异构表格数据的挑战,深度神经网络如何解?
来自图宾根大学等机构的研究者进行了首个深入研究基于表格数据的深度学习方法的工作,为该领域内的研究者和从业者提供了一份宝贵的指南。

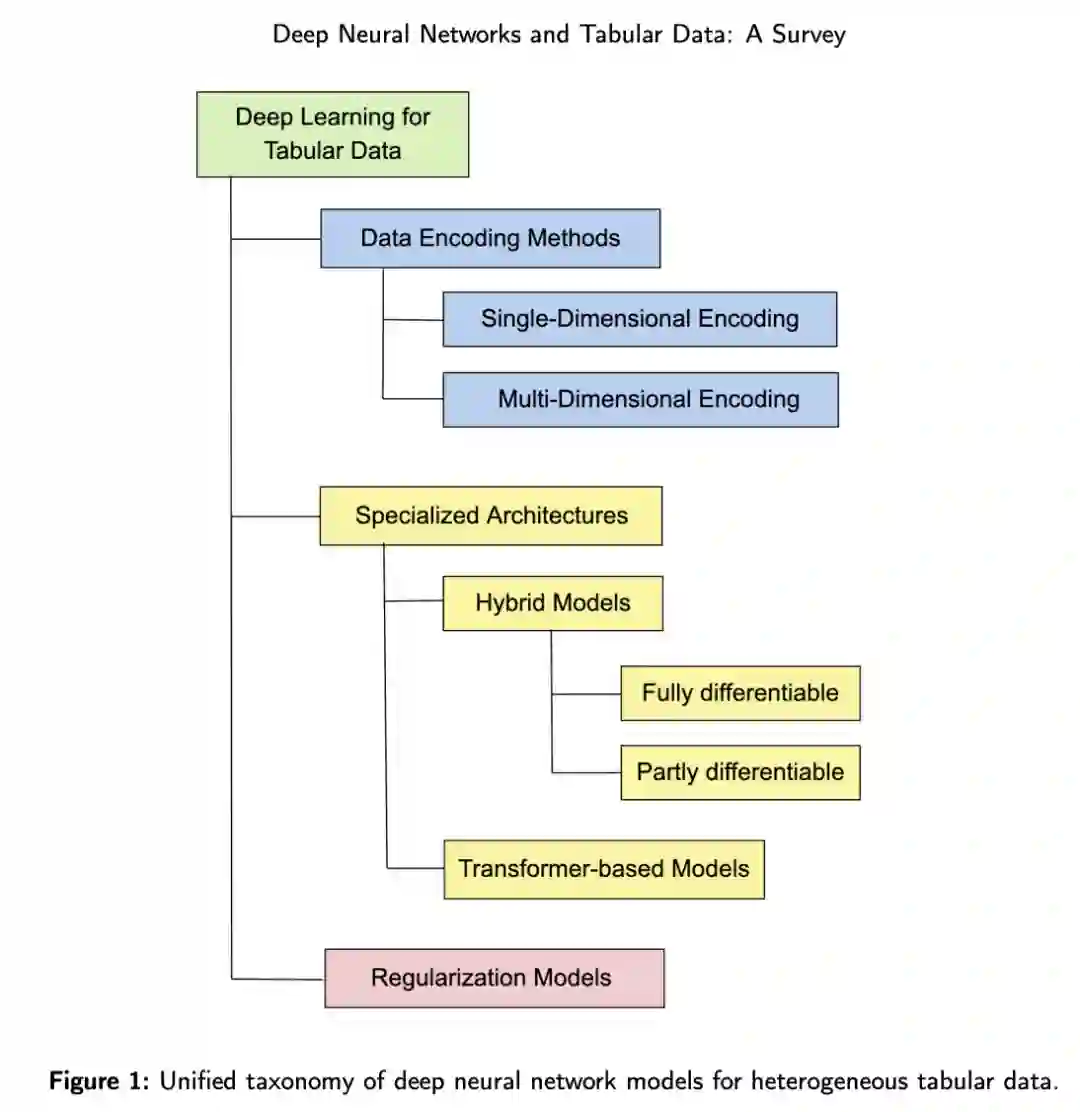
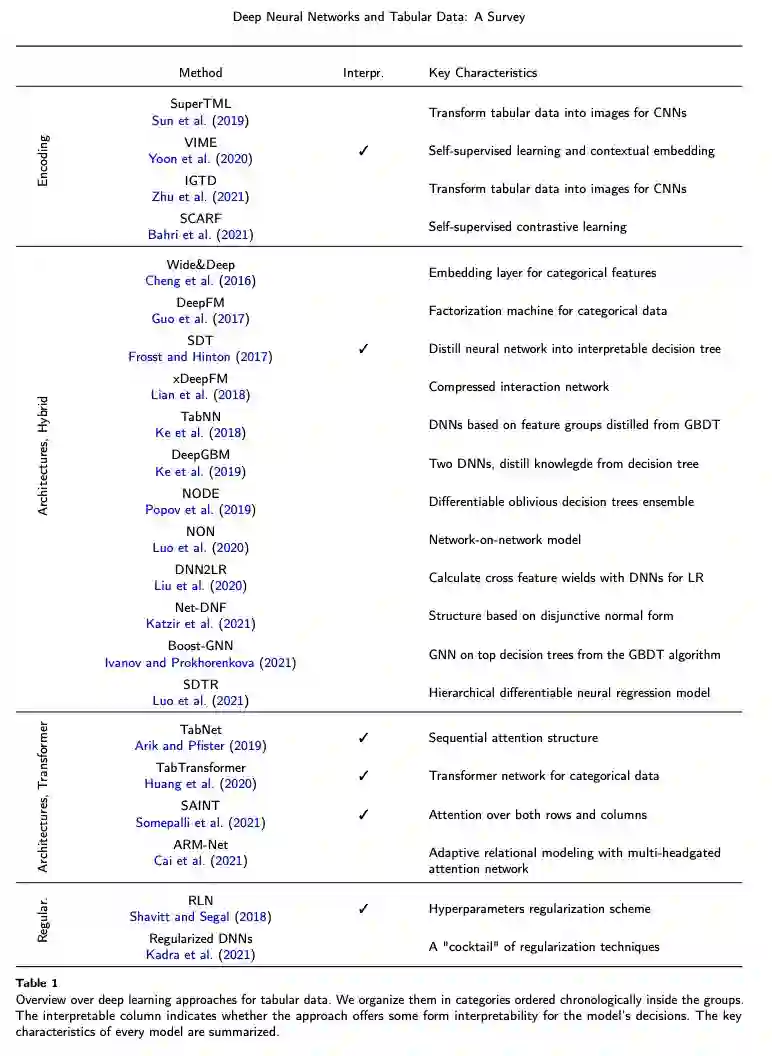
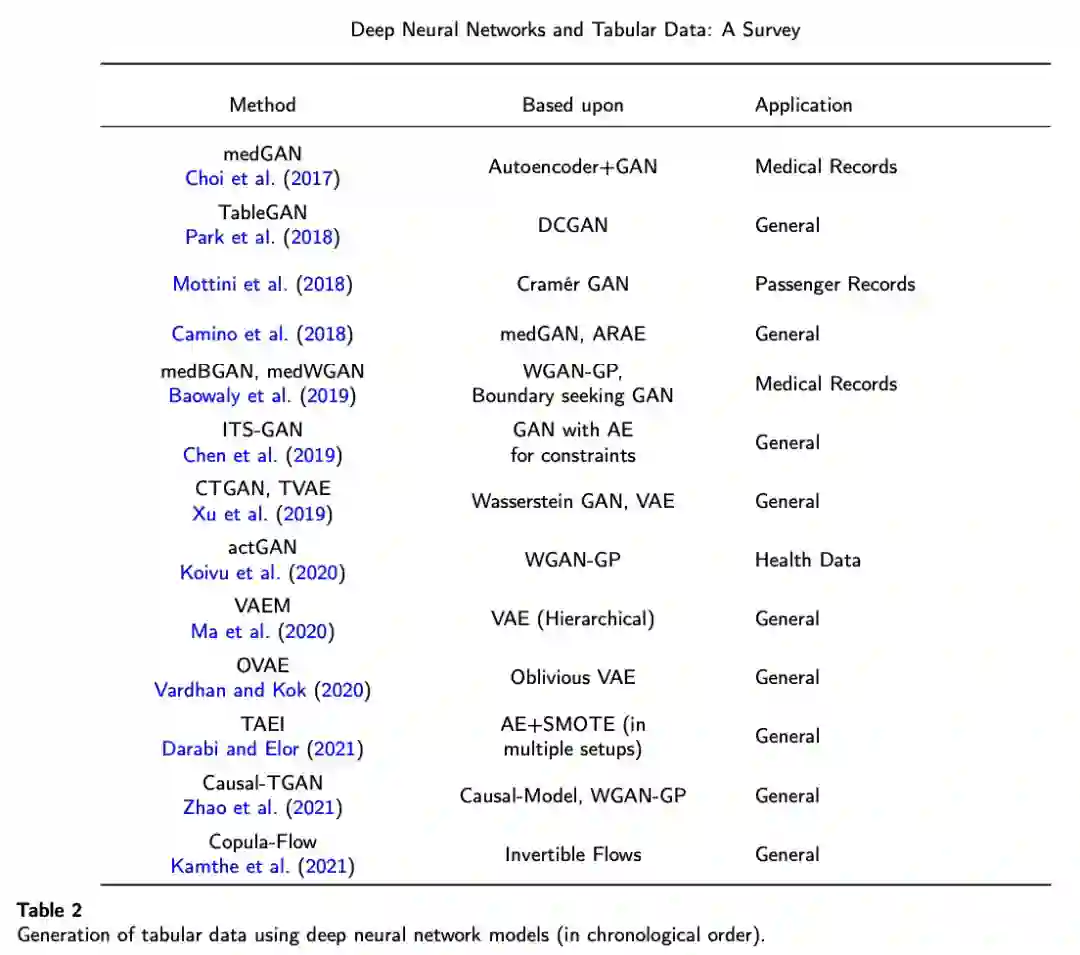
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DNTD” 就可以获取《异构表格数据的挑战,深度神经网络如何解?述》专知下载链接



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月15日
Arxiv
12+阅读 · 2021年8月30日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月15日
Arxiv
12+阅读 · 2021年8月30日