如何高效实现 9 万数据的异常排查?附完整心路历程


作者 | Einstellung
责编 | 郭芮
首先介绍一下背景。笔者参加的一个关于风机开裂故障分析的预警比赛。训练数据有将近5万个样本,测试数据近9万。数据来自SCADA采集系统。采集了10分钟之内的75个特征值的数据信息,label是一周以内风机是否会发生故障的label。

数据介绍
每个样本10分钟之内大概采集到了450条数据,一共75个特征,也就是差不多75*450个信息。最后三个特征完全没有数据,所以一开始做的时候,我们就把最后三个特征进行删除,所以实际上是对72个特征进行的数据分析。
最开始,用的是seaborn画的正常风机和不正常风机的频率分布图,比如说对于轮毂转速这个特征:
1import seaborn as snsimport pandas as pd
2data_file = r"D:\fan_fault\feature1.csv"
3pre_process = pd.read_csv(data_file, encoding = "gbk")
4
5pre_process = pre_process.fillna(0)
6feature1_plot = pre_process["normal(0)"]
7
8feature2_plot2 = pre_process["fault(1)"]
9sns.kdeplot(feature1_plot, shade = True)
10sns.kdeplot(feature2_plot2, shade = True)
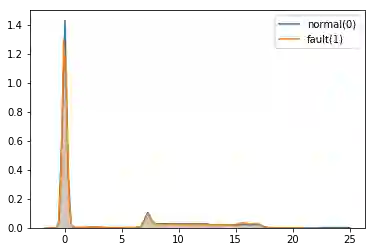
大部分特征都是这样,没有很好的区分度。正是因为如此,也一直没有尝试出来非常好的模型。后来我们尝试用MATLAB画图,每个特征出两个图:
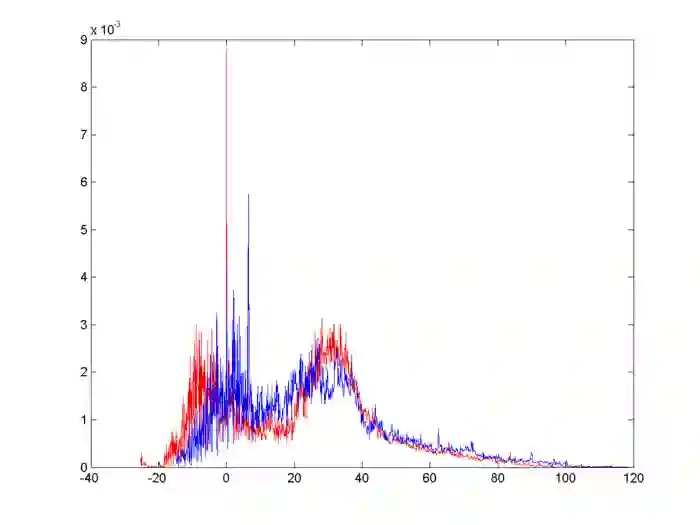
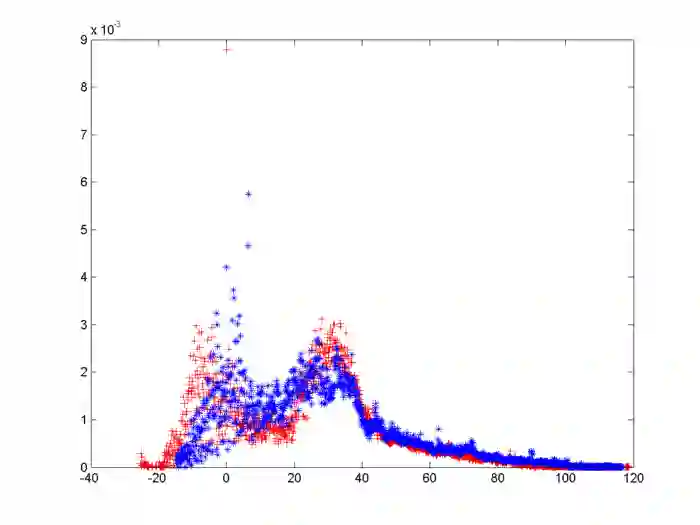
看起来要比seaborn好一些(后两个图和第一个不是一个特征)。我们在做数据分析这一块很大的问题是在于只去查了各个特征的物理含义,做了频率和频数分布图,看看是否有没有好的特征,然后就直接进入了下一步。忘了考虑是否可能会出现因为采集问题而导致的异常值和空缺值问题。这一点导致后面我们的很多工作都需要推倒重来。
数据分析
我们从统计上来看,并没有找到很好的区分度特征,然后就考虑从物理上来找。在老师的建议下,我们尝试了有轮毂转速,风速为6.5m/s时,y方向振动值的特征:
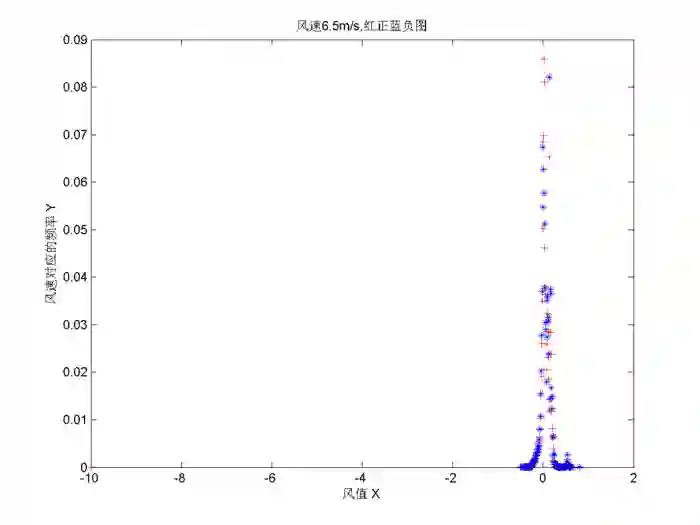
依旧没有很好的区分度,对于其他风速尝试也是如此。
随后我们讨论到了阈值、记0等方式构造新特征。在考虑记0这个新特征构造办法时,突然发现大气压力这个特征居然有0的情况。根据物理学的知识来讲,风机的大气压力是不可能为0的。然后我们才想起来,没有对数据的异常值进行处理。删除了有8万多条整行全为0的数据,导致某些文件为空,也就是这个风机没有数据信息。当然,也有某些风机是某几行为0。
除了删除空缺值,我们还对其他明显是异常的数据进行了一些数据清洗工作。因为之前我们对于数据特征数统计分析是根据未清洗的数据做的分析,所以分析的可靠性也有点问题,后面就产生了一些不必要的麻烦。我们也做了一些相关性分析的工作,大部分特征相关性十分的高。几十个特征两两组合然后进行相关性分析,会有数千个结果,相关性分析没有办法进行下去。后来,我们就没有考虑相关性的事情。
特征工程
我们最开始尝试对前72个特征构造均值,作为基准尝试看看效果如何。
1import os
2import pandas as pd
3import numpy as np
4import csv
5
6label_file = r"C:\fan_fault\train\trainX"
7train_mean = r"D:\fan_fault\train_mean_new.csv"
8
9with open(train_mean, "a", newline = '', encoding = "utf-8") as f:
10 train_mean = csv.writer(f)
11
12 for x in range(1, 48340):
13 fan_file = os.path.join(label_file, str(x) + ".csv")
14 print("程序运行进度为", x/48340) #用该语句查看工作进度状态
15
16 with open(fan_file, encoding='utf-8') as f:
17 feature_read = pd.read_csv(f)
18 #遍历打开文件的每一个特征(72),求取均值
19 # a用来临时存放计算好的特征均值,外加一个label
20
21 a = []
22 for i in range(72):
23 mean_num = feature_read.iloc[:, i]
24 mean_num = np.array(mean_num).mean()
25 #生成每个特征所有数据对应的均值
26 a.append(mean_num)
27
28 train_mean.writerow(a)也包括绝对值差分累计、差分均值、差分方差,用随机森林进行调参。
1# -*- coding: utf-8 -*-"""
2
3import numpy as np
4import pandas as pd
5from sklearn.preprocessing import MinMaxScaler
6from sklearn.ensemble import RandomForestClassifier
7from sklearn.model_selection import cross_val_scorefrom sklearn
8import metrics
9from sklearn.model_selection import GridSearchCV
10
11#数据导入、检查空缺值
12data = pd.read_csv(r'D:\next\8_19\train_data.csv',encoding = "gbk")
13label = pd.read_csv(r"D:\next\8_19\train_label.csv")
14data.info()
15data.notnull().sum(axis=0)/data.shape[0]
16train = data.iloc[:,:-1]
17label = label.iloc[:,-1]
18
19#数据标准化
20scaler = MinMaxScaler()
21train = scaler.fit(train).transform(train)
22
23#单个分类器
24clf = RandomForestClassifier(random_state=14)
25f1 = cross_val_score(clf, train, label, scoring='f1')
26print("f1:{0:.1f}%".format(np.mean(f1)*100))
27
28#调参
29parameter_space = {
30 'n_estimators':range(10,200,10),
31 'max_depth':range(1,10),
32 'min_samples_split':range(2,10),
33 }
34clf = RandomForestClassifier(random_state=14)
35grid = GridSearchCV(clf,parameter_space,scoring='f1', n_jobs = 6)
36grid.fit(train,label)
37print("f1:(0:.1f)%".format(grid.best_score_*100))
38print(grid.best_estimator_)
39
40#调参后的分类器
41new_clf = RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
42 max_depth=7, max_features='auto', max_leaf_nodes=None,
43 min_impurity_decrease=0.0, min_impurity_split=None,
44 min_samples_leaf=1, min_samples_split=7,
45 min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
46 oob_score=False, random_state=14, verbose=0,warm_start=False)
47print("f1:{0:.1f}%".format(np.mean(f1)*100))测试集输出预测结果如下:
1#数据标准化
2scaler = MinMaxScaler()
3train = scaler.fit(train).transform(train)
4test = scaler.fit(test).transform(test)
5
6#训练分类器
7clf = RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
8 max_depth=8, max_features='auto', max_leaf_nodes=None,
9 min_impurity_decrease=0.0, min_impurity_split=None,
10 min_samples_leaf=1, min_samples_split=5,
11 min_weight_fraction_leaf=0.0, n_estimators=20, n_jobs=5,
12 oob_score=False, random_state=14, verbose=0, warm_start=False)
13clf = clf.fit(train, label)
14#预测结果
15pre = clf.predict(test)
16
17#测试结果文件写入
18import csv
19
20label = r"D:/fan_fault/label.csv"
21
22with open(label, "w", newline = '', encoding = "utf-8") as f:
23 label = csv.writer(f)
24
25 for x in range(len(pre)):
26 label.writerow(pre[x:x+1])测试效果来看,并没有取得十分理想的效果。
之后想起来没有考虑数据清洗,之前的工作全部推倒从来。我们在此期间,也调查整理关于这72个特征和风机叶片开裂故障的原因,发现从文献上没有找到和叶片开裂故障有很好相关性的特征,对于特征进行的改造也没有很好的区分效果。后期我们咨询过相关行业的工程师,他们说这些特征中也没有十分强相关性的特征。我们就考虑到特征之间两两交叉相乘看看效果。
1# 交叉特征有2844列,分别是自身的平方和相互交叉,最后求均值方差,最后三个特征不单独再生成交叉特征
2
3import os
4import pandas as pd
5import numpy as np
6import csv
7from sklearn.preprocessing import PolynomialFeatures
8
9label_file = r"F:\User\Xinyuan Huang\train_labels.csv"
10fan_folder = r"F:\User\Xinyuan Huang"
11read_label = pd.read_csv(label_file)
12
13cross_var = r"F:\User\Xinyuan Huang\CaiJi\Feature_crosses\cross_var.csv"
14
15with open(cross_var, "a", newline = '', encoding = "utf-8") as f:
16 cross_var = csv.writer(f)
17
18 # 该for循环用于定位要打开的文件
19 for x in range(len(read_label)-1):
20 column1 = str(read_label["f_id"][x:x+1])
21 #遍历DataFrame第一列的f_id标签下面的每一个数
22 column2 = str(read_label["file_name"][x:x+1])
23 #遍历DataFrame第二列的file_name标签下面的每一个数
24 column3 = str(read_label["ret"][x:x+1])
25 #遍历DataFrame第三列的ret标签下面的每一个数
26
27 f_id = column1.split()[1]
28 #第一行的文件所对应的f_id进行切片操作,获取对应的数字
29 # 对f_id进行补0操作
30 f_id = f_id.zfill(3)
31 # 比如2补成002,所以这里写3
32 file_name = column2.split()[1]
33 #第一行的文件所对应的file_name
34 label = column3.split()[1]
35 #第一行文件所对应的ret
36
37 fan_file = os.path.join(fan_folder, "train", f_id, file_name)
38 print("程序运行进度为", x/(len(read_label)-1))
39 #用该语句查看工作进度状态
40
41 # 打开相应的fan_file文件进行读取操作
42 with open(fan_file, encoding='utf-8') as f:
43 dataset = pd.read_csv(f)
44 #数据集名称为dataset
45 poly = PolynomialFeatures(degree=2, include_bias=False,interaction_only=False)
46 X_ploly = poly.fit_transform(dataset)
47 data_ploly = pd.DataFrame(X_ploly, columns=poly.get_feature_names())
48
49 new_data = data_ploly.ix[:,75:-6]
50
51 #ploly_mean,ploly_var为交叉特征均值方差
52 ploly_mean = np.mean(new_data)
53 ploly_var = np.var(ploly_mean)
54
55 ploly_var = list(ploly_var)
56 ploly_var.append(label)
57
58 cross_var.writerow(ploly_var)交叉相乘之后的文件有数千个特征,生成的文件有将近2G大小。考虑到服务器性能不高,计算旷日持久。不对特征进行筛选,直接进行交叉之后跑算法这条路被我们放弃了。
后来阜特科技的杨工帮我们筛选了一些比较重要的特征,我们在此基础之上进行了一些特征交叉和重要性排序的操作,特征缩小到了几百个(包含交叉、均值、方差等,经过重要性排序),然后用它来跑得模型。
特征里面有一些特征是离散特征,对于这些特征我们进行单独处理,进行离散化。比如说偏航要求值总共有3个值分别是1,2,3。我们对其进行离散化处理,一个特征就变成了三个特征。每个样本统计出现这三个特征的频率。
1import os
2import pandas as pd
3import numpy as np
4import csv
5
6label_file = r"E:\8_19\testX_csv"
7
8train_mean = r"E:\8_19\disperse\discrete56.csv"
9
10with open(train_mean, "a", newline = '', encoding = "utf-8") as f:
11 train_mean = csv.writer(f)
12
13 for x in range(1, 451):
14 fan_file = os.path.join(label_file, str(x) + ".csv")
15# print("程序运行进度为", x/451) #用该语句查看工作进度状态
16
17 with open(fan_file, encoding='utf-8') as f:
18 feature_read = pd.read_csv(f, header = None)
19
20 num1 = 0
21 num2 = 0
22 num3 = 0
23
24 a = []
25
26 for x in range(len(feature_read)):
27 if feature_read[55][x] == 0:
28 num1 = num1+1
29 if feature_read[55][x] == 1:
30 num2 = num2+1
31 if feature_read[55][x] == 2:
32 num3 = num3+1
33
34 num1 = num1/len(feature_read)
35 num2 = num2/len(feature_read)
36 num3 = num3/len(feature_read)
37
38 a.append(num1)
39 a.append(num2)
40 a.append(num3)
41
42 train_mean.writerow(a)
算法
我们最后主要用的算法是Xgboost,期间也尝试过LightGBM,因为算力不够的原因,没有办法尝试一些算法(包括杨工说的SVM以及深度学习的想法),最后主要用Xgboost进行调参,直接一起调参的话算力不够,我们是单个调参以及两两调参组合的形式进行参数调整。
1from xgboost import XGBClassifier
2import xgboost as xgb
3
4import pandas as pd
5import numpy as np
6
7from sklearn.model_selection import GridSearchCV
8from sklearn.model_selection import StratifiedKFold
9
10from sklearn.metrics import log_loss
11from sklearn.preprocessing import MinMaxScaler
12
13
14#数据导入、检查空缺值
15data = pd.read_csv(r'D:\next\8_19\train_data.csv',encoding = "gbk")
16label = pd.read_csv(r"D:\next\8_19\train_label.csv")
17test = pd.read_csv(r"D:\next\8_19\test_data.csv", encoding = "gbk")
18train = data.iloc[:,:-1]
19label = label.iloc[:,-1]
20
21X_train = train
22y_train = label
23
24#数据标准化
25scaler = MinMaxScaler()
26train = scaler.fit(train).transform(train)
27test = scaler.fit(test).transform(test)
28
29#交叉验证
30kfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=3)
31
32param_test1 = {
33 'max_depth':list(range(3,10,1)),
34 'min_child_weight':list(range(1,6,1))
35}
36gsearch1 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=400, max_depth=5,
37 min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8,
38 objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27),
39 param_grid = param_test1, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
40gsearch1.fit(X_train,y_train)
41gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_调完这个参数之后,把最好的输出结果拿出来放在下一个参数调优里进行调整:
1aram_test1 = {
2 'learning_rate':[i/100.0 for i in range(6,14,2)]
3}
4gsearch1 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=400, max_depth=6,
5 min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8,
6 objective= 'binary:logistic', nthread=6, scale_pos_weight=1, seed=27),
7 param_grid = param_test1, scoring='roc_auc',n_jobs=-1,iid=False, cv=5)
8gsearch1.fit(X_train,y_train)
9gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
10
11param_test1 = {
12 'subsample':[0.8, 0.9]
13}
14gsearch1 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=310, max_depth=6,
15 min_child_weight=1, gamma=0, subsample=0.9, colsample_bytree=0.8,
16 objective= 'binary:logistic', nthread=6, scale_pos_weight=1, seed=27),
17 param_grid = param_test1, scoring='roc_auc',n_jobs=-1,iid=False, cv=5)
18gsearch1.fit(X_train,y_train)
19gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_还可以调整好几个参数,最后结果输出:
1import xgboost as xgb
2dtrain=xgb.DMatrix(X_train ,label=y_train)
3dtest=xgb.DMatrix(test)
4
5params={
6 'objective': 'binary:logistic',
7 'max_depth':6,
8 'subsample':0.8,
9 'colsample_bytree':0.8,
10 'min_child_weight':1,
11 'seed':27,
12 'nthread':6,
13 'learning_rate':0.1,
14 'n_estimators':292,
15 'gamma':0,
16 'scale_pos_weight':1}
17
18watchlist = [(dtrain,'train')]
19
20bst=xgb.train(params,dtrain,num_boost_round=100,evals=watchlist)
21
22ypred=bst.predict(dtest)
23
24import csv
25
26test_label = r"D:\next\8_20\test_label_new.csv"
27with open(test_label, "a", newline = '', encoding = "utf-8") as f:
28 test_label = csv.writer(f)
29
30 for x in range(len(ypred)):
31 a = []
32 if ypred[x] < 0.5:
33 a.append(0)
34 test_label.writerow(a)
35 else:
36 a.append(1)
37 test_label.writerow(a)即使是单个调参和两两调参,对于我们而言,计算速度还是太慢,我们为此也尝试了Hyperopt方法。通俗的说,我们用的是掷骰子方法,也就是在一个划定参数区域内随机地掷骰子,哪个参数被掷成几,我们就用这个数来训练模型。最后返回一个掷的最好的参数结果。这个方法有很大的局限性,一是结果的随机性,二是很容易局部收敛。但是,如果用来粗糙地验证一个特征构造的好坏,也不失为一个好方法。
1# -*- coding: utf-8 -*-
2"""
3Created on Fri May 18 14:09:06 2018
4
6"""
7
8import numpy as np
9import pandas as pd
10from sklearn.preprocessing import MinMaxScaler
11import xgboost as xgb
12from random import shuffle
13from xgboost.sklearn import XGBClassifier
14from sklearn.cross_validation import cross_val_score
15import pickle
16import time
17from hyperopt import fmin, tpe, hp,space_eval,rand,Trials,partial,STATUS_OK
18import random
19
20data = pd.read_csv(r'D:\next\select_data\new_feature.csv', encoding = "gbk").values
21label = pd.read_csv(r'D:\next\select_data\new_label.csv').values
22labels = label.reshape((1,-1))
23label = labels.tolist()[0]
24
25minmaxscaler = MinMaxScaler()
26attrs = minmaxscaler.fit_transform(data)
27
28index = range(0,len(label))
29random.shuffle(label)
30trainIndex = index[:int(len(label)*0.7)]
31print (len(trainIndex))
32testIndex = index[int(len(label)*0.7):]
33print (len(testIndex))
34attr_train = attrs[trainIndex,:]
35print (attr_train.shape)
36attr_test = attrs[testIndex,:]
37print (attr_test.shape)
38label_train = labels[:,trainIndex].tolist()[0]
39print (len(label_train))
40label_test = labels[:,testIndex].tolist()[0]
41print (len(label_test))
42print (np.mat(label_train).reshape((-1,1)).shape)
43
44
45def GBM(argsDict):
46 max_depth = argsDict["max_depth"] + 5
47# n_estimators = argsDict['n_estimators'] * 5 + 50
48 n_estimators = 627
49 learning_rate = argsDict["learning_rate"] * 0.02 + 0.05
50 subsample = argsDict["subsample"] * 0.1 + 0.7
51 min_child_weight = argsDict["min_child_weight"]+1
52
53 print ("max_depth:" + str(max_depth))
54 print ("n_estimator:" + str(n_estimators))
55 print ("learning_rate:" + str(learning_rate))
56 print ("subsample:" + str(subsample))
57 print ("min_child_weight:" + str(min_child_weight))
58
59 global attr_train,label_train
60
61 gbm = xgb.XGBClassifier(nthread=6, #进程数
62 max_depth=max_depth, #最大深度
63 n_estimators=n_estimators, #树的数量
64 learning_rate=learning_rate, #学习率
65 subsample=subsample, #采样数
66 min_child_weight=min_child_weight, #孩子数
67
68 max_delta_step = 50, #50步不降则停止
69 objective="binary:logistic")
70
71 metric = cross_val_score(gbm,attr_train,label_train,cv=3, scoring="f1", n_jobs = -1).mean()
72 print (metric)
73 return -metric
74
75space = {"max_depth":hp.randint("max_depth",15),
76 "n_estimators":hp.quniform("n_estimators",100,1000,1), #[0,1,2,3,4,5] -> [50,]
77 #"learning_rate":hp.quniform("learning_rate",0.01,0.2,0.01), #[0,1,2,3,4,5] -> 0.05,0.06
78 #"subsample":hp.quniform("subsample",0.5,1,0.1),#[0,1,2,3] -> [0.7,0.8,0.9,1.0]
79 #"min_child_weight":hp.quniform("min_child_weight",1,6,1), #
80
81 #"max_depth":hp.randint("max_depth",15),
82 # "n_estimators":hp.randint("n_estimators",10), #[0,1,2,3,4,5] -> [50,]
83 "learning_rate":hp.randint("learning_rate",6), #[0,1,2,3,4,5] -> 0.05,0.06
84 "subsample":hp.randint("subsample",3),#[0,1,2,3] -> [0.7,0.8,0.9,1.0]
85 "min_child_weight":hp.randint("min_child_weight",2)
86
87 }
88algo = partial(tpe.suggest,n_startup_jobs=1)
89best = fmin(GBM,space,algo=algo,max_evals=50) #max_evals表示想要训练的最大模型数量,越大越容易找到最优解
90
91print (best)
92print (GBM(best))

最终结果
我们首先把数据进行分类处理。对于那些空缺值的数据,我们直接给label为1(表示异常),对于空缺值的处理只能摸奖。在分析训练样本的分布时,我们还发现有一些阈值的特征,就是那些特征大于某些值或者小于某些值之后故障风机要明显比正常风机多出很多,这样,我们可以用阈值判断直接给label,剩下不能判断的再用算法进行判断。然后最后时间比较紧,阈值部分的没有做,除去了空缺值之后,其他的全部用算法进行判断。
杨工告诉我们,应该做分析的时候分析“轮毂转速”大于3的数据,因为风机工作才可以检测出来异常,如果风机不工作是很难判断的。但是因为时间比较紧,对于训练集我们就没有进行这样的操作,于是测试集也没有进行这样的划分。全部都一起塞进算法里了。
总结一下。我们对于特征进行交叉和重要性排序,综合考虑杨工说的重要特征和算法反馈的重要特征排序,最后生成一百多个特征的特征文件用来训练(训练样本是经过数据清洗过后的样本)。
测试集分为两部分,一部分是空缺值,直接标1,另一部分放算法里出结果。
总结
首先最大的一个坑是开始没有做数据清洗的工作,后来发现了之后从新来了一遍。再后来是杨工和我们说应该分析工作风机,拿工作风机来进行训练。如果这样做的话又要推倒从来,当时时间已经十分紧张了,心有余而力不足。对于比赛或者说数据分析工作来说,数据的理解是第一位的。否则很可能会做不少无用功。有的时候,受限于专业背景,我们很难充分地理解数据和业务场景,这时候应该向专业人士进行请教,把这些工作都做好之后再进行数据分析要好很多。
其次,提高自己地代码和算法的能力。既要懂算法又要能撸出一手好代码,这样才能提高效率。我写代码写得太慢,十分制约我的想法实现速度。算法不太懂,也不能很好地参与到算法讨论环节。
另外,版本控制十分重要。我们每天都在实现新的想法,文件很多也很乱。经常出现刚发一个文件,过一段时间就找不到那个文件或者忘了有没有发那个文件地情况。
声明:本文为公众号 经管人学数据分析 投稿,版权归对方所有。
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。
————— 推荐阅读 —————