用自己的风格教AI说话,语言生成模型可以这样学
选自 towardsdatascience
作者:Maël Fabie
机器之心编译
参与:Panda
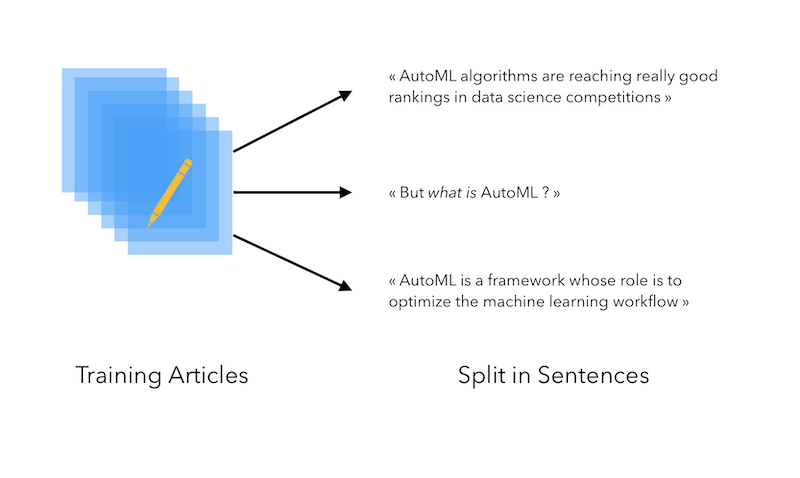
很多研究者和开发者都认为,初学神经网络时,最好的方法莫过于先自己动手训练一个模型。 机器之心也曾推荐过很多不同开发者写的上手教程。 本文同样是其中之一,数据科学家 Maël Fabien 介绍了如何使用自己的博客文章训练一个和自己风格一样的简单语言生成模型。
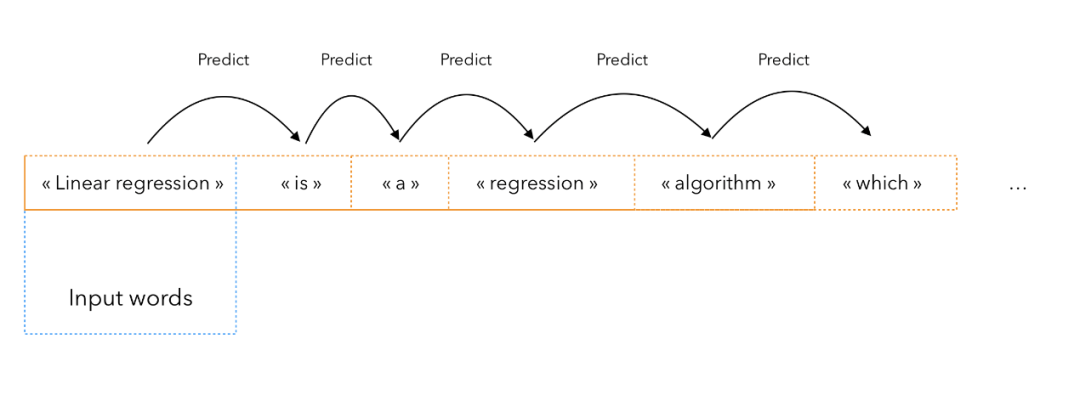
训练一个模型来预测一个序列的下一个词
为训练好的模型提供一个输入
迭代 N 次,使其生成后面的 N 个词

all_sentences= []
for file in glob.glob("*.md"):
f = open(file,'r')
txt = f.read().replace("\n", " ")
try:
sent_text = nltk.sent_tokenize(''.join(txt.split("---")[2]).strip())
for k in sent_text :
all_sentences.append(k)
except :
pass
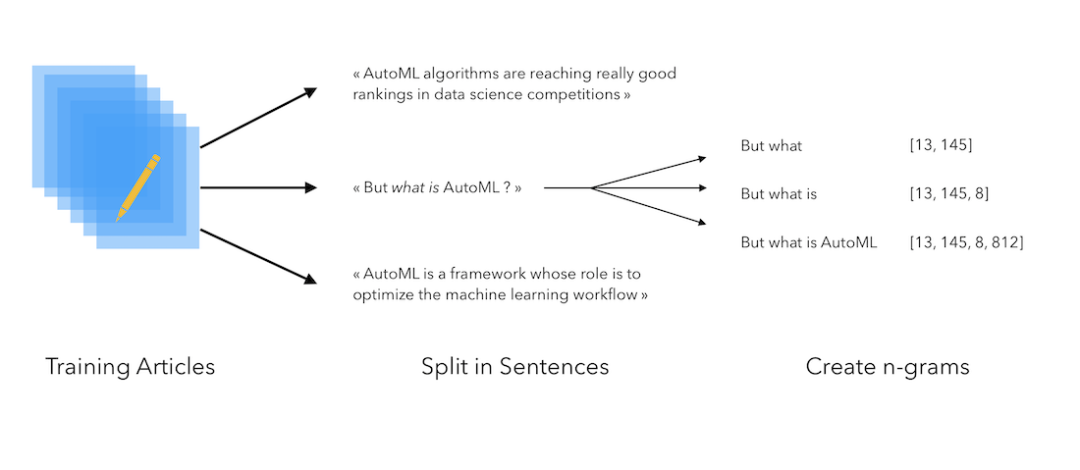
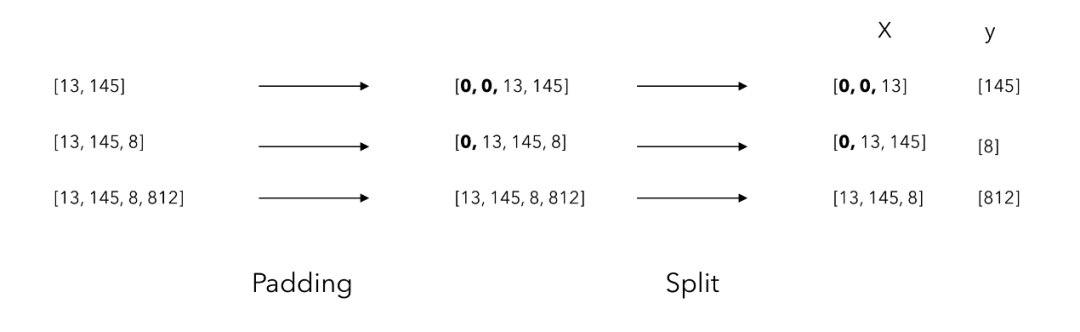
在语料库上使用一个 token 化程序,为每个 token 都关联一个索引
将语料库中的每个句子都分解为一个 token 序列
将一起出现的 token 序列保存起来
tokenizer = Tokenizer()
tokenizer.fit_on_texts(all_sentences)
total_words = len(tokenizer.word_index) + 1
[656, 6, 3, 2284, 6, 3, 86, 1283, 640, 1193, 319]
[33, 6, 3345, 1007, 7, 388, 5, 2128, 1194, 62, 2731]
[7, 17, 152, 97, 1165, 1, 762, 1095, 1343, 4, 656]
[656, 6]
[656, 6, 3]
[656, 6, 3, 2284]
[656, 6, 3, 2284, 6]
[656, 6, 3, 2284, 6, 3]
...
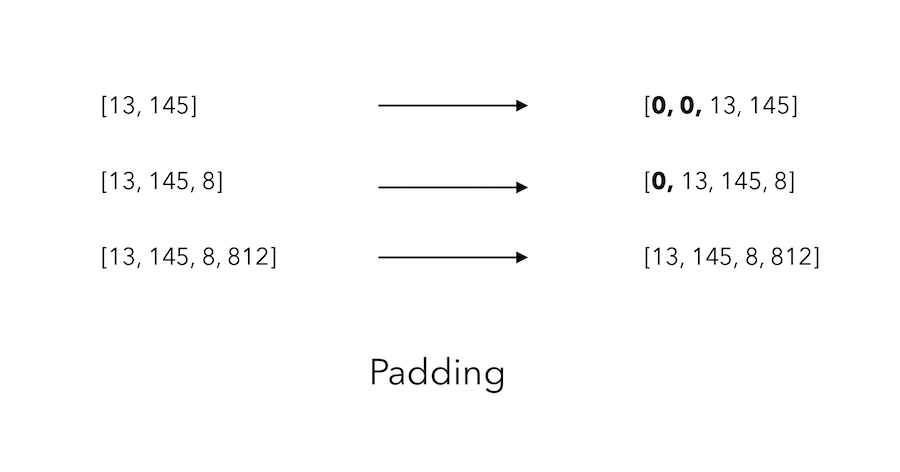
max_sequence_len = max([len(x) for x in input_sequences])
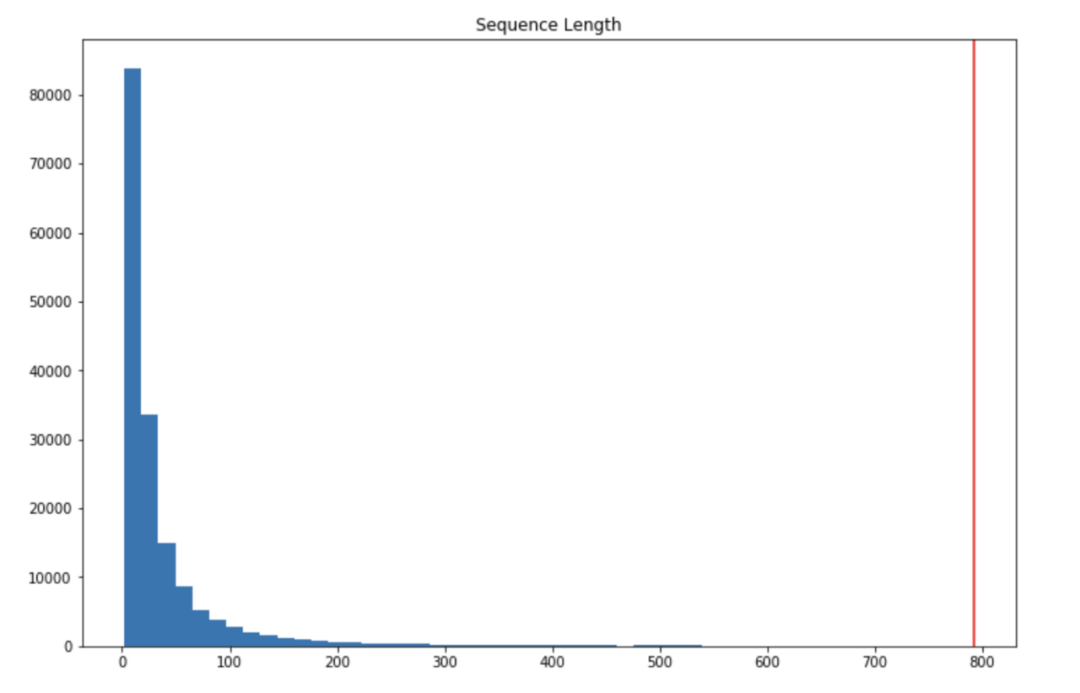
max_sequence_len = 200
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
array([[ 0, 0, 0, ..., 0, 656, 6],
[ 0, 0, 0, ..., 656, 6, 3],
[ 0, 0, 0, ..., 6, 3, 2284],
...,
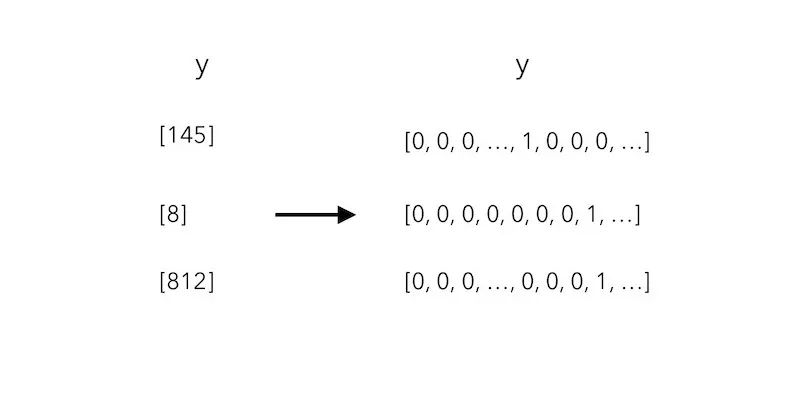
X, y = input_sequences[:,:-1],input_sequences[:,-1]
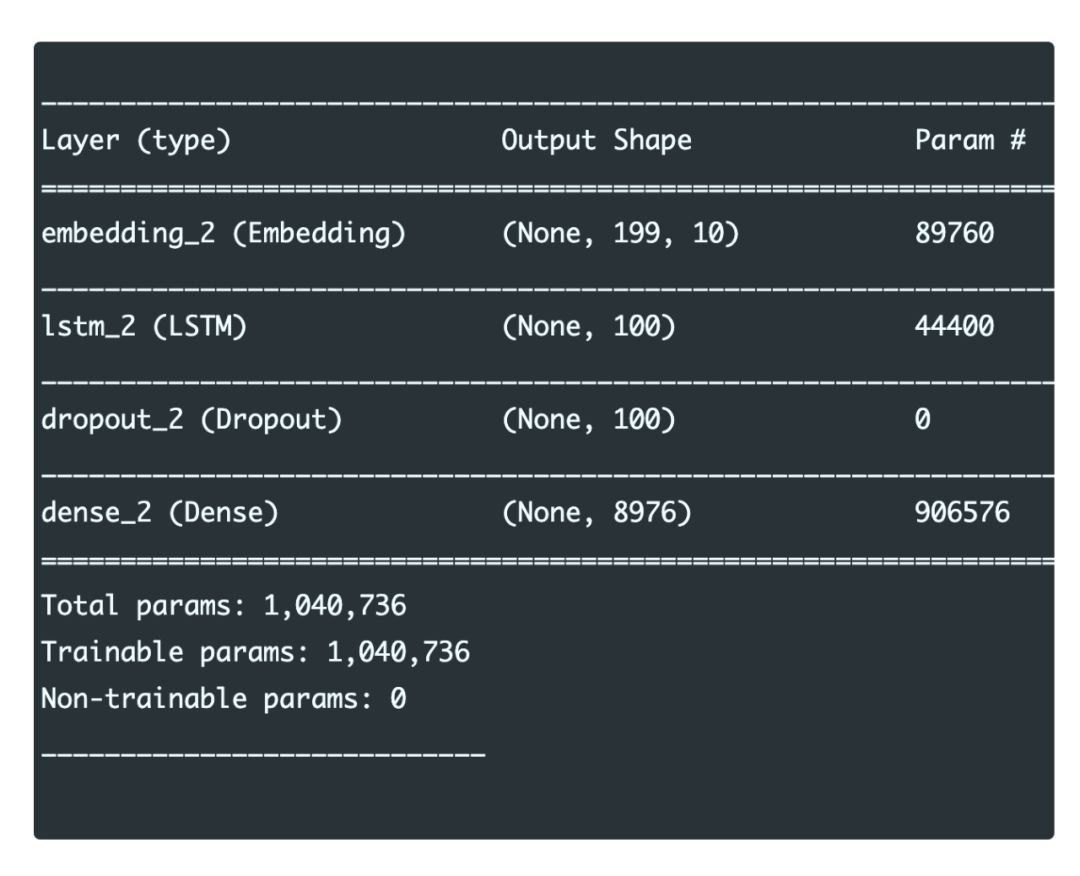
def create_model(max_sequence_len, total_words):
input_len = max_sequence_len - 1
model = Sequential()
# Add Input Embedding Layer
model.add(Embedding(total_words, 10, input_length=input_len))
# Add Hidden Layer 1 - LSTM Layer
model.add(LSTM(100))
model.add(Dropout(0.1))
# Add Output Layer
model.add(Dense(total_words, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
return model
model = create_model(max_sequence_len, total_words)
model.summary()
model.fit(X, y, batch_size=256, epochs=100, verbose=True)
Epoch 1/10
164496/164496 [==============================] - 471s 3ms/step - loss: 7.0687
Epoch 2/10
73216/164496 [============>.................] - ETA: 5:12 - loss: 7.0513
# Modify Import
from keras.layers import Embedding, LSTM, Dense, Dropout, CuDNNLSTM
# In the Moddel
...
model.add(CuDNNLSTM(100))
...

input_txt = "Machine"
for _ in range(10):
# Get tokens
token_list = tokenizer.texts_to_sequences([input_txt])[0]
# Pad the sequence
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
# Predict the class
predicted = model.predict_classes(token_list, verbose=0)
output_word = ""
# Get the corresponding work
for word,index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
input_txt += " "+output_word
模型仍然非常简单
训练数据没有理应的那样整洁
数据量非常有限
登录查看更多
相关内容

专知会员服务
33+阅读 · 2020年2月29日
Arxiv
4+阅读 · 2018年1月26日




相关VIP内容
专知会员服务
33+阅读 · 2020年2月29日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年1月26日