选择性注意力在强化学习中的应用

文 /研究软件工程师 Tang Yujin 和研究员 David Ha,Google Research
非注意盲视 (Inattentional Blindness) 是一种心理现象:在人们聚焦于某项任务时,他们会忽视与之无关的细节,这就是 选择性注意力 (Selective Attention) 的结果。
这种选择性注意力使人能够专注于外界的重要信息,而不会分心于无关紧要的细节。人们相信,这种选择性注意力机制使人能够将广泛的感官信息浓缩为一种足够简洁的形式,用于未来的决策。
尽管这看似是一种局限性,但对于希望模仿生物有机体的成功和效率的机器学习系统而言,在自然界中观察到的这种“瓶颈”往往能为设计带来启发。例如,虽然深度强化学习 (RL) 文献中提出的大多数方法均允许智能体 (Agent) 访问整个视觉输入,甚至包括用于预测视觉输入未来序列的模块,但是否能通过注意力约束 减少 智能体对视觉输入的访问,提升智能体的性能?
未来序列
https://ai.googleblog.com/2019/03/simulated-policy-learning-in-video.html
在我们最近发布的 GECCO 2020 论文“可自解释智能体的神经进化”(AttentionAgent) 中,我们研究了含有自注意力 Bottleneck 的智能体的特性。研究结果表明,与传统方法相比,这些模型不仅能够用传统模型千分之一的参数量,基于像素级别的输入,来解决具有挑战性的视觉任务,而且得益于其可以“忽略混淆性细节”的能力,在面对未见过的任务修改时,模型的泛化能力也更加出色。
可自解释智能体的神经进化
https://attentionagent.github.io/
此外,通过观察智能体的注意力集中在哪些方面,也为决策的产生过程提供了视觉上的可解释性。下图说明了智能体学习处理注意力瓶颈的过程:
AttentionAgent 学会了关注视觉输入中的任务关键区域:在汽车驾驶任务中(CarRacing,上排),智能体主要关注道路边界,但在改变前进方向之前会将注意力转移到转弯上。在火球躲避游戏(DoomTakeCover,下排)中,智能体专注于火球和敌方怪物。左侧:智能体的视觉输入。中间:智能体的注意力叠加在视觉输入上,白色区块表示智能体的注意力所集中的位置。右侧:智能体做出决策所依据的视觉线索
-
CarRacing
https://gym.openai.com/envs/CarRacing-v0/ DoomTakeCover
https://github.com/mwydmuch/ViZDoom/tree/master/scenarios#take-cover
具有人工注意力的智能体
尽管有一些工作探讨了稀疏性等约束在实际塑造强化学习智能体的能力中所发挥的作用,但 AttentionAgent 另辟蹊径,从与非注意盲视有关的概念中汲取灵感,即当大脑参与需要付出努力的任务时,它的大部分注意力仅集中在与任务相关的元素上,暂时对其他信号视而不见。
为了实现这一点,我们将输入图像分割成几个区块,然后依靠修改后的自注意力架构来模拟区块之间的投票,从而选出一个被认为重要的子集。在每个时间步中选择相关的区块,并且一旦确定,AttentionAgent 便仅基于这些区块进行决策,而忽略其余区块。
自注意力
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
除了从视觉输入中提取关键因素之外,能够在这些因素随时间变化时将它们进行关联也同样至关重要。例如,棒球比赛中的击球手必须利用视觉信号来连续跟踪棒球的位置,以预测能够击打到球的位置。AttentionAgent 则会利用长短期记忆 (LSTM) 模型,从重要的区块中截取信息,并在每个时间步生成一个操作。LSTM 会跟踪输入序列的变化,因此可以利用这些信息来跟踪关键因素随时间的演变情况。
通常采用反向传播来优化神经网络。然而,由于 AttentionAgent 包含用于生成重要区块的不可微的运算(例如排序和切片),因此将此类技术应用于训练并非易事。因此,我们转而采用无导数优化算法来克服这个困难。
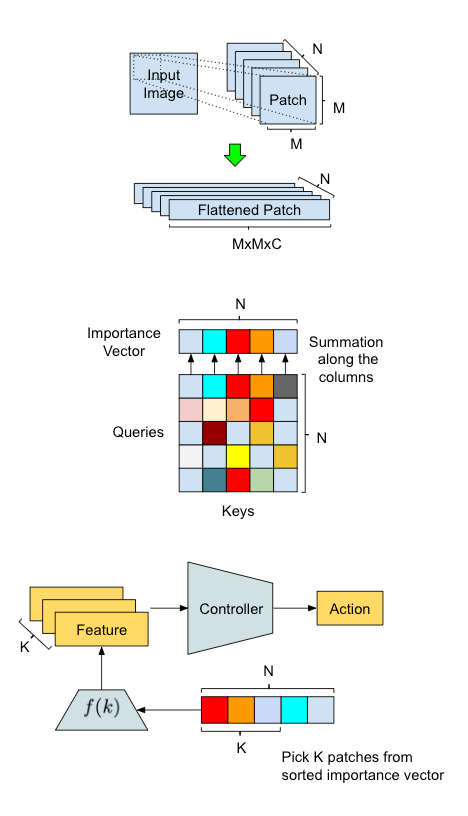
我们的方法概述以及 AttentionAgent 中的数据处理流程说明。上排:输入转换 - 滑动窗口将输入图像分割成较小的区块,然后将其“展平”以备将来处理。中间:区块选举 - 修改后的自注意力模块在区块之间进行投票,以生成区块重要性向量。下排:动作生成 - AttentionAgent 挑选最重要的区块,提取相应的特征,并根据它们做出决策。
泛化到未见过的环境修改
我们证明 AttentionAgent 学会了关注输入图像中的不同区域。重要区块的可视化使您可以窥探智能体如何制定决策,从而说明大多数选择都是有意义的,并且符合人类的直觉,是分析和调试开发中智能体的强大工具。此外,由于智能体学会了忽略对核心任务不重要的信息,因此可以泛化到环境进行了细微修改的任务。
在这里,我们展示了,如果让智能体的决策控制器仅访问重要区块,而忽略场景的其余部分,则可以提高泛化能力,原因就在于智能体受到限制,无法“看到可能令其混淆的内容”。我们的智能体仅在 VizDoom TakeCover 环境下接受过生存训练,但在其他未见过的墙壁较高、地板纹理不同的环境下,或是在面对令人分心的标志时也能生存下来。

DoomTakeCover 泛化:AttentionAgent 在未经修改的环境中训练(左侧)。它能够适应环境的变化,例如更高的墙(中间,左侧)、不同的地板纹理(中间,右侧)或浮动文本(右侧)
如果一个人学会在晴天驾驶,他/她也可以将这些技能(在某种程度上)转移到其他驾驶场景,如夜间驾驶、雨天驾驶、驾驶不同的汽车或在挡风玻璃上有鸟粪的情况下驾驶。AttentionAgent 不仅能够解决 CarRacing-v0,它还可以在未见过的条件(例如景色更亮或更暗,或者其视觉被侧栏或背景斑点等伪像修改)下实现类似的性能,而需要的参数仅相当于不能泛化的传统方法的千分之一。

CarRacing 泛化:无修改(左侧);颜色扰动(中间,左侧);左侧和右侧的竖线(中间,右侧);添加了红色斑点(右侧)
局限性和未来工作
尽管 AttentionAgent 能够应对环境的各种变化,但是这种方法存在局限性,还需要做更多的工作来进一步增强该智能体的泛化能力。例如,AttentionAgent 不能泛化到背景发生巨大变化的情况。对于在背景为草坪的原始赛车环境中训练的智能体,当背景换为令人分心的 YouTube 视频后,便无法泛化。我们在此基础上进行了进一步研究,当我们将背景替换为纯净的均匀噪声时,发现智能体的注意力模块出现故障,只注意随机噪声区块,而非与道路相关的区块。如果我们一开始就在嘈杂的背景环境中训练智能体,它就能绕赛道行驶,尽管性能很一般。有趣的是,智能体仍然只关注噪声而非道路,它似乎已经学会了根据屏幕左右两侧选定区块的数量来估计车道位置,以此来行驶。

AttentionAgent 无法泛化到经过大幅修改的环境。左侧:背景突然变成一只猫(Creative Commons 视频 1)。中间:背景突然变成街机游戏(Creative Commons 视频 2)。右侧:AttentionAgent 学会了通过避开噪声区块在纯噪声背景下行驶
视频 1
https://www.youtube.com/watch?v=zeeH-Z_Y4as&feature=youtu.be视频 2
https://youtu.be/Q3fpMQ3uqBQ
我们用来从重要区块中提取信息的简单方法可能不足以完成更复杂的任务。如何学习更多有意义的特征,甚至从视觉输入中提取符号信息,将是一个令人兴奋的未来方向。除了向研究社区开放源代码外,我们还发布了 CarRacingExtension,这是一整套涉及各种环境修改的赛车任务,是对有兴趣进行智能体泛化的 ML 研究人员的测试平台和基准。
CarRacingExtension
https://github.com/google/brain-tokyo-workshop/tree/master/CarRacingExtension
致谢
这项研究由 Yujin Tang、Duong Nguyen 和 David Ha 共同完成。Yingtao Tian、Lana Sinapayen、Shixin Luo、Krzysztof Choromanski、Sherjil Ozair、Ben Poole, Kai Arulkumaran、Eric Jang、Brian Cheung、Kory Mathewson、Ankur Handa 以及 Jeff Dean 参与讨论并给出了宝贵意见,在此一并表示感谢。
更多 AI 相关阅读:






