机器之心 & ArXiv Weekly Radiostation
本周主要论文包括:牛津大学研究者在移动的机器人骨架上培养细胞;加州理工用 12 分钟飞行数据教会无人机御风飞行等研究。
Humanoid robots to mechanically stress human cells grown in soft bioreactors
Large Language Models are Zero-Shot Reasoners
NeuralHDHair: Automatic High-fidelity Hair Modeling from a Single Image Using Implicit Neural Representations
Neural-Fly Enables Rapid Learning for Agile Flight in Strong Winds
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Symphony Generation with Permutation Invariant Language Model
A Long Short-Term Memory for AI Applications in Spike-based Neuromorphic Hardware
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Humanoid robots to mechanically stress human cells grown in soft bioreactors
摘要:
组织工程科学是一门以细胞生物学和材料科学相结合,进行体外或体内构建组织或器官的新兴学科,这一技术虽然在很大程度上处于起步阶段,但迄今为止,皮肤细胞、软骨组织甚至是从人体细胞样本中培育出来的气管都已植入患者体内。但事实证明,培养可用的人体肌腱细胞是非常棘手的,这需要拉伸和扭曲。在过去的二十年里,科学家们通过反复向一个方向拉伸肌腱细胞和组织来促进它们的生长和成熟。然而,到目前为止,这种方法还不能产生功能完全的组织移植物,用于临床和人体。
来自牛津大学等机构的研究者提出一种新的组织工程方法可能会提高这项工作的质量:在移动的机器人骨架上培养细胞。
来自牛津大学和机器人公司 Devanthro 的研究人员认为,如果想要培育出能够像肌腱或肌肉一样运动和弯曲的组织,最好是尽可能准确地重现它们的自然生长环境。所以他们决定模仿这样一个移动的人体来培养细胞。研究团队采用机器人来尽可能地模拟人类肌肉骨骼系统。
具体的,他们采用了由 Devanthro 工程师设计的开源机器人骨架,并为可以安装到骨架中的细胞创建了一个定制的生长环境,以根据需要弯曲和拉伸(这种生长环境被称为生物反应器)。他们选择在机器人肩关节上进行组织培养,研究者也将机器人这个部位进行精度升级,以接近人类动作。然后,他们在机器人肩膀上安装生物反应器,该反应器由生物可降解的细丝组成,在两个锚点之间拉伸,像一束头发,整个结构封闭在一个像气球一样的外膜中。
之后研究者将人类细胞移植到毛发状细丝上,并在腔室中注入一种旨在促进细胞生长的富含营养的液体。在 14 天内每天花费半小时来复制人类会做出的各种抬高和旋转动作。
推荐:
在机器人骨架上培养活细胞:将人类细胞放入「生物反应器」,再给点营养液就可以。
论文 2:Large Language Models are Zero-Shot Reasoners
摘要:
「一个玩杂耍的人总共有 16 个球,其中一半是高尔夫球,高尔夫球中又有一半是蓝色的球,请问蓝球总共有多少个?」
对于一个小学生来说,这是一道再简单不过的数学题。但看似无所不能的 GPT-3 却被这道题难住了。如果你输入这个问题之后,直接向 GPT-3 发问:「问题的答案(阿拉伯数字)是:__?」它会「不假思索」地给出一个错误答案:8。
怎么能让 GPT-3 稍微「动动脑子」呢?想想我们上学的时候老师是怎么做的。一般来说,优秀的老师会在我们做错题时鼓励我们「再回去想想」,或者帮我们理清解题步骤。同样的,我们也可以这么对 GPT-3。东京大学和谷歌大脑的一项联合研究表明,只要在答案前加一句「 Let’s think step by step 」,GPT-3 就能给出上述问题的正确答案,而且它还自己理清了解题步骤。
在经典的 MutiArith 数据集上,这句魔法一样的「咒语」将 GPT-3 在零样本场景下解数学题的准确性从 17.7% 提升到了 78.7%。重要的是,这句「咒语」的应用范围还非常广泛,不仅可以解数学题,还能做各种逻辑推理。
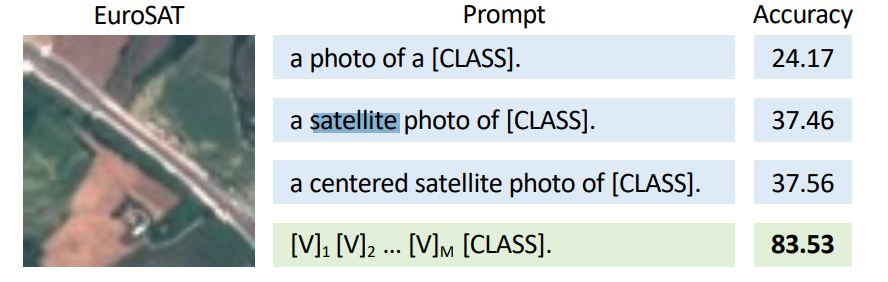
当然,在深度学习领域,这种「咒语」有个统一的名字——「prompt」。prompt 和 prompt 工程是近年来非常火的话题,它可以帮助我们控制模型的预测输出。合适的 prompt 对于模型的效果至关重要,大量研究表明,prompt 的微小差别,可能会造成效果的巨大差异 [1]。比如在下面这个卫星图片识别的例子中,我们仅添加一个「 satellite(卫星)」,就能把模型的准确率提升 13%+。
推荐:
GPT-3 对一些问题的回答令人大跌眼镜,但它可能只是想要一句「鼓励」。
论文 3:NeuralHDHair: Automatic High-fidelity Hair Modeling from a Single Image Using Implicit Neural Representations
摘要:
来自浙江大学、瑞士苏黎世联邦理工学院和香港城市大学的研究者提出了 IRHairNet,实施一个由粗到精的策略来生成高保真度的 3D 方向场。具体来说,他们引入了一种新颖的 voxel-aligned 的隐函数(VIFu)来从粗糙模块的 2D 方向图中提取信息。同时,为了弥补 2D 方向图中丢失的局部细节,研究者利用高分辨率亮度图提取局部特征,并结合精细模块中的全局特征进行高保真头发造型。
为了有效地从 3D 方向场合成头发丝模型,研究者引入了 GrowingNet,一种基于深度学习利用局部隐式网格表征的头发生长方法。这基于一个关键的观察:尽管头发的几何形状和生长方向在全局范围内有所不同,但它们在特定的局部范围内具有相似的特征。因此,可以为每个局部 3D 方向 patch 提取一个高级的潜在代码,然后训练一个神经隐函数 (一个解码器) 基于这个潜在代码在其中生长头发丝。在每一个生长步骤之后,以头发丝的末端为中心的新的局部 patch 将被用于继续生长。经过训练后,它可适用于任意分辨率的 3D 定向场。
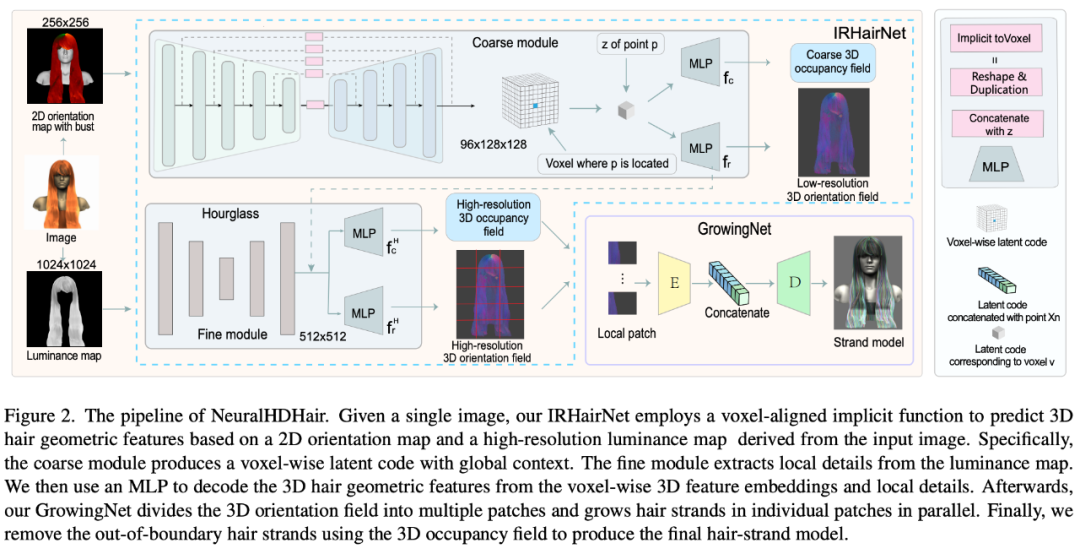
图 2 展示了 NeuralHDHair 的 pipeline。对于人像图像,首先计算其 2D 方向图,并提取其亮度图。此外,自动将它们对齐到相同的半身参考模型,以获得半身像深度图。然后,这三个图随后被反馈到 IRHairNet。
IRHairNet 设计用于从单个图像生成高分辨率 3D 头发几何特征。这个网络的输入包括一个 2D 定向图、一个亮度图和一个拟合的半身深度图,这些都是从输入的人像图中得到的。输出是一个 3D 方向字段,其中每个体素内包含一个局部生长方向,以及一个 3D 占用字段,其中每个体素表示发丝通过 (1) 或不通过 (0)。
GrowingNet 设计用于从 IRHairNet 估计的 3D 定向场和 3D 占用字段高效生成一个完整的头发丝模型 ,其中 3D 占用字段是用来限制头发的生长区域。
推荐:
3D 头发建模新方法 NeuralHDHair,浙大、ETH Zurich、CityU 联合出品。
论文 4:Neural-Fly Enables Rapid Learning for Agile Flight in Strong Winds
摘要:
目前来看,无人机要么在受控条件下飞行,无风;要么由人类使用遥控器操作。无人机被研究者控制在开阔的天空中编队飞行,但这些飞行通常是在理想的条件和环境下进行的。然而,要想让无人机自主执行必要但日常的任务,例如运送包裹,无人机必须能够实时适应风况。
为了让无人机在风中飞行时具有更好的机动性,来自加州理工学院的一组工程师开发了一种深度神经网络 Neural-Fly,即一种人工智能工具,可以让无人机在有风的情况下保持敏捷,只需更新一些关键参数,即可帮助无人机实时应对新的和未知的风况。
下面展示了一架四旋翼无人机,借助该研究开发的工具,它可以在风速达到 27 英里 / 小时的情况下完成 8 字形穿梭操作:
![]()
这项研究已于周三发表在《科学 · 机器人学》(Science Robotics) 杂志上。
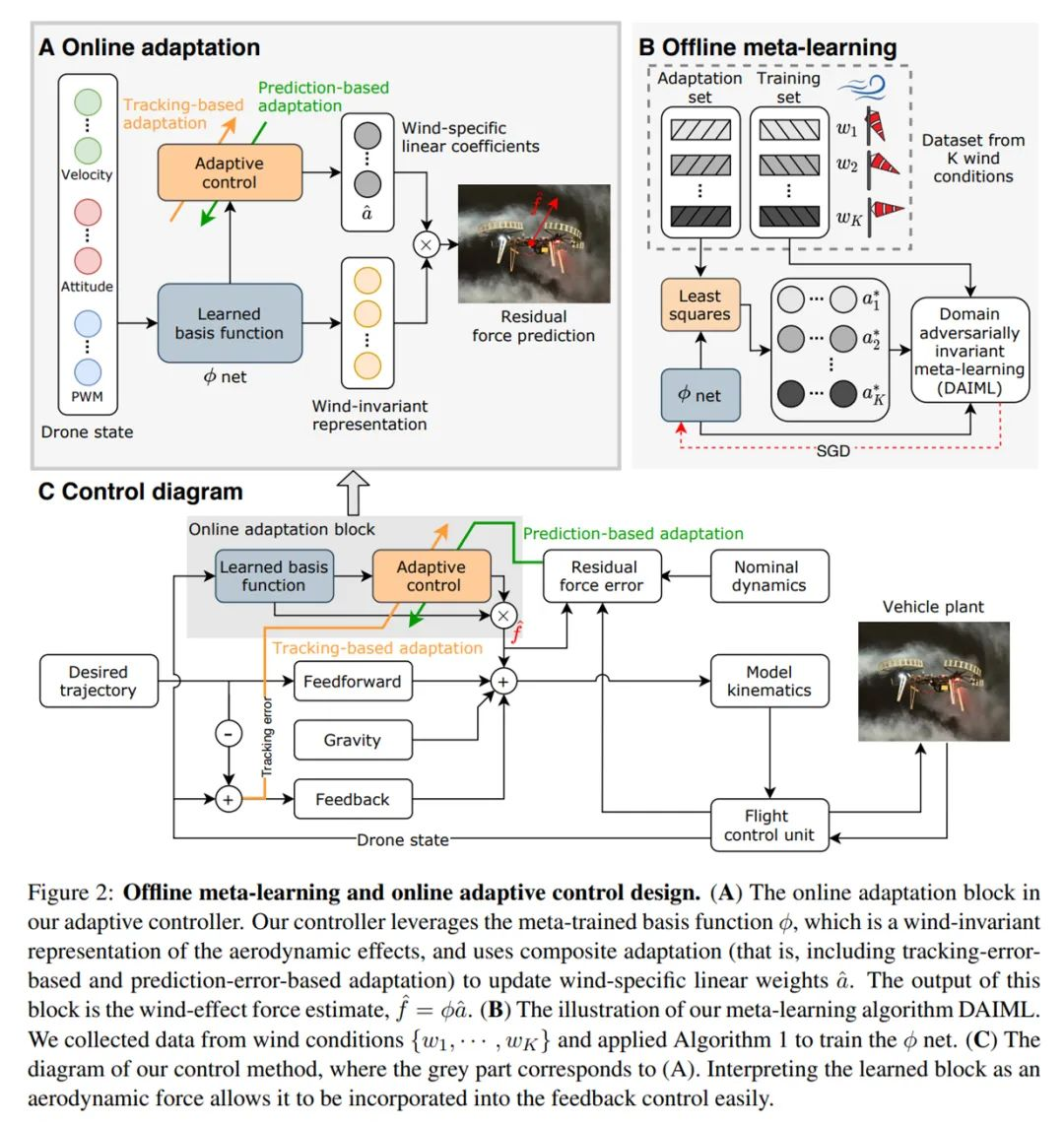
下图 2 为 Neural-Fly 方法概览,表明了它在自适应飞行控制和基于深度学习的机器人控制方面取得了进展。在标准 UAV 的动态风况下,Neural-Fly 实现了对灵活且具有挑战性轨迹的厘米级位置误差跟踪。具体来说,该方法主要有两部分组成,分别是离线学习阶段和用于实时在线学习的在线自适应控制阶段。
![]()
对于离线学习阶段,研究者开发了域对抗不变元学习(Domain Adversarially Invariant Meta-Learning, DAIML),它以一种数据高效的方式学习空气动力学与风况无关的深度神经网络(DNN)表示。该表示通过更新一组混合深度神经网络输出的线性系数来适应不同的风况。DAIML 还具有数据高效性,仅使用 6 种不同风况下共计 12 分钟的飞行数据来训练深度神经网络。DAIML 包含的几种关键特性不仅可以提升数据效率,而且能够由下游在线自适应控制阶段提供信息。
推荐:
稳当扛住强风的无人机你见过吗?加州理工用 12 分钟飞行数据教会无人机御风飞行。
论文 5:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
摘要:
来自谷歌的研究者提出了一种文本到图像的扩散模型 Imagen。
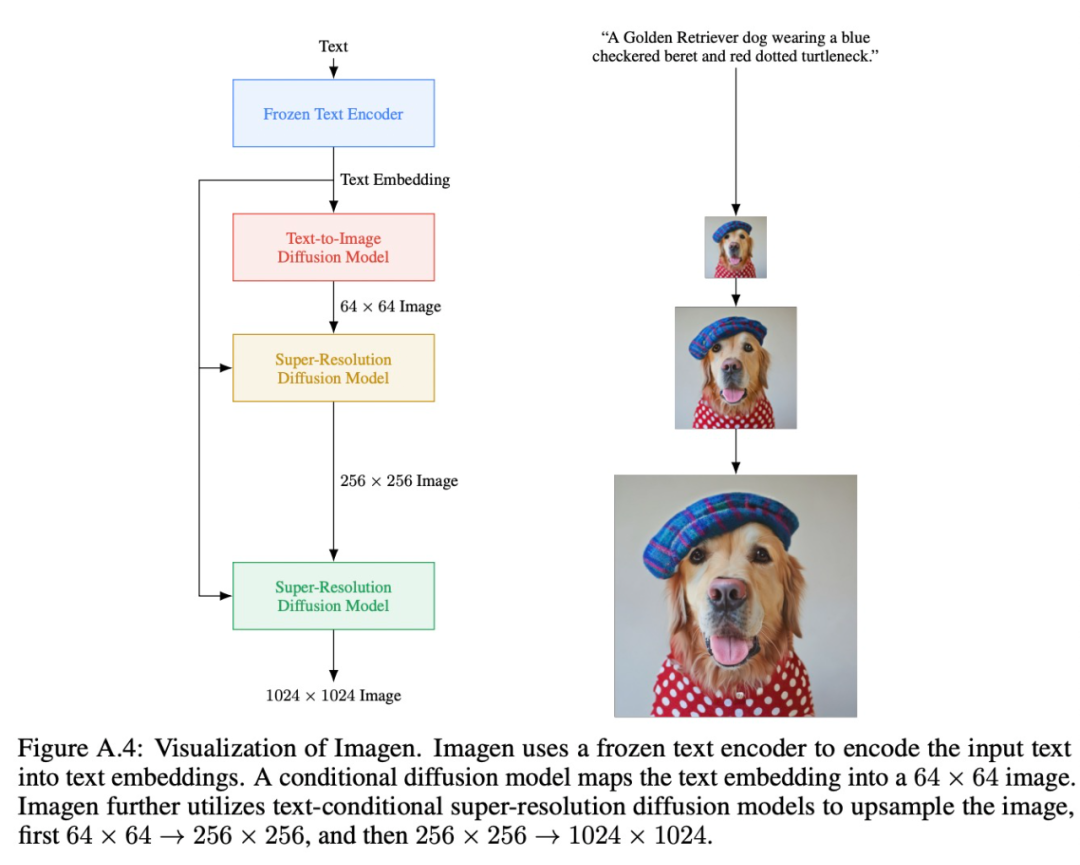
Imagen 结合了 Transformer 语言模型和高保真扩散模型的强大功能,在文本到图像的合成中提供前所未有的逼真度和语言理解能力。与仅使用图像 - 文本数据进行模型训练的先前工作相比,Imagen 的关键突破在于:谷歌的研究者发现在纯文本语料库上预训练的大型 LM 的文本嵌入对文本到图像的合成显著有效。Imagen 的文本到图像生成可谓天马行空,能生成多种奇幻却逼真的有趣图像。
Imagen 模型中包含一个 frozen T5-XXL 编码器,用于将输入文本映射到一系列嵌入和一个 64×64 的图像扩散模型中,并带有两个超分辨率扩散模型,用于生成 256×256 和 1024×1024 的图像。
其中,所有扩散模型都以文本嵌入序列为条件,并使用无分类器指导。借助新型采样技术,Imagen 允许使用较大的指导权重,而不会发生样本质量下降,使得生成的图像具有更高的保真度、图像与文本更加吻合。
推荐:
叫板 DALL·E 2,预训练大模型做编码器,谷歌把文字转图像模型卷上天。
论文 6:Symphony Generation with Permutation Invariant Language Model
摘要:
音乐生成是近年的一个热门研究方向,但以交响乐为代表的复杂多轨道符号音乐生成,目前还面临诸多挑战。本文提出了一个基于符号的交响乐生成解决方案—SymphonyNet,此外本文还开源了首个大规模交响乐 MIDI 数据集!相信不久之后大家都可以训练自己的交响乐生成 AI 了。
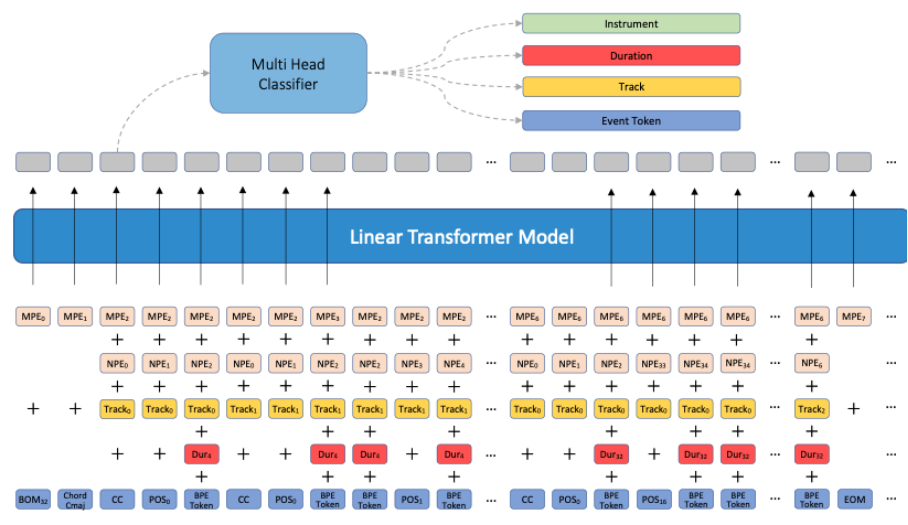
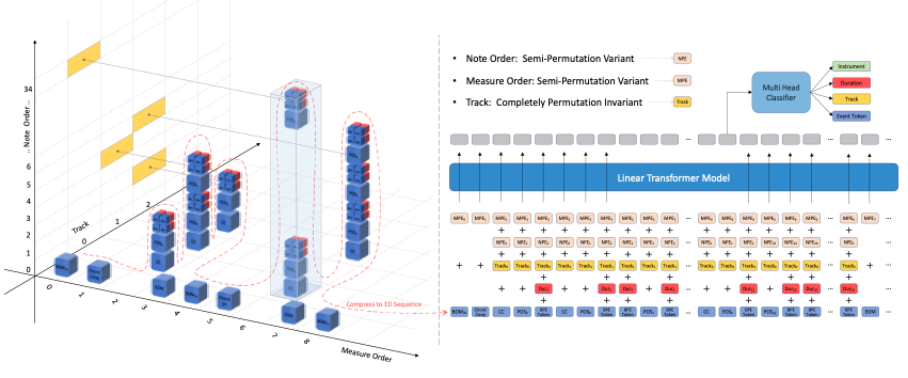
基于多轨道音乐的特点,本文设计了一种基于线性自注意力的纯解码器结构,由于音乐序列的多维特性,本文为音乐事件的四个属性设计了不同的前馈输出头,这些属性是乐器,轨道,音符时长和事件符号。
其中,本文没有明确地将乐器相关信息编码到模型输入中,而是训练模型将每个音符的乐器分类作为一项联合训练任务。首先,本文考虑到另一种乐器也可以演奏由特定乐器演奏的音轨,例如在某些音乐作品中,用钢琴代替马林巴琴是可以接受的。其次,为音符预先分配的乐器缩小了训练数据的多样性,同时希望该模型能从输出端学习到如何自动配器,完整结构如下图所示:
推荐:
中央音乐学院用 AI 生成交响乐在国外火了!
论文 7:A Long Short-Term Memory for AI Applications in Spike-based Neuromorphic Hardware
摘要:
随着智能手机的普及,手机游戏也越来越受欢迎。但视频游戏等程序会大量耗电耗能。与 GPU 等标准硬件相比,基于 spike 的神经形态芯片有望实现更节能的深度神经网络(DNN)。但这需要我们理解如何在基于 event 的稀疏触发机制(sparse firing regime)中模拟 DNN,否则神经形态芯片的节能优势就会丧失。
比如说,解决序列处理任务的 DNN 通常使用长 - 短期记忆单元(LSTM),这种单元很难模拟。现在有一项研究模拟了生物神经元,通过放慢每个脉冲后的超极化后电位(AHP)电流,提供了一种有效的解决方案。AHP 电流可以很容易地在支持多节段(multi-compartment)神经元模型的神经形态硬件(例如英特尔的 Loihi 芯片)上实现类似于 LSTM 的功能。
滤波器逼近理论能够解释为什么 AHP 神经元可以模拟长短期记忆网络的功能。这产生了一种高能效的时间序列分类方法,让类脑神经形态芯片上的 AI 算法能效提高约 1000 倍。此外,它为高效执行大型 DNN 提供了基础,以解决有关自然语言处理的问题。研究论文近期发表在《自然 · 机器智能》期刊上。
曼彻斯特大学的计算机科学家 Steve Furber 评价这项研究称:「这是一项令人印象深刻的工作,可能给复杂 AI 算法(例如语言翻译、自动驾驶)的性能带来巨大飞跃。」
推荐
:
Nature 子刊:科学家在类脑芯片上实现类似 LSTM 的功能,能效高 1000 倍
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. Heterformer: A Transformer Architecture for Node Representation Learning on Heterogeneous Text-Rich Networks. (from Jiawei Han)
2. All Birds with One Stone: Multi-task Text Classification for Efficient Inference with One Forward Pass. (from Jiawei Han)
3. A Survey on Neural Open Information Extraction: Current Status and Future Directions. (from Jian Sun)
4. How Human is Human Evaluation? Improving the Gold Standard for NLG with Utility Theory. (from Dan Jurafsky)
5. Translating Hanja historical documents to understandable Korean and English. (from Kyunghyun Cho)
6. DKG: A Descriptive Knowledge Graph for Explaining Relationships between Entities. (from Kevin Chen-Chuan Chang, Wen-mei Hwu)
7. Seeded Hierarchical Clustering for Expert-Crafted Taxonomies. (from Kathleen McKeown)
8. Penguins Don't Fly: Reasoning about Generics through Instantiations and Exceptions. (from Kathleen McKeown)
9. Self-Supervised Speech Representation Learning: A Review. (from Abdelrahman Mohamed, Tara N. Sainath)
10. Unsupervised Learning of Hierarchical Conversation Structure. (from Noah A. Smith, Mari Ostendorf)
本周 10 篇 CV 精选论文是:
1. Deep Learning for Visual Speech Analysis: A Survey. (from Matti Pietikäinen, Li Liu)
2. GL-RG: Global-Local Representation Granularity for Video Captioning. (from Xiangyu Zhang)
3. Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners. (from Derek Hoiem, Shih-Fu Chang)
4. Towards Better Understanding Attribution Methods. (from Bernt Schiele)
5. B-cos Networks: Alignment is All We Need for Interpretability. (from Bernt Schiele)
6. VPAIR -- Aerial Visual Place Recognition and Localization in Large-scale Outdoor Environments. (from Daniel Cremers)
7. Knowledge Distillation via the Target-aware Transformer. (from Gang Wang)
8. Transformer-based out-of-distribution detection for clinically safe segmentation. (from Sebastien Ourselin)
9. Visual Concepts Tokenization. (from Nanning Zheng)
10. A Peek at Peak Emotion Recognition. (from Shmuel Peleg)
本周 10 篇 ML 精选论文是:
1. Byzantine-Robust Federated Learning with Optimal Statistical Rates and Privacy Guarantees. (from Michael I. Jordan)
2. Exploring the Trade-off between Plausibility, Change Intensity and Adversarial Power in Counterfactual Explanations using Multi-objective Optimization. (from Francisco Herrera)
3. Towards Understanding Grokking: An Effective Theory of Representation Learning. (from Max Tegmark)
4. A Survey of Trustworthy Graph Learning: Reliability, Explainability, and Privacy Protection. (from Liang Chen)
5. MaskGAE: Masked Graph Modeling Meets Graph Autoencoders. (from Liang Chen)
6. MultiBiSage: A Web-Scale Recommendation System Using Multiple Bipartite Graphs at Pinterest. (from Srinivasan Parthasarathy, Jure Leskovec)
7. Planning with Diffusion for Flexible Behavior Synthesis. (from Joshua B. Tenenbaum, Sergey Levine)
8. Mapping Emulation for Knowledge Distillation. (from Dacheng Tao)
9. Penalized Proximal Policy Optimization for Safe Reinforcement Learning. (from Dacheng Tao)
10. History Compression via Language Models in Reinforcement Learning. (from Sepp Hochreiter)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com