统一视角理解目标检测算法:最新进展分析与总结

极市导读
本文是一篇目标检测算法的进展总结与分享,作者用更为清晰的体系框架,去帮助大家更好的理解现有的目标检测算法机器的发展。通过对目标检测问题的建模方式进行更为细致的探讨与分析,引出Dense or Multi-stage refine是提高检测算法性能的关键,合理折中效果更佳的观点。>>12月10日(周四)极市直播|汤凯华:利用因果分析解决通用的长尾分布问题
前言
multi-region classification & regression

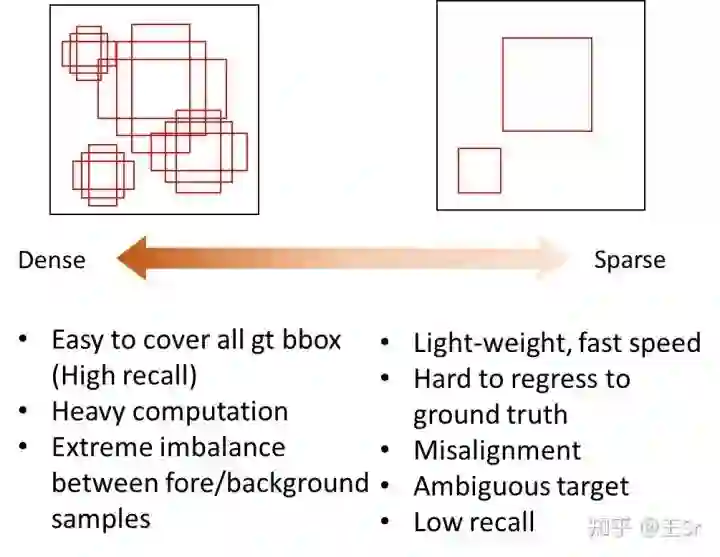
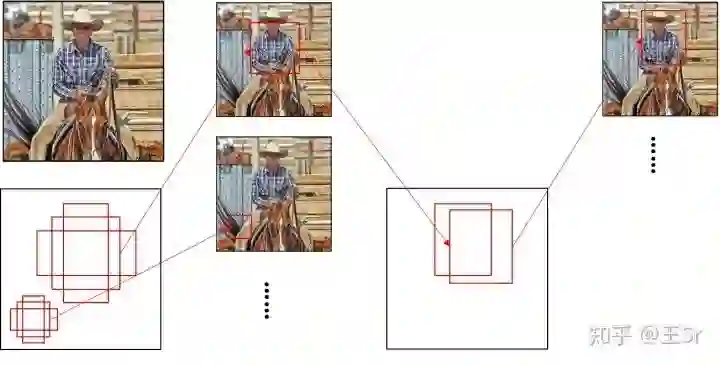
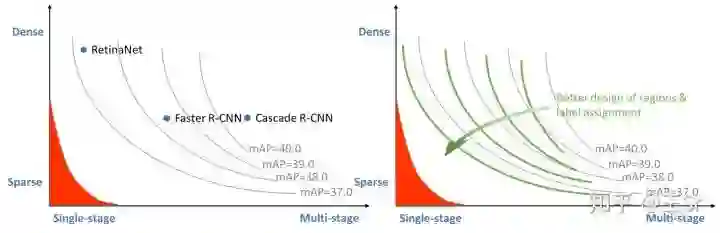
总结
推荐阅读




登录查看更多
相关内容

Arxiv
5+阅读 · 2019年1月10日


相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2019年1月10日