本文介绍的是 CVPR 2020
Oral
论文《Cross-Batch Memory for Embedding Learning》,作者来自码隆科技。本篇论文解读首发于“码隆播报”公众号。
编辑 | 丛 末
![]()
论文地址:https://arxiv.org/abs/1912.06798
开源地址:https://github.com/MalongTech/research-xbm
本篇论文提出了 XBM 方法,能够用极小的代价,提供巨量的样本对,为 pair-based 的深度度量学习方法取得巨大的效果提升。这种提升难例挖掘效果的方式突破了过去两个传统思路:加权和聚类,并且效果也更加简单、直接,很好地解决了深度度量学习的痛点。XBM 在多个国际通用的图像搜索标准数据库上(比如 SOP、In-Shop 和 VehicleID 等),取得了目前最好的结果。
难例挖掘是深度度量学习领域中的核心问题,最近有颇多研究都通过改进采样或者加权方案来解决这一难题,目前主要两种思路:
第一种思路是在 mini-batch 内下功夫,对于 mini-batch 内的样本对,从各种角度去衡量其难度,然后给予难样本对更高权重,比如 N-pairs、Lifted Struture Loss、MS Loss 使用的就是此种方案。
第二种思路是在 mini-batch 的生成做文章,比如 HTL、Divide and Conquer,他们的做法虽然看上去各有不同,但是整体思路有异曲同工之处。大致思路都是对整个数据集进行聚类,每次生成 mini-batch 不是从整个数据集去采样,而是从一个子集,或者说一个聚类小簇中去采样。这样一来,由于采样范围本身更加集中,生成的 mini-batch 中难例的比例自然也会更大,某种程度上也能解决问题。
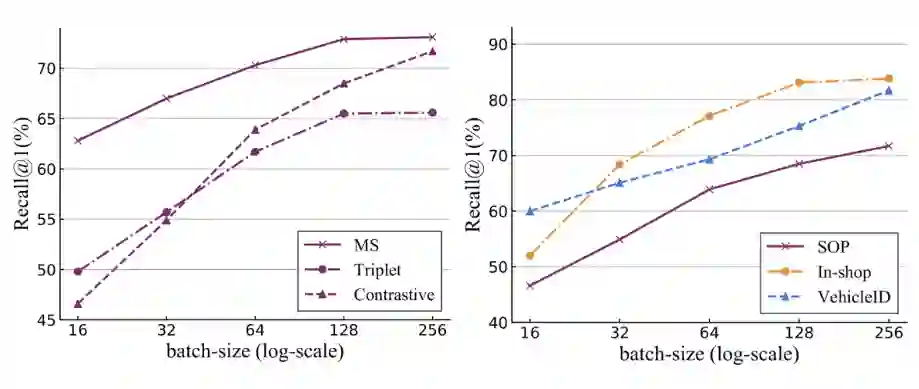
然而,无论是第一种方法的额外注重难样本,还是第二种方法的小范围采样,他们的难例的挖掘能力其实依然有一个天花板——那就是 mini-batch 的大小。这个 mini-batch 的大小决定了在模型中单次迭代更新中,可以利用的样本对的总量。因此,即使是很精细的采样加权方法,在 mini-batch 大小有限的情况下,也很难有顶级的表现。我们在三个标准图像检索数据库上进行了实验,基于三种标准的 pair-based 方法,我们发现随着 mini-batch 变大,效果(Recall@1)大幅提升。实验结果如下图:
可以看出,随着 mini-batch 的增大,效果有显著提升。但是,在实际工业应用中 mini-batch 越大,训练所需要的 GPU 或 TPU 就越多,即使计算资源有充分保证,在多机多卡的训练过程中,如何在工程上保证通信的效率也是一个有挑战的问题。
由此,我们希望另辟蹊径,得以在 mini-batch 有限的情况下,也能获得充足的难例样本对。首先,必须突破深度度量学习一直以来的一个思维局限——仅在对当前 mini-batch 里的样本对两两比较,形成样本对。以此我们引入了 XBM(Cross-batch Memory)这一方法来突破局限,跨越时空进行难例挖掘,把过去的 mini-batch 的样本提取的特征也拿过来与当前 mini-batch 作比较,构建样本对。
我们将样本特征随着模型训练的偏移量,称之为特征偏移(Feature Drift)。从上图我们发现,在训练的一开始,模型还没有稳定,特征剧烈变化,每过 100 次迭代,特征偏移大约 0.7 以上。但是,随着训练的进行,模型逐步稳定,特征的偏移也变小。我们称这个现象为慢偏移(Slow Drift),这是我们可以利用的一点。
我们发现,虽然在训练的前 3K iterations,mini-batch 过去的提取特征与当前模型偏差很大,但是,随着训练时间的延长,过去的迭代里所提取过的特征,逐渐展示为当前模型的一个有效近似。我们要做的不过是把这些特征给存下来,每个特征不过是 128 个 float 的数组,即便我们存下了过去 100 个 mini-batch 的特征,不过是6400个(假设 batch size = 64)float 数组,所需要不过是几十 MB 的显存。而它带来的好处是显而易见的,我们能够组成的样本对的个数是仅仅利用当前 mini-batch 的一百倍。即便这些特征不能高精准地反映当前模型的信息,但是只要特征偏移在合理的范围内,这种数量上带来的好处,可以完全补足这种误差带来的副作用。
我们的 XBM 从结构上非常简单清晰。我们先训练一个 epoch 左右,等待特征偏移变小。然后,我们使用 XBM:一个特征队列去记忆过去 mini-batch 的特征,每次迭代都会把当前 mini-batch 提取出来的新鲜特征加入队列,并把最旧的特征踢出队列,从而保证 XBM 里的特征尽量是最新的。每次去构建样本队列的时候,我们将当前 mini-batch 和 XBM 里的所有特征都进行配对比较,从而形成了巨量的样本对。如果说 XBM 存储了过去 100 个 mini-batch,那么其所产生的样本对就是基于 mini-batch 方法的 100 倍。
不难发现,XBM 其实直接和过去基于样本对的方法结合,只需要把原来的 mini-batch 内的样本对换成当前 mini-batch 和 XBM 的特征构成的样本对就可以了。所以,我们通过 XBM 这种存储特征的机制,能够让不同时序的 mini-batch 的特征成功配对。
首先,我们在三个常用的检索数据集,和三个基于样本对的深度学习的方法上,使用 XBM 进行测试,同时控制其他的设置全部不变。我们发现,XBM 带来的效果很明显。尤其是在最基本的对比损失(Contrastive Loss)上,可以看到,本来这个方法只利用 mini-batch 内的样本时,其效果并不显著,但是 XBM 带来了显著的效果提升。在三个数据集, Recall@1 都至少提升 10 个点,尤其是 VehicleID 数据集的最大(Large)测试集,效果提升了 22 个点,从 70.0 到 92.5。
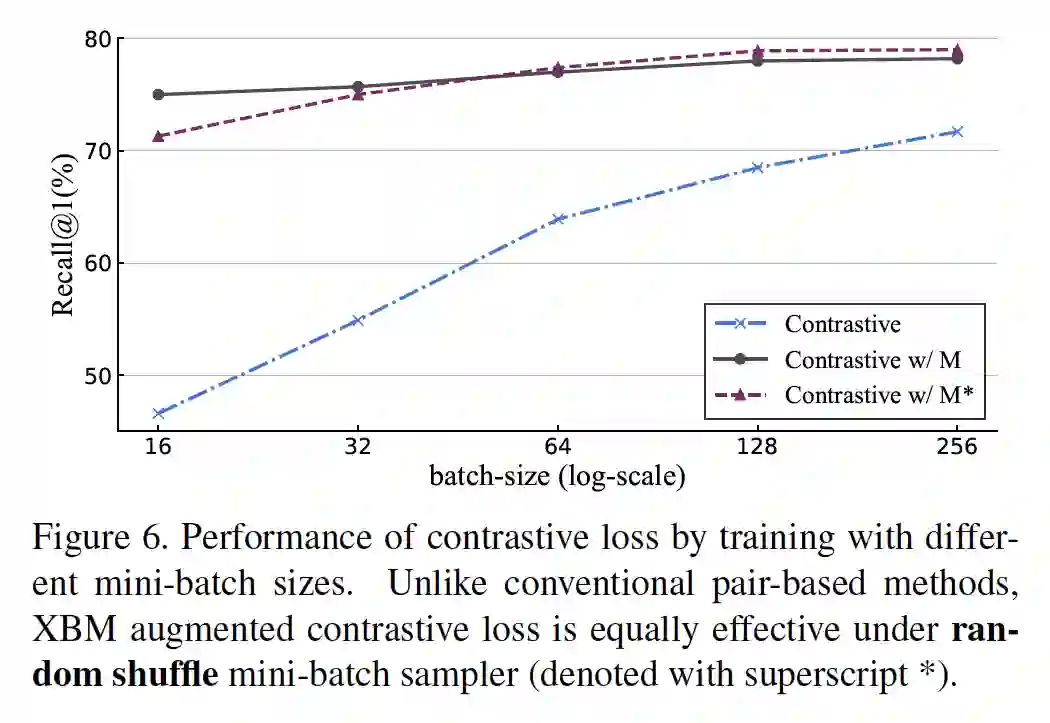
关于 mini-batch 的大小对结果的影响, 从上图可发现三点:
1、无论是否使用 XBM,mini-batch 越大,效果越好;
2、XBM 方法即便是使用很小的 batch (16), 也比没有 XBM 使用大的 batch (256) 效果好;
3、 由于 XBM 本身可以提供正样本对,所以可以不一定要用 PK sampler 来生成 mini-batch,而是可以直接使用原始的 shuffle sampler,效果相似。
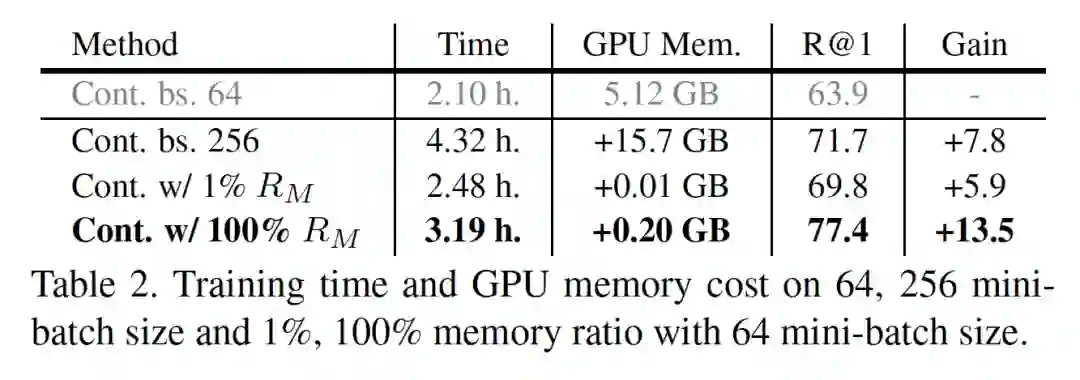
下图我们展示了在 SOP 上训练 XBM 时的计算资源消耗,即便把整个训练集(50K+)的特征都加载到 XBM,不过需要 0.2GB 的显存;而如果是使用增大 batch 的方法,会额外需要 15GB 显存,是 XBM 的 80 倍,但是效果的提升比 XBM 差很多。毕竟 XBM 仅仅需要存特征,特征也是直过去的 mini-batch 的前向计算的结果,计算资源的需求很小。
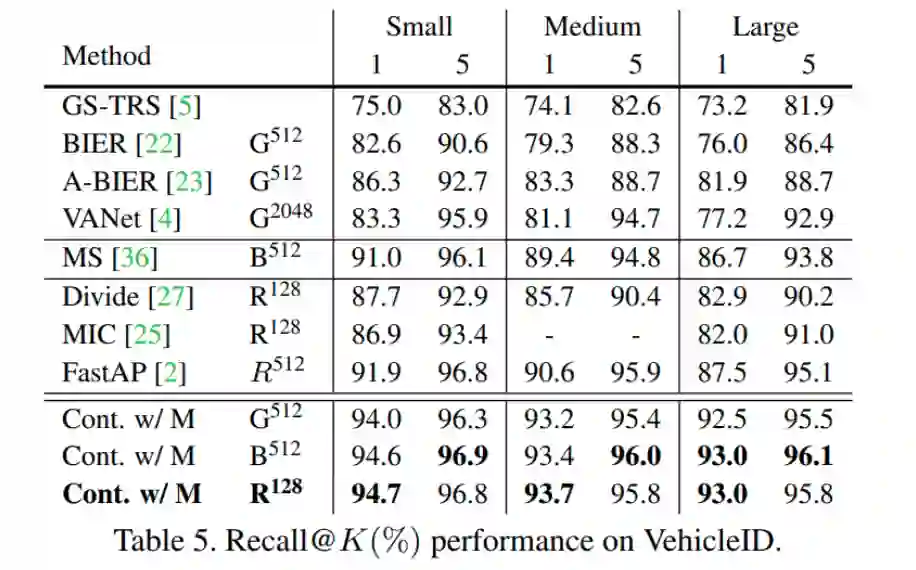
与最近的深度度量学习方法对比,我们在四个检索数据库上效果均大幅提升,这里仅列出 VehicleID 的效果,其他数据集的效果见原论文。
简单来说,不同于部分文章中使用更好的网络结构,更大的输出维度,或者更大的 mini-batch 来提升效果,强行 SOTA。我们列出 XBM 在 64 的 mini-batch 在不同的主干网络下及各种维度下的效果,其效果一直是最好的。
第一,本文提出的 XBM 方法能够记住过去的特征,使得模型的训练不再仅仅依靠当前 mini-batch 的样本,而是可以跨越时空进行样本配对。从而用极小的代价,提供了巨量的样本对,为 pair-based 的深度度量学习方法取得了巨大的效果提升。这种提升难例挖掘效果的方式,也是突破了过去两个传统思路:加权和聚类,并且效果也更加简单、直接,很好地解决了深度度量学习的痛点。
第二,其实 Memory 机制并不是本文原创,但是用 Memory 来做难例挖掘是一个全新的尝试。同样在 CVPR 2020 获得 Oral,也是由 Kaiming He 作为一作的 MoCo 也是这种思路。本文的方法其实可以认为是 MoCo 在 m=0 的特例,Kaiming 通过动量更新 key encoder,可以直接控制住特征偏移。作者认为,这种方法还会在很多任务带来提升,不局限于 Kaiming 的自监督表示学习,以及此前我们一直关注研究的度量学习(或者说监督表示学习)。
第三,在本文中,虽然 XBM 在所有的 pair-based 的方法都有提升,但是明显在对比损失(Contrastive Loss)上提升最大,具体原因待考。另外,我们也把在无监督表示上表现很好的 infoNCE 方法用到了深度度量学习,但效果并不显著。作者认为这两个问题的答案是同一个,且有值得深究的价值,希望在后续研究中进行进一步跟进探索。
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京/深圳
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:cenfeng@leiphone.com
点击"阅读原文",直达“CVPR 交流小组”了解更多会议信息。