回顾AAAI|如何参加国际顶级人工智能大会?

一场美国人工智能年会
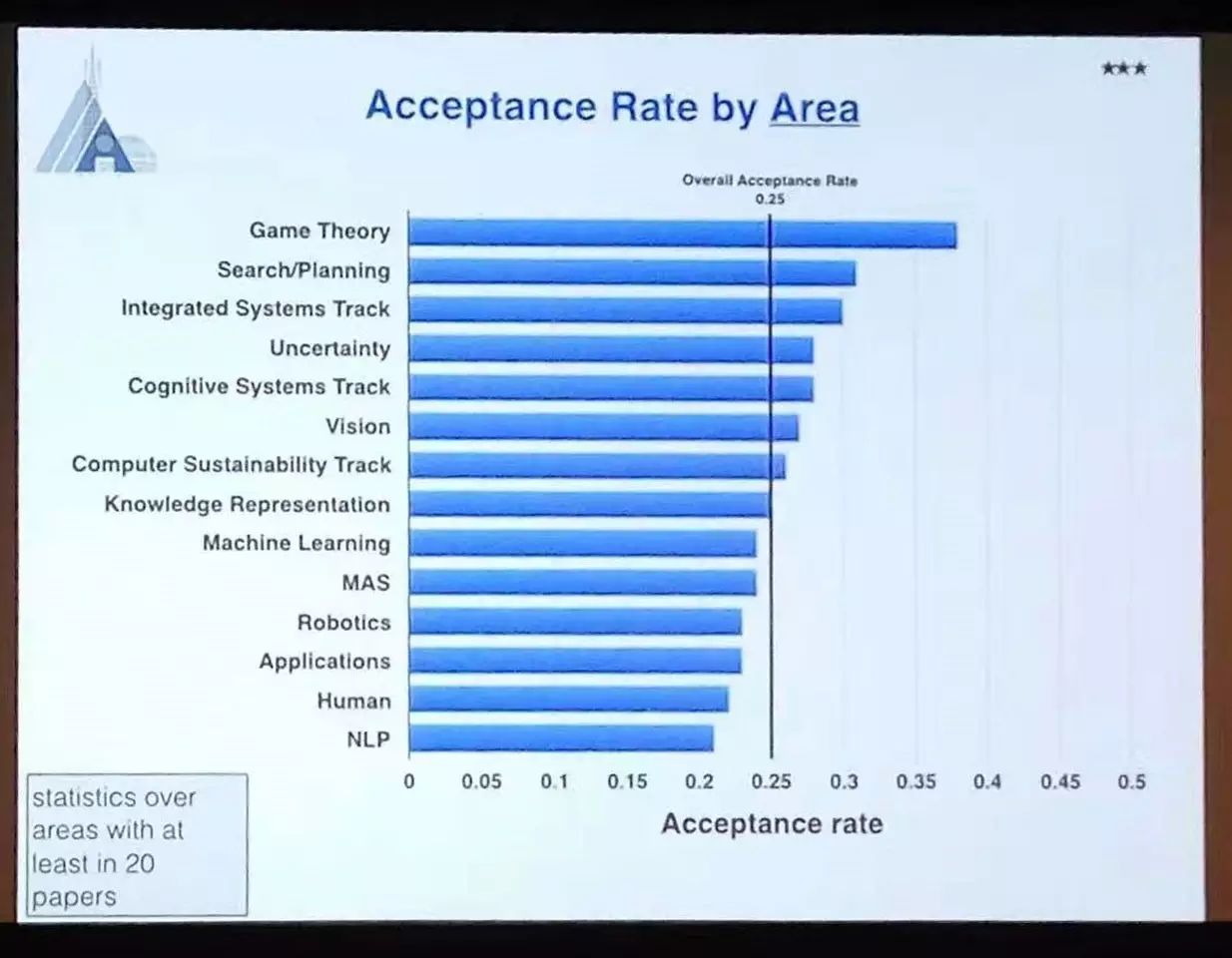
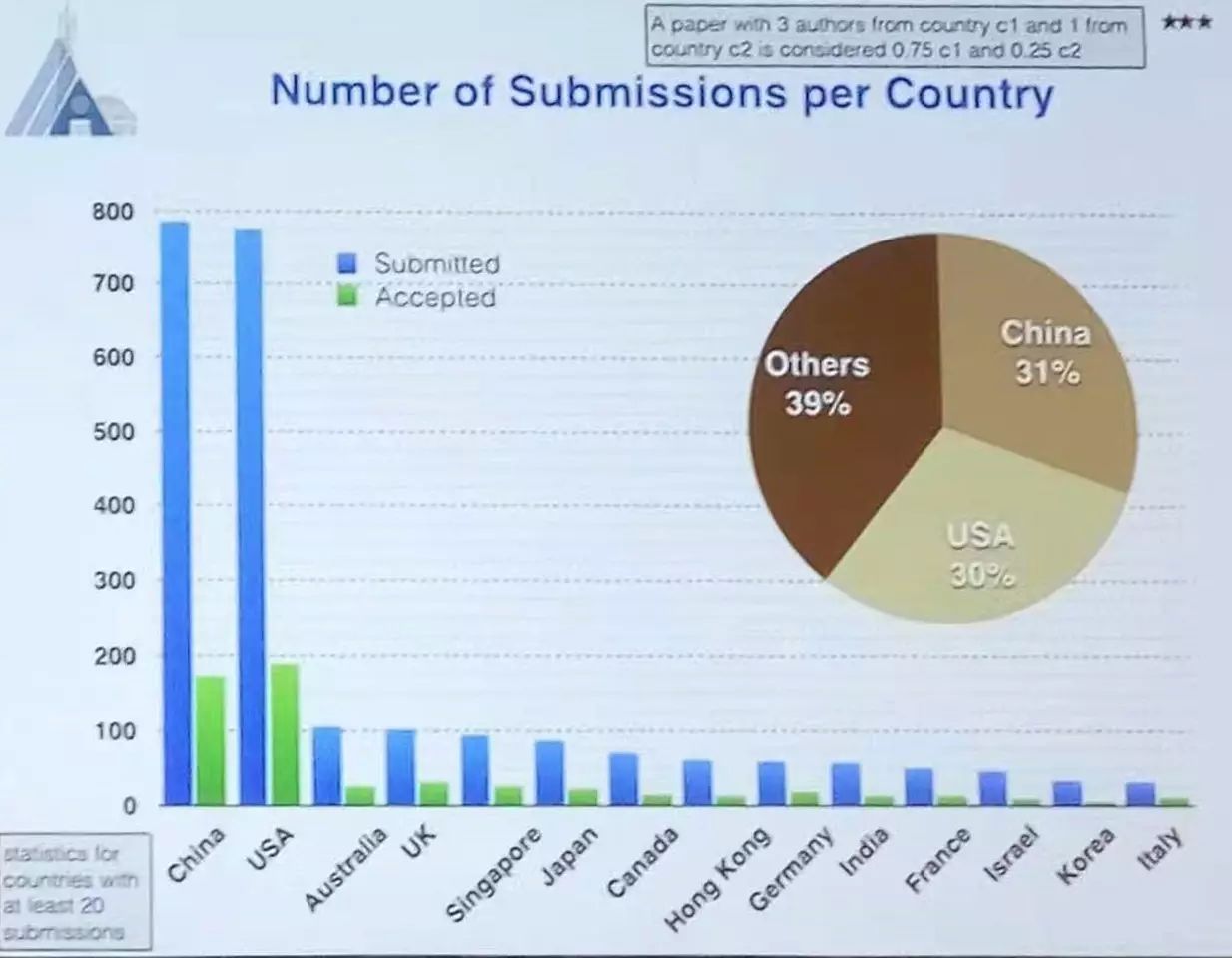
美国人工智能年会(AAAI Conference on Artificial Intelligence),简称AAAI,是人工智能领域的顶级国际会议。 该会议固定在每年的2月份举行,由AAAI协会主办。今年第三十一届AAAI共计收到2700余篇投稿,最终录取580篇左右,录取率为25%,录取论文涉及博弈论、搜索、视觉、知识表示、机器学习、机器人学、自然语言处理等多个方向。
本次AAAI大会于2月4日至9日在美国旧金山举行。 旧金山(San Francisco)位于美国太平洋沿岸的湾区,是北加州的商业与文化发展中心,毗邻硅谷,被各大科技巨头公司以及创业公司环绕。
大会主要包括四大部分,其中包括为期一天多的辅导(tutorials),五天的大会会议(technical program)和穿插其中的邀请演讲(invited talks)。大会第一天的教程总共有22个,每个教程时长为4小时。其中,微软亚洲研究院的陈薇博士做了题为“分布式机器学习的最新进展”的教程,获得了参会者的关注和响应。
本次大会最令我感到兴奋的环节是以“AI in practice”为题的系列讲座。该讲座邀请了7位世界科技巨头公司的人工智能负责人,畅谈各个公司最新的人工智能进展以及各自发力的方向。其中,谷歌的 Vincent Vanhouke介绍了他认为的当下人工智能的最大挑战之一,是如何将人工智能引入物理世界,让人工智能为人类创造更加舒适的以人为中心的生活环境,而完成这一目标的关键,是科研人员跳出目前相对舒适的大规模有监督学习的设定,去解决数据稀缺和无监督技能转移等问题。 亚马逊的Alex Smola则介绍了构建深度学习系统所面临的挑战,以及如何使用MxNet构建可扩展的深度学习模型。 百度的王海峰博士系统地介绍了百度在自然语言处理领域以人工智能为目标所做的各项努力。
夺目的最佳会议论文
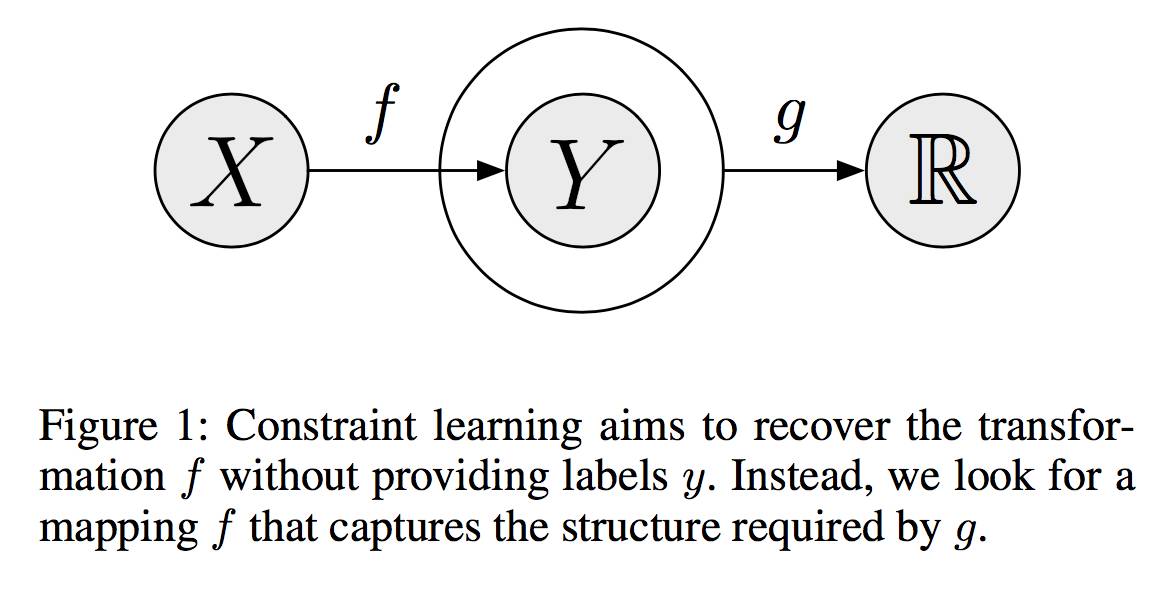
本次AAAI的杰出论文奖授予了斯坦福大学的Russell Stewart和Stefano Ermon的“Label-Free Supervision of Neural Networks with Physics and Domain Knowledge”。本文试图将神经网络的学习过程,从样例-标签对的结构中解脱出来,利用物理或其他先验知识实现监督学习。具体做法是设计一个约束函数g,把神经网络的输出f(x),映射到符合物理知识或者其他先验规则的空间中。该方法在包括跟踪一个自由落体、跟踪一个行人的位置、根据因果关系检测目标这三个案例上,都取得了与有标签学习相当的准确率。
与AAAI大会的亲密接触
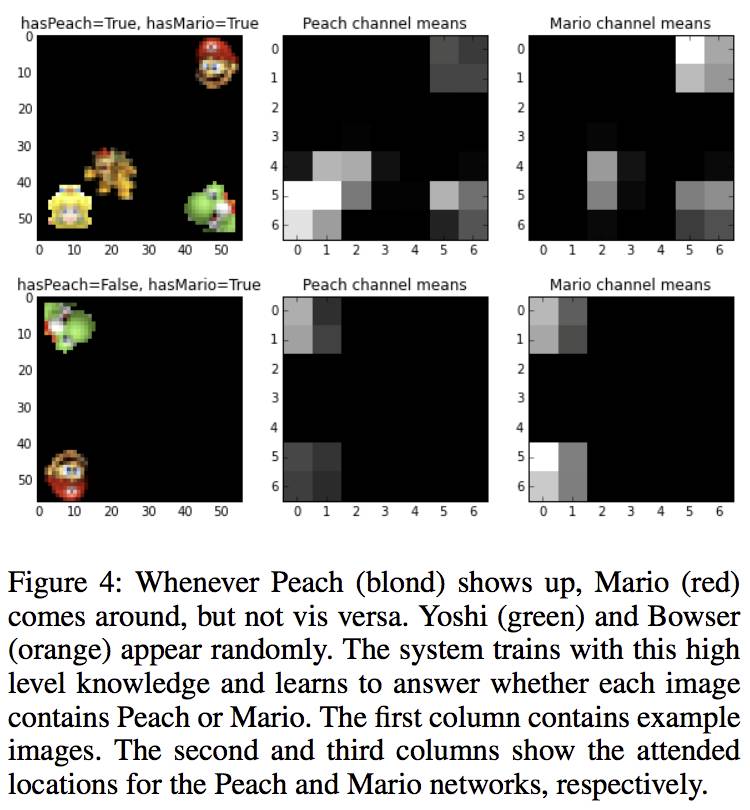
本次大会,我在武威研究员指导下的工作“Topic aware Neural Response Generation”被收录。我们的这项工作主要用于聊天机器人的自动应答生成。传统的应答生成模型Seq2Seq,在生成应答的时候存在一个问题,即经常生成通用性的回答,如“哦我知道了”,“我也是”。这些通用性的回答虽然可以回复多种多样的消息(message),但是由于它们缺乏多样性和信息性,通常难以取悦用户。我们为了解决这个问题,提出将message的主题相关的信息从额外的数据中提取出来,将这些丰富的主题相关的信息引入生成过程,帮助生成多样的有信息量的应答。
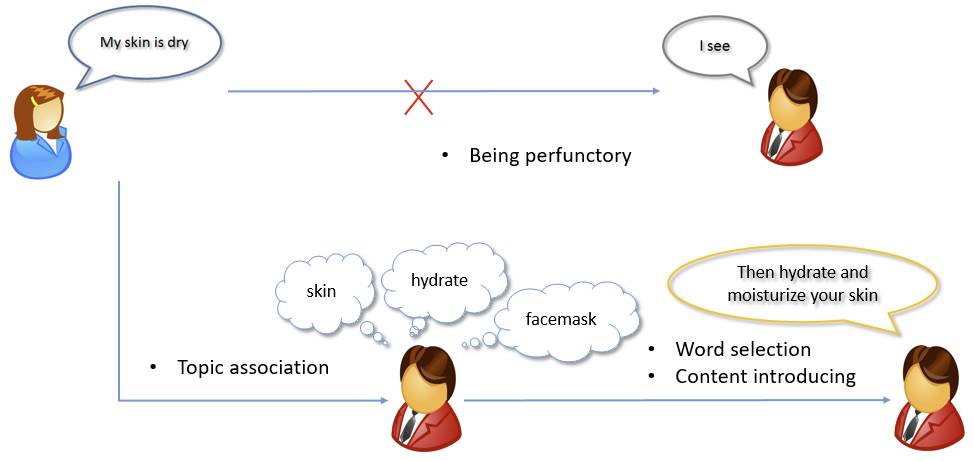
具体来说,我们预先利用大量网络数据训练一个Twitter LDA主题模型,并且让该主题模型为每个message 赋予一个话题,我们用该话题下受欢迎程度最高的n的词组成该message的话题词列表。在生成模型中,我们一方面在输入端设计一个话题注意度,自动选择比较重要的话题词来引入新信息帮助生成;另一方面,在输出端,我们为每个话题词增加一个额外的概率,使得它们在生成应答过程中更容易被选择,从而增加生成的应答的信息量和丰富程度。
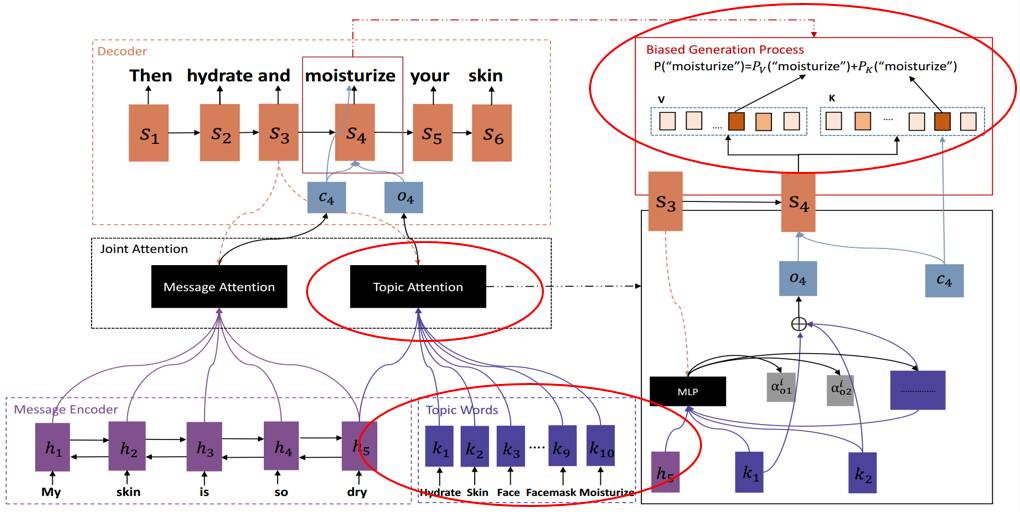
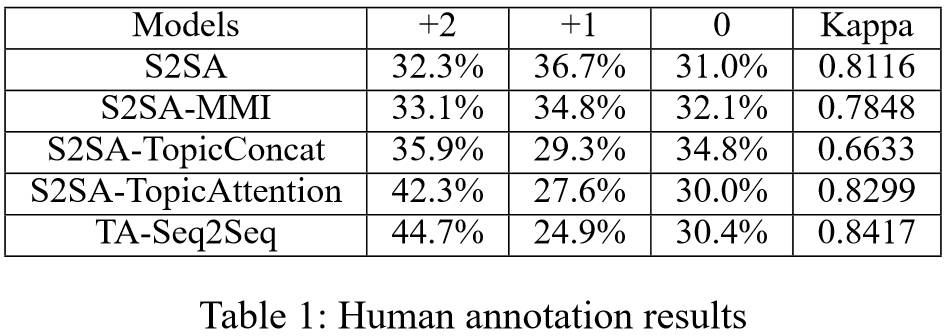
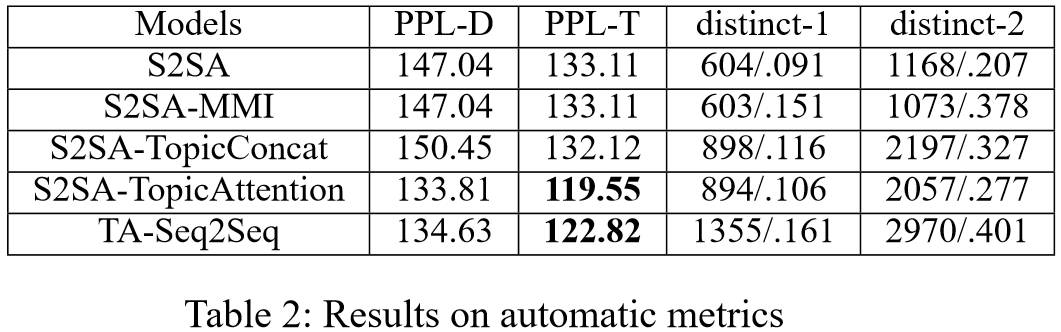
我们采取人工标注,随机和生成应答中的相异单词数来评判模型性能。实验结果显示我们的模型TA-Seq2Seq在这三个指标上均很大程度地超过了基本的方法,并且在具体案例的应用中,生成了很多令人兴奋的应答。
我从博士二年级开始在周明老师的自然语言计算组实习。在这里我迈出了我的科研第一步,在老师和同学的帮助下发表了人生中第一篇论文;并且在后续的科研工作中,也极大的受益于老师的指导,组里科研氛围的熏陶,和小伙伴们贴心的帮助和支持。参与AAAI这样的大会对我而言是一次成长很多的体验,感谢组里的导师和同学们,我也期待跟大家一起努力,做出更加有影响力的工作。


作者简介

我叫星辰,是微软亚洲研究院自然语言计算组的实习生,就读于南开大学攻读博士学位。我的研究兴趣是对话生成,自然语言处理,深度学习。
你也许还想看:
感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。







