科大讯飞李伟:人机交互如何选择合适的「耳朵」

AI 科技评论按:人工智能当前正处于爆发阶段,语音交互作为人工智能的重要组成部分正在各行业全面的落地,在人机进行语音交互的过程中,机器需要通过耳朵实现听觉的作用。
在雷锋网旗下学术频道 AI 科技评论的数据库项目「AI 影响因子」中,凭借讯飞病灶分割比赛优胜团队专访、讯飞与哈工大联合实验室刷新 SQuAD 成绩的突出表现、前 MSRA 副院长李世鹏任讯飞 AI 研究院联席院长,排在「AI 影响因子」前列。
近期,在雷锋网研习社公开课上,科大讯飞产品经理李伟为大家科普了当前正热的智能音箱背后的功臣——麦克风阵列,并具体讲解了双麦克风阵列和该方案在各领域的广泛应用。李伟也希望借此解决大家在语音交互 AI 前端学习上的一些疑问。视频回放地址:http://www.mooc.ai/open/course/498
李伟,科大讯飞产品经理,负责麦克风阵列和智能家电领域的语音交互解决方案,曾就职于惠而浦(中国)股份有限公司先后担任软件工程师和智能家电产品经理,重庆邮电大学生物信息学学士,重庆邮电大学软件工程硕士。

分享主题:人机交互如何选择合适的「耳朵」——浅谈双麦克风阵列及行业应用
分享提纲
人机交互的「耳朵」——麦克风阵列简介
如何选择麦克风阵列——选择麦克风阵列的四要素
双麦克风阵列简介和行业应用介绍

首先来介绍什么是麦克风阵列,提到语音交互,有一个始终绕不开的话题:智能音箱。众所周知,亚马逊推出的 Echo 一下子带火了整个智能音箱市场,语音交互也开始获得人们的关注,越来越多的消费者开始购买语音交互智能设备。但大家在使用语音交互设备(如智能音箱)时,往往发现不同产品的语音交互效果差别很大,这主要由于智能音箱在听觉设计上采用了不同的麦克风阵列方案造成的,比如最新推出的天猫精灵方糖和叮咚 Mini2。

方糖使用双麦克风阵列方案(左),叮咚 Mini2(右)使用 6 麦克风阵列方案
什么是麦克风阵列?

工业级麦克风阵列,一般是由数十和上千个麦克风按照一定的规则排列组合,主要应用于工业,军工等领域。
消费级麦克风阵列,是对工业级麦克风阵列的大大简化,由于主要考虑成本因素,所以通常消费级麦克风阵列麦克风数量不超过十个。
近些年,随着语音交互方案的成熟,消费级的麦克风阵列开始逐渐普及,本次分享主要针对消费级麦克风阵列。
麦克风阵列(以下均指消费级)的作用
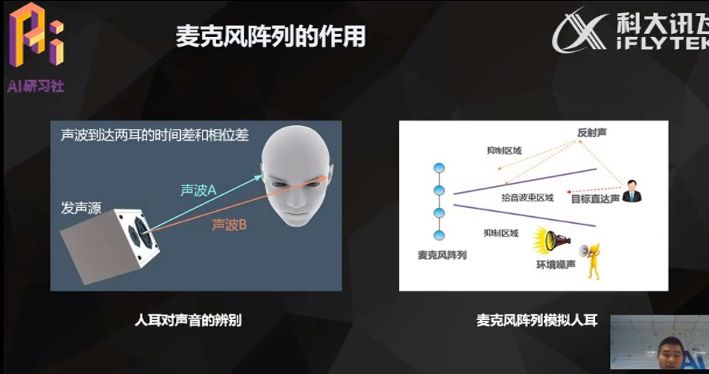
麦克风阵列主要模拟人耳的听觉作用,人的耳朵不仅可以听到声音,还具备分辨声源类型和方向的能力。这样,我们就可以选择听到喜欢的声音,如在办公室,当我和同事交流的时候,会忽略周围其他的声音。其实麦克风阵列就是机器的耳朵,不仅采集音频信号,还为了更好的声源辨别和噪音过滤,从而保证人机交互的效果。
由于人耳具有十分复杂的结构,麦克风阵列(尤其是消费级麦克风阵列)很难达到人耳的辨别和调整能力。目前,麦克风阵列主要具备四大功能。
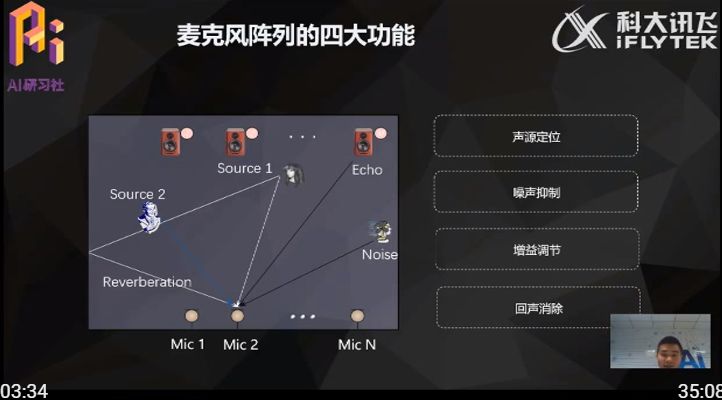
声源定位:准确来说,麦克风实现的是声源侧向,而不是精准的定位,它的主要作用就是侦测到声源的方位以便后续的波束形成。通常声源定位会在语音唤醒阶段实现。
噪声抑制:这里的噪声一般指环境噪音,比如空调吹风的声音,窗外汽车行驶的声音等等,这类噪音通常不会掩盖正常的语音,只是影响了语音的清晰度,麦克风阵列主要依靠波束形成抑制主瓣外的声音干扰来实现噪声抑制的功能。
增益调节:主要解决拾音距离变化的问题,由于远场的交互距离可大可小,所以声源发声的大小也不同,比如人离麦克风较远或人发出的声音较小的时候,麦克风拾取的声源信号就会比较小,这时需要对麦克风收集的信号进行放大处理,从而提高语音识别的准确性。当人凑着麦克风讲话的时候,或者外界发出的声音较大的时候,麦克风采集的信号较大,甚至超出麦克风可以采集到的范围,这时需要麦克风阵列进行相关的处理,适当的衰减声源信号,从而达到拾取声源的有效平衡。
回声消除:这里的回声并非传统意义上的回声,它指的是语音交互设备自己发出的声音,比如音箱在播放音乐的时候,用户想打断它,此时,回声指的是音箱本身播放音乐的声音。如果麦克风阵列没有回声消除功能,那么麦克风采集的声音就包含人发出的指令声音和音乐声音,在这种情况下,显然会对在语音识别的效果产生干扰,回声消除的目的就是要消除音乐的声音而保留用户的人声。
麦克风主要可以抑制四类噪音:分别为混响,背景噪音,人声干扰和回声。
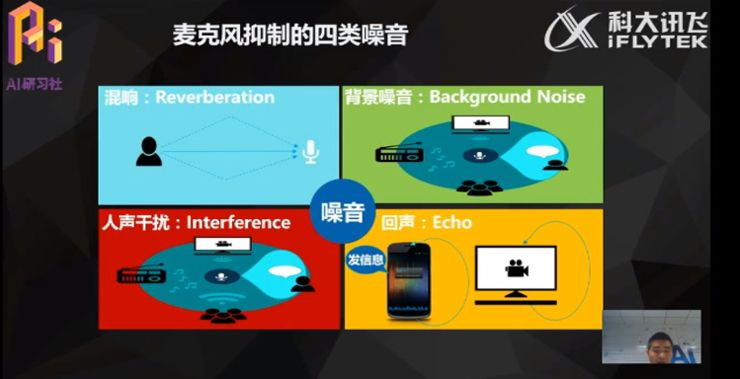
混响:人讲话的声音被各种障碍物反射产生的声音,如被墙壁,地板,天花板等障碍物反射,混响的声音通常距离声源发出的声音时间间隔较短,人耳主观上感觉不到,但机器在采集的时候往往可以采集到。
人声干扰:为什么要注意人声干扰?由于实际上麦克风阵列在解决噪音干扰的时候,人声干扰会对麦克风的识别效果产生最大的影响,因为往往做人机交互的时候,麦克风阵列收集的声源的声音就是人声。
噪声和回声前面刚刚介绍过。
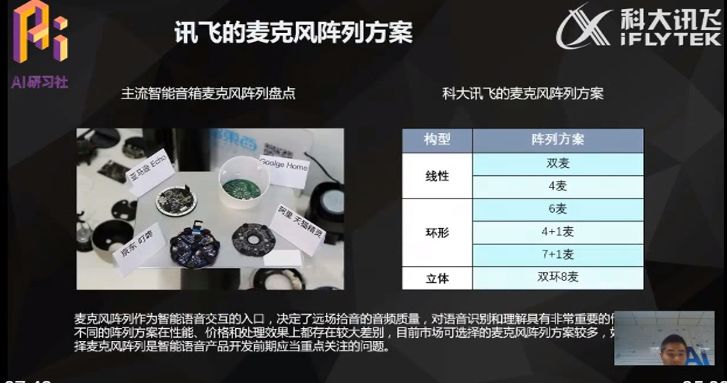
实际上,当前主流的智能音箱采用的麦克风阵列列方案是不太一样的,比如亚马逊的 echo 最早使用的是 6+1 麦克风方案;Google Home 使用的是双麦克风方案;叮咚音箱使用的是 7+1 麦克风方案;阿里去年推出的天猫精灵采用的是 6 麦克风阵列方案。
目前讯飞向外提供三种构型的麦克风阵列,分别是线性,环形和立体阵列。
如何选择麦克风阵列?
根据我近些年与开发者和用户沟通得出的经验总结,选择麦克风阵列通常有四个要素,分别为使用场景,ID&MD 设计,交互链路和产品定价。

使用场景

关于使用场景,我想通过两个例子进行介绍,不少商场正在使用机器人来替代人类进行导购服务,商场周围的环境非常嘈杂(一般能达到 70 分贝以上),这种环境对降噪的要求很高,一般需要选择抗噪能力比较强的麦克风阵列,同时由于人和机器的相对位置变化性较大,所以机器人往往需要具备 360 度的唤醒定位功能,也就是当用户处于机器人的侧面并发出指令的时候,希望机器人可以调转到用户所处的方向,因此在做商用机器人解决方案的时候,通常会选择环形 6 麦或以上的阵列,这样的话,整体抗噪和定位的效果能达到该场景的要求。
第二个例子,如电冰箱这个场景中,由于家居场景比较安静(通常在 40 到 55 分贝左右),该场景对麦克风阵列的抗噪音要求并不是很高,因此可以选择抗噪能力稍弱的麦克风阵列。另外,如冰箱这类家电往往是靠墙放置,因此不需要 360 度的唤醒定位,通常有时候不需要声源定位就可以进行远场拾音。还有一点需要说明,家电产品通常对节能环保要求较高,功耗要求也比较严格。因此选择较少的麦克风阵列可以保证整体的功耗,所以通常在冰箱上会使用双麦阵列方案或四麦阵列方案。
ID&MD 设计
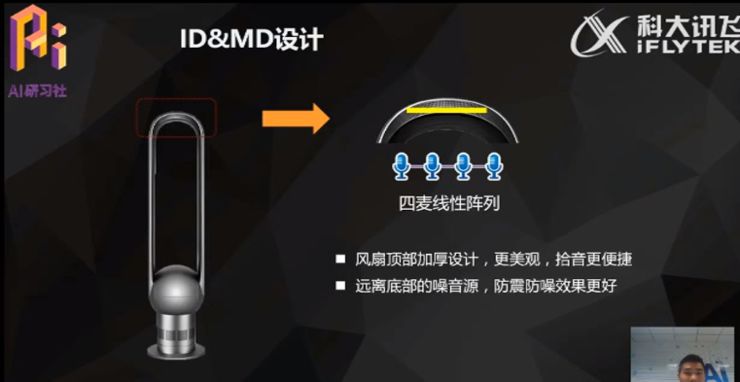
设备植入麦克风阵列时,通常需要对产品的外观和结构件进行开口,这对整体的外观设计和产品都会产生一定的考验,外观上需要结合机器的整体外观,结构上主要看声学整体的效果。
影响声学效果的主要因素,包括麦克风阵列的构型,孔径,孔深,开孔率,声腔的密闭性以及防震防水等,比如图中的无叶风扇,当我们确定了在顶部采用四麦阵列方案之后,就需要考虑如何对这个方案进行优化,对此产品上进行了两点处理:1,在风扇顶部加厚处理,这样可使风扇整体更美观,顶部加厚处理还有助于开孔和加大开孔率,麦克风拾音也更便捷。2,考虑到底部为风扇电机的噪音源,因此将麦克风置于顶部。
交互链路
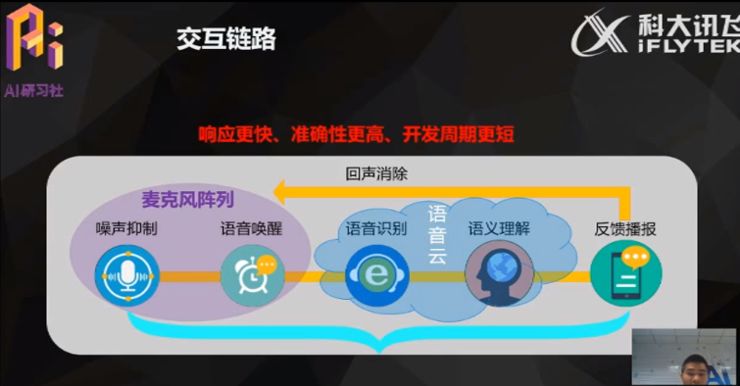
由于各技术厂商的算法体系不同,在选择语音交互方案时,最好能选择经过前端和云端协同优化的算法,比如讯飞的云端识别会针对自身的麦克风序列的音频数据进行大量的优化,因此在云端和前端的配合上较其他家具备明显优势:整体的响应速度更快,准确性更高,开发周期会更短。而如果麦克风阵列和后端的云端使用不同厂家的方案,那么在后期的响应、协同的配合上、准确性,以及开发阶段的联调和配合上,都会遭遇相当大的考验。
产品定价

麦克风阵列的使用成本通常包括四块:分别为麦克风,模组,喇叭以及其他配件。目前,对麦克风阵列来讲,最大的区别主要体现在麦克风和模组上,比如天猫精灵的方糖音箱采用的就是双麦克风阵列方案,叮咚 mini2 为六麦阵列方案。另外在模组上,六麦阵列要处理六路的麦克风拾取的音频信号,因此在芯片的配置和数模转换的处理上都需要更大的开销,所以从产品定价上来看,可以理解天猫精灵方糖定价为 199 元,而叮咚 mini2 定价为更高的 299 元。
通过上面的四个要素可以总结出,选择麦克风阵列,要核心考虑不同麦克风阵列的特点。目前讯飞常用的麦克风阵列方案主要有双麦阵列方案,环形六麦阵列和双环八麦阵列方案。
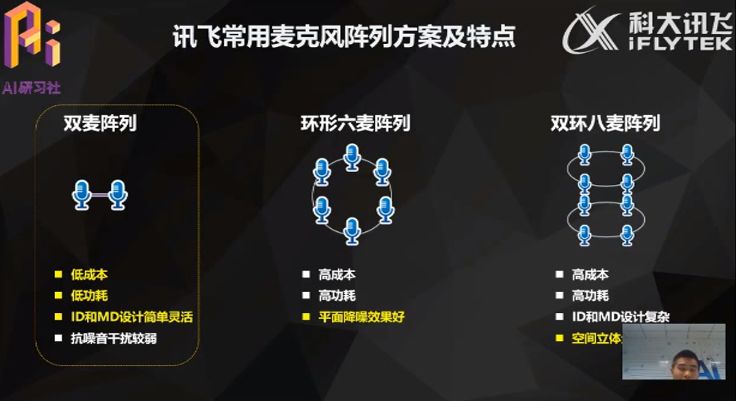
双麦阵列方案:采用双麦设计,因此成本和功耗均低且 ID 和 MD 设计简单灵活,但抗噪音干扰较弱。
环形六麦阵列:麦克风数量增加到 6 个,成本和功耗也随之变高,优点是在环形平面上降噪效果好。
双环八麦阵列方案:可进行空间立体的群像拾音,由于麦克风数量众多,导致成本和功耗更高。另外,由于采用立体结构的 ID 和 MD 设计,设计起来相对复杂。
由于双麦克风阵列的性价比较高,因此其使用领域也相当广阔。接下来介绍双麦克风阵列以及行业应用。
双麦克风阵列以及行业应用

目前主流的远场双麦克阵列方案,包括科胜讯的 CX20921 方案和讯飞双麦 DSP 方案。

讯飞双麦 DSP 目前对外提供一套模组方案:

即通过 DSP 芯片和 ADC,Flash 的整合,实现一套完整的交互模组,该模组的特点为集成简单,开发便捷。当用户在使用这套模组的时候,前端麦克风将采集到的音频输入到模组,模组输出 16K 和 32Bit 的数字信号,传给识别端,这样就可形成前端的远场拾音。整体方案支持麦克风的间距在 20 到 120mm,这样在整个 ID 和 MD 的结构设计上会更加灵活。
讯飞双麦阵列芯片方案
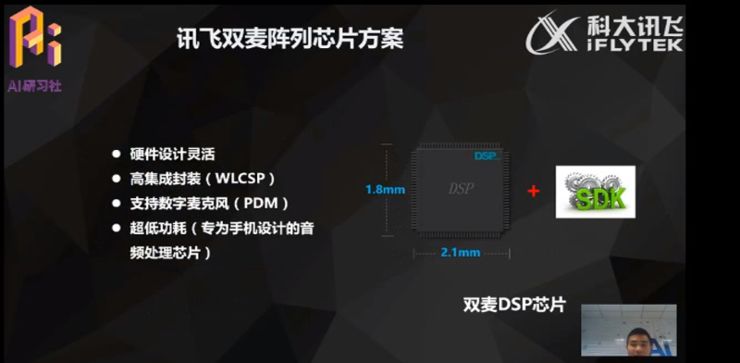
科大讯飞支持芯片化的定制方案,该方案基于核心算法处理的 DSP 芯片+讯飞的算法 SDK。方案的主要特性:硬件设计灵活。该方案还存在以下几个特点:高集成封装,这颗 DSP 芯片的高集成封装在尺寸上可达到 1.8*2.1mm,可以应用于手机和穿戴设备上;支持数字麦克风直接接入的方式;由于该 DSP 芯片也是专为手机设计的音频处理芯片,所以整个芯片方案功耗很低。
该方案里植入了讯飞的双麦阵列降噪算法,其中的算法特性见图中的四点描述。

远场拾音:可支持 3 米的远场拾音,在安静环境下可达到 5 到 10 米。
语音唤醒:双麦方案里植入的算法可支持中英文的语音唤醒。另外,由于采用了低功耗的 CNN 唤醒技术,因此在待机唤醒状态下的功率很低。
噪音抑制:可以抑制常见的混响干扰声和环境噪音。
回声消除:近期,科大讯飞在双麦阵列的回声效果上进行了优化,目前可支持全双工立体声的回声消除,且设备本身发出的播报音达到 80 到 90 分贝,该效果通常可满足大多数产品的需求,甚至包括很多音箱的需求。
目前,不少用户都来提关于「双麦阵列唤醒率」的问题,我在这里跟大家解释一下,为什么没有给出唤醒率的具体指标?主要因为唤醒率是根据周围外部环境的因素和麦克风构型,再考虑测试环境的影响会导致实际测试到的唤醒率效果不一样,这就要求在实际评估唤醒率的时候,需要综合考虑外部所有的因素来进行评估。
就目前的应用场景来看,双麦阵列方案已经覆盖到了很多领域,下图为主要领域的产品举例。

机器人领域:使用到语音交互的主要是商用服务和消费级机器人,双麦阵列方案主要应用于陪伴型,消费级机器人以及服务机器人上。
车载领域:目前大多数车载带屏设备都使用基于双麦阵列的交互方案。另外,车载类配件也推荐使用双麦阵列方案,目前市场上使用双麦阵列案例有,讯飞去年推出的小飞鱼智能车载助手。
智能家居场景:先说智能音箱,除了 google Home 外,亚马逊的 echo 以及阿里的天猫精灵都采用了双麦阵列方案,因此在未来的音箱领域,双麦克风方案会受到越来越多的关注,另在冰箱,空调或家庭空调的控制面板中,都有使用双麦方案。
手机及可穿戴设备:苹果 air pod 采用的也是双麦方案,华为更早推出的 B2 手环也是基于双麦的降噪方案。
随着双麦阵列方案的不断优化,应用场景也越来越多,欢迎广大开发者使用讯飞的双麦克风阵列方案。
另外,讲师还回答了直播中大家提出的关于「人机交互」和「单麦克风的局限性」的问题。AI 科技评论将问答内容整理如下:
Q & A

Q:使用双麦克风阵列方案在人机语音交互中能做到什么效果?
A:家居,汽车,课堂等噪音较少的场景可以使用,户外情况下可用于耳机,手环等穿戴设备,3 米内抗干扰,安静环境下交互距离可达 5 到 10 米;可以满足智能音箱,陪伴机器人在较大音量播放音频内容时的打断效果;实际的评测过程中应尽量采用真实使用场景下的体验和测试,避免在办公室等外界干扰较大的环境或混响大(玻璃较多)的环境中进行测试。
Q:简单介绍一下人机交互?
A:人机交互的模式有很多种,这里提到的语音交互属于人机交互的一种,除此之外还包括视觉类的交互和传感类的交互,比如通常使用的家电或消费类电子产品都带有很多传感器,比如触摸手机屏幕,指纹解锁,甚至是通过按键,这类都叫人机交互。未来的人工智能更多的是所有交互的一个智能体,其中跟人类最接近的是语音和视觉交互。可以这样说,人接收到的信息,80% 是通过视觉来接收到的,但人向外传递的信息 90% 通过语音实现。因此视觉和语音会在未来的人机交互中占有很大的比例。
Q:单麦克风的局限性?
A:目前也有很多产品在考虑使用单麦克风方案,可能是从成本上或者是从场景本身(静场场景)来考虑,或是噪音比较小的场景。如果从成本的考虑的话,随着未来产品的不断迭代,双麦阵列会渐渐与单麦阵列的成本差别越来越小,同时双麦阵列可以应付一些突发的情况,所以双麦阵列会逐渐替代单麦克风阵列。
Q:为什么需要麦克风阵列?
A:实际的语音交互需要麦克风阵列,打个比方,如果人类没有耳朵,就不能对外界的声音进行拾取,只能通过眼睛或其他五感(如触觉等)来获取外界信息,这样就缺少了对于外界的听觉感受。
以上就是本期嘉宾的全部分享内容,本次讲师李伟也在公开课视频的最后附有联系方式,大家如有问题想要交流的可以前往查看。更多公开课视频请到雷锋网 AI 慕课学院观看。
对了,我们招人了,了解一下?

BAT资深算法工程师独家研发课程
最贴近生活与工作的好玩实操项目
班级管理助学搭配专业的助教答疑
学以致用拿offer,学完即推荐就业
扫码或点击阅读原文了解一下!

┏(^0^)┛欢迎分享,明天见!





