【V直播干货】北大王云鹤解读神经网络压缩算法,百度奖学金经验分享(22 PPT)

新智元整理
【新智元导读】深度神经网络的压缩旨在将具有大规模参数的神经网络在保持精度损失不大的条件下,压缩成参数量和计算量较少的轻型神经网络,这个课题非常具有应用前景。北京大学信息科学技术学院13级智能科学系博士生王云鹤,师从北大许超教授和悉尼大学的陶大程教授,他主要的研究方向为深度神经网络的压缩与加速算法。近日,他在新智元进行了一场微信群直播,分享了他课题的研究成果。

直播嘉宾简介:王云鹤,来自北京大学信息科学技术学院,是13级智能科学系博士生,2017年百度奖学金获得者之一。指导老师为北京大学的许超教授和悉尼大学的陶大程教授。主要的研究方向为深度神经网络的压缩与加速算法。
以下为本次直播精彩实录:
新智元:恭喜您获得2017百度奖学金,请您谈谈获得这一奖项的历程吧?
王云鹤:首先是在9月份的时候,分别收到了两封邀请申请百度奖学金的邮件。一个是因为一些发表过的论文,一个是来自曾经获得过百度奖学金的徐畅师兄的邀请。然后就按照百度奖学金的评选流程一点一点地准备材料。比较激动的是得知入围最终答辩名单的时候,一方面庆幸于自己能入选,一方面看到了诸多海内外名校同学们的简历之后略微有些紧张。幸运的是,最终通过了答辩,获得了2017年的百度奖学金。
新智元:有哪些经验可以给今年想要申请百度奖学金的后来者分享的?
王云鹤:第一点,百度奖学金的主要评选标准是在个人领域内的学术成果,所以应该尽量地在本领域内作出更多、更具有影响力、更具有实用价值的学术成果。
第二点,由于评选流程中的答辩环节占有很大的比分,如何在短时间内把自己的成果整理好并向评审专家表达清楚,也是一个非常重要的能力。
新智元:据了解,您现在主要研究的课题是深度卷积神经网络压缩,给我们分享下这是怎样的一个课题?您目前取得了哪些成果,以及正在进行中的研究项目是什么?
王云鹤:深度神经网络的压缩旨在将具有大规模参数的神经网络在保持精度损失不大的条件下(例如top5的准确率下降不超过1%),压缩成参数量和计算量较少的轻型神经网络。我现在的成果有利用离散余弦变换的网络压缩(NIPS 2016)、紧致的特征图学习方法(ICML 2017)、基于对抗学习的轻型网络生成方法(AAAI 2018)等。现在正在进行中的研究项目是设计具有更高计算效率的神经网络,期望用更少的参数来完成更多的任务。
新智元:当初为何会选择深度卷积神经网络压缩这一课题?你觉得它有怎样的发展前景?
王云鹤:深度卷积神经网络压缩这个课题非常具有应用前景,因为深度学习模型在大多数任务(例如图像识别、图像超分辨率等)上的精度已经达到了落地需求,但是它们的线上速度和内存消耗还没有达到落地需求。从2012年的AlexNet到2015年底的残差神经网络,已经成功的把图像分类的问题的分类错误率压到了5%以内。同时,还有一些其他的基于深度学习的应用,例如图像的超分辨率,人脸识别,图像去噪等。这些基于深度学习的算法几乎都全面超越了传统方法。
但是,这些模型基本上只能在拥有GPU的服务器或者PC上使用,因为神经网络中包含的卷积实在是太多了,所带来的计算量也是十分巨大的。我们不可能直接将它们移植到手机或者其他的移动设备上。举个例子,VGGNet是大家最常用的一个神经网络,一个16层的VGGNet的权值差不多有520MB,用它去对一张图进行处理的话,需要做200亿的浮点数乘法运算。移动设备(例如手机、智能摄像头、无人车等)的内存、计算耗电量、散热性能的限制,都会导致这些网络不能直接的被直接使用。所以如何设计更轻便、更高精度的深度神经网络是当下的一个研究热点。
新智元:目前深度卷积神经网络有哪些成功的应用?
王云鹤:最著名的当属深度卷积神经网络在ImageNet上的分类正确率已经超过了人眼。还有人脸识别、人体属性识别等,已经在很多公司或者政府部门中应用起来。相比于这些相对比较简单的任务,更多的研究人员开始关注于物体分割、姿态识别、低分辨率识别等,相信在一两年内这些任务都可以被深度卷积神经网络解决,使得人类的生活更智能化。
新智元:您预测哪些领域将会得到革命性的改变?
王云鹤:计算机视觉领域内的诸多算法的性能已经被深度卷积神经网络成功地刷新了。例如,图像超分辨率、图像去噪、图像识别、物体分割等。将这些技术和控制、雷达技术等结合起来,我们可以预料到无人车领域未来将会被人工智能算法成功地改变。
新智元:对于希望进入这一领域的学弟学妹您有怎样的建议?有哪些推荐的书籍?需要具备哪些数学知识?
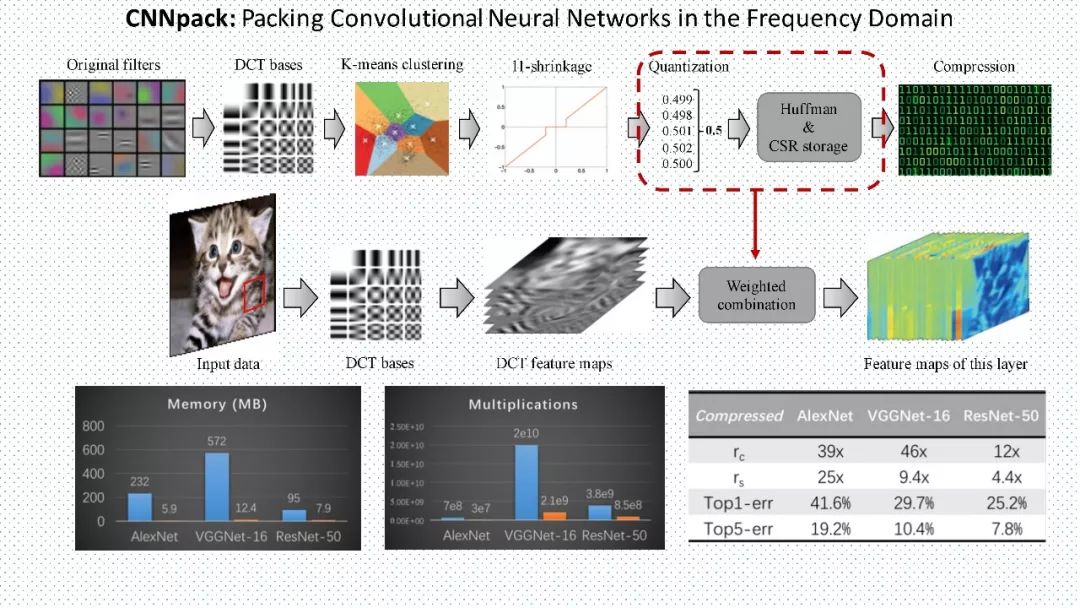
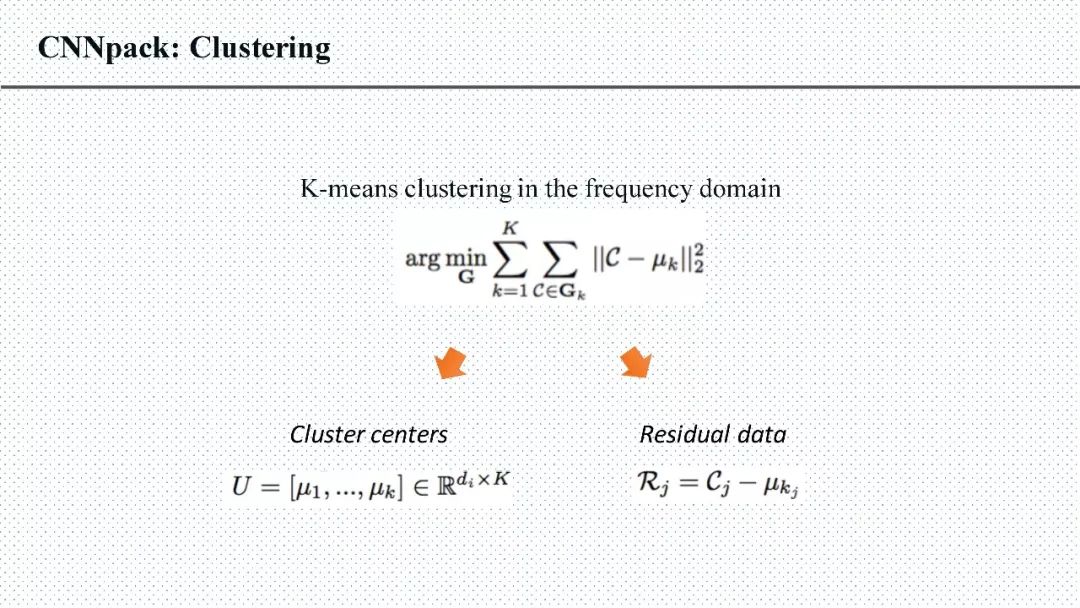
王云鹤:首先,深度卷积神经网络的主要应用场景是计算机视觉,所以一些基础的计算机视觉知识就需要提前掌握(《数字图像处理(冈萨雷斯)》等)。例如,在我们提出的CNNpack算法中,离散余弦变换是一个在图像压缩领域常用的工具,而卷积核通常都具有一些特有的图像性质,所以可以在频域上获得非常好的压缩效果。另外,卷积神经网络的计算和反向传播的计算都是一些基础的矩阵运算,所以线性代数、矩阵论等基础知识也需要多学习。对于损失函数的设计,一些优化的基础知识也应该多加学习。
新智元:您博士毕业之后的选择是继续深造还是找工作?如果是找工作,对未来的公司有着怎样的期望?
王云鹤:工作啊~原因有三点: 第一,在工业界的背景下,我们可以发现更多有意思和有意义的问题;第二,工业界有更多有价值的数据,如何在这些数据集上获取更好的性能,比单纯地在公开数据集上刷数据更有意义;第三,自己做过的一些算法,也想在公司进行尝试争取落地,证明它们的价值。对未来公司的期望,做前沿的科技,然后尽量不加班哈哈。
王云鹤博士分享了一篇去年的论文:《CNNpack: Packing Convolutional Neural Networks in the Frequency Domain》,本文末附上相关slides。以下精选部分王云鹤对CNNpack算法的答疑:
问:pack方法参数减少量和精度降低量大概是什么关系?
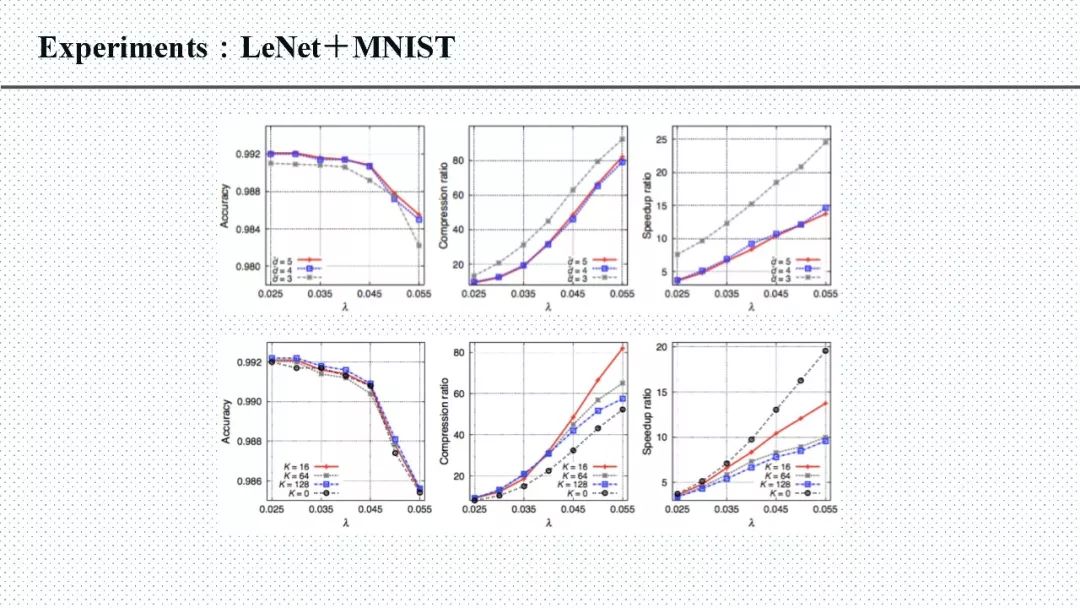
答: 在CNNpack算法里面,有一个参数来控制卷积核在DCT频域上的稀疏程度,在实验结果中表明,参数越大(越稀疏)精度越低。大概是这样的效果 有趣的是我们在很多网络上都测试了一下这个参数 最优的参数基本相差不大。
问:请问这种压缩算法未来是在FPGA硬件,NAVIDA TX1/2上部署实施么?
答:可能吧哈哈~ 因为这样的算法会破坏原来的卷积神经网络的计算方式,最直接的就是说conv.cuda 这种函数我们需要重新写,所以需要做的工作量还是很大的。
问:因为工作需要,要进行模型压缩,但这个方向好像比较不容易找到入门教程,而且理论比较艰深,而且工作很散乱,就是说用各种方式解决方案的都有,有没有一个目前大家都公认比较普适的方法?
答:大家用得最多的应该是量化 (quantization),很多都表明 8bit量化基本是无损的,操作起来又比较简单。
问:请问未来在网络压缩方面,还有哪些方向可做呢?
答:模型压缩有很多分支,基于稀疏表示的,量化,矩阵分解,学习小网络(teacher-student learning paradigm 参考FitNet和Hition的KD),学习feature map等。这些算法都有不同的优势和缺点,所以还有很多可以做的空间。
问:你的算法 ,有在CPU上跑过运行时间吗? 和caffe 带MKL库比,对比如何?
答:有的,实际加速比是要略低于理论上的加速比的,一方面是代码优化的不够,另一方是除了卷积之外,还有很多别的操作很占用时间,尤其是数据的拆散重组传输等。 caffe+MKL没有比较过。
问:对Teacher-student的原理不太明白,为什么可以用小网络学习大网络的结果?而直接用小网络训练则无法奏效?能给个入门级的解释么?
答:由于小的网络的参数量比较少,所以直接学习到的特征就不如大网络学习的好(精度不够高)。那么,最直观的想法就是说我们期望小网络(student network)可以生成大网络(teacher network)的特征,分类器就可以很自然地用这些特征去做出准确的预测结果。总而言之,就是在训练小网络的同时,加上一些正则(从大网络中提取信息),辅助他的训练。
问:频域压缩如何解决神经网络掉精读的问题?
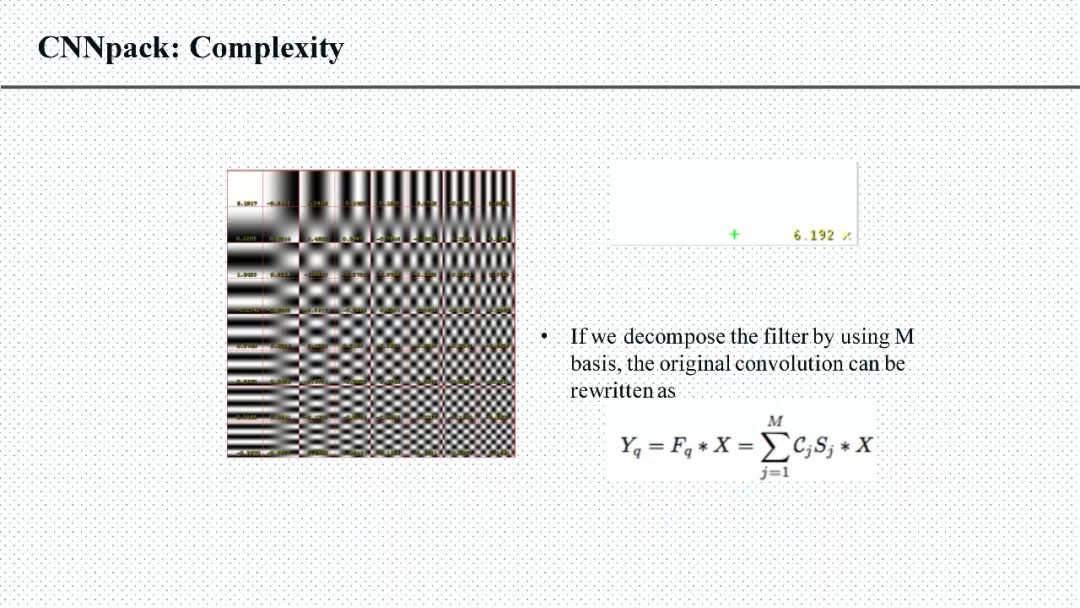
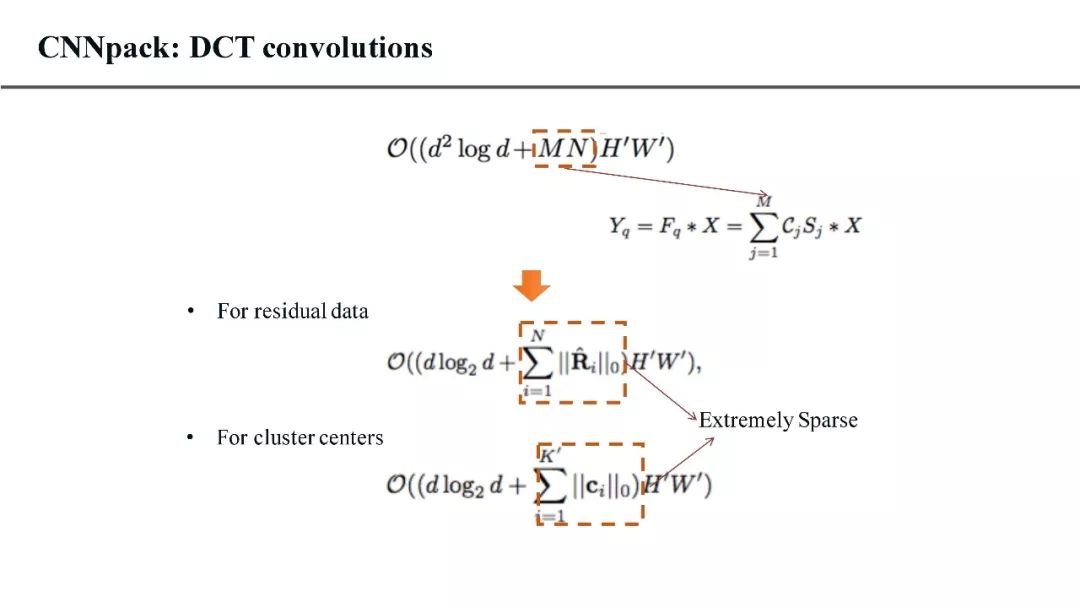
答:在我们提出的CNNpack算法中,有一条有意思的证明,空域(原始卷积核)上的卷积计算等价于频域上(将输入数据和卷积核都通过DCT变换映射到频域中)的卷积计算。所以我们在频域上保持稀疏的网络结构,利用训练数据继续对压缩后的网络进行优化,就可以提升它的精度。
问:关于cnn的压缩和加速方面有哪些经典的必读文章吗?尤其是工程上有价值的?或者综述性质的文章。
答:模型压缩有很多分支,基于稀疏表示的,量化,矩阵分解,学习小网络(teacher-student learning paradigm 参考FitNet和Hition的KD),学习feature map等。这些算法都有不同的优势和缺点,所以还有很多可以做的空间。这几个分支里面比较著名的就是Han song的deep compression(ICLR 2016),Hiton的Knowledge Distillation (NIPS workshop 14),XNORNet(ECCV16)。综述性质的文章还没有看到,回头我打算写一个。
问:CNNpack在inference加速上能达到什么水平?代码有没有开源或者准备开源的打算?
答:inference 的加速比是要略低于理论上的加速比的,一方面是代码优化的不够,另一方是除了卷积之外,还有很多别的操作很占用时间,尤其是数据的拆散重组传输等。代码貌似不能开源了,这个算法的专利授权给华为海思那边了。
问:有没有与轻量网络结构如mobilenet验证过效果?
答:mobilenet还没做过,这个算法是去年年初做的,那时候大家都在AlexNet和VGGNet上做。不过,任何的网络都包含一定比例的冗余信息,这是可以确定的。
问:对于有大量的小卷积核如3乘3的网络,会不会不适合这种算法?
答:我觉得模型压缩往下的走向应该是如何设计更好(memory更小,计算量更少)的网络来达到更高的精度。例如ShuffleNet 和 ResNext,很棒,参数量没有增加,精度上去了。也是可以做的 ResNet中包含了大量的3x3的参数。我们把这些小的卷积核拿出来,也是具有一定的smoothness的。这是一个在ResNet上的实验。
问:如果网络已经做过8bit量化,是否还适合再应用cnnpack的方法?
答:可以的 CNNpack里面也带了量化 最后平均的码长大概是5~6bit左右
问:这个对于memory的压缩量是多少呀?和BinaryNet这样二值化网络内部的weight和activation的方法相比,它的区别和优势在哪里呀?
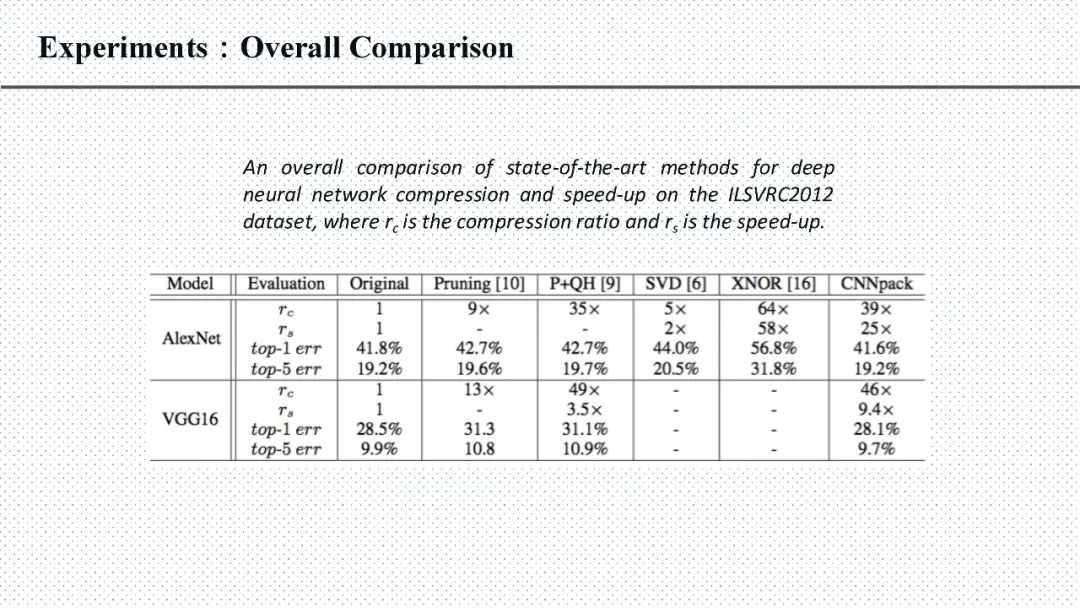
答:对AlexNet和VGGNet这种,用我们提出的CNNpack可以达到一个30倍以上的内存压缩。和单纯binary的算法相比较,最大的优势是还可以保证网络的精度。事实上这些方法都不冲突,是可以相互融合来达到更高的精度的。例如,binary如果做到字典的系数上是不是会获得更高的性能。
问:本身基于演绎推理的算法对于基于归纳推理的深度学习的启发一般来自什么方面?
答:这个问题比较深奥……换一个角度说吧,就说传统CV算法对深度学习算法的影响其实非常大,比如最早的CNN基本上只是一层一层的平铺过来,后面的GoogleNet 加入了inception,这个模块引入了multi scale信息,所以精度就一下子提高了好多。一直觉得resnet也引入了multi-scale的信息。
附:CNNpack slides:

















加入社群
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号: aiera2015_1 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名-公司-职位;专业群审核较严,敬请谅解)。
此外,新智元AI技术+产业领域社群(智能汽车、机器学习、深度学习、神经网络等)正在面向正在从事相关领域的工程师及研究人员进行招募。
加入新智元技术社群 共享AI+开放平台


