临一系列强化学习任务时的知识转移问题。在马尔可夫决策过程之间引入了一种新的度量方法,证明了封闭式多目标决策具有封闭式最优值函数。形式上,最优值函数是关于任务空间的Lipschitz连续函数。根据这些理论结果,我们提出了一种终身RL的值转移方法,并利用该方法建立了一种收敛速度较好的PAC-MDP算法。我们在终身RL实验中说明了该方法的好处。
https://www.zhuanzhi.ai/paper/031fb6db56a53d5fc61281f327beddd5
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LLRL” 就可以获取《【AAAI2021】Lipschitz终生强化学习》专知下载链接



登录查看更多
相关内容

Arxiv
5+阅读 · 2020年4月2日
Arxiv
3+阅读 · 2018年11月8日




相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2020年4月2日
Arxiv
3+阅读 · 2018年11月8日