论文浅尝 - ICLR2020 | 通过神经逻辑归纳学习有效地解释
论文笔记整理:朱渝珊,浙江大学直博生。研究方向:知识图谱,快速表示学习等。

论文链接:https://arxiv.org/pdf/1910.02481.pdf
本文是ICLR 2020的一篇关于知识图谱中关于复杂(树状、组合)规则可微学习的文章。提出了神经逻辑归纳学习(NLIL),一种可微分的ILP方法,扩展了针对一般ILP问题的多跳推理框架。NLIL将搜索空间分解为一个层次结构中的3个子空间,每个子空间都可以通过注意力高效地进行搜索。作者证明通过这种方式模型可搜索的规则比使用NeuralLP等方式搜索的规则长10倍,且拥有更快的速度。
1. 相关背景
1.1 Inductive Logic Programming (ILP)
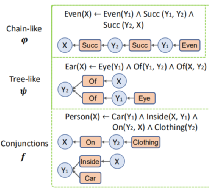
一阶逻辑系统有3个组件:实体,谓词和公式。以下图为例:
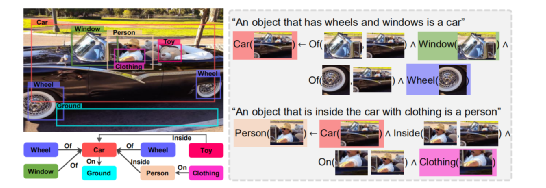
实体是对象x∈X。图像中某区域是实体x,所有可能区域集合是X。
谓词是将实体映射到0或1的函数,Person:x →{0,1},x∈X。谓词可有多个输入,如“Inside”是接受2输入的谓词,参数的数量称为Arity。原子是应用于逻辑变量的谓词符号,如person(X)和Inside(X,X')。
一阶逻辑(FOL)公式是使用逻辑运算{∧,∨,¬}的原子的组合。给定一组谓词P ={P1...PK},谓词Pk的解释定义为一阶逻辑蕴涵,
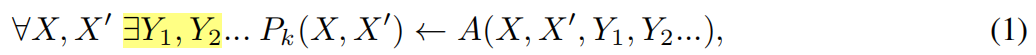
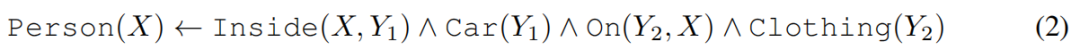
代表着这样的知识:“如果物体在车内,身上有衣服,那就是人”。
1.2 多跳推理:
ILP问题与KG多跳推理任务相关。此处,事实存储在谓词Pk的二进制矩阵Mk中,Mk(i,j)=1表明三元组
给定查询q=

M(t)是在第 t 跳中用的谓词的邻接矩阵。v(t)是路径特征向量,v(t)中第j个元素计算从x到xj的唯一路径的数量。经过T步推理后,查询的分数计算为
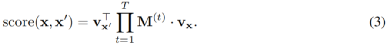
对于每个q,目标是(i)找到一个合适的T,(ii)为每个t∈[1,2,...,T],找到一个合适的M(t),使得score最大。这两个离散的选择可以放宽,即
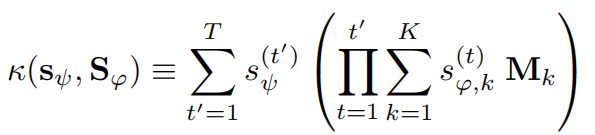
此为软路径选择函数,参数为
(i)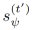
(ii)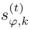
这两个注意向量是通过下述模型生成的

参数w可学习。以前的一些方法,T(x; w)是一个随机游动采样器,它会生成one-hot向量来模拟从x开始的图形上的随机游动。在NeuralLP中,T(x; w)是一个RNN控制器,目标定义为
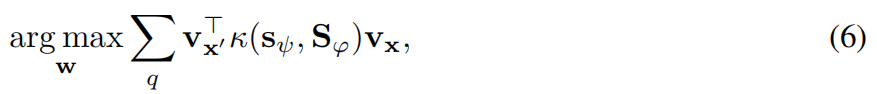
在多跳推理中学习关系路径可以解释为使用链状FOL(一阶逻辑)规则解决ILP问题
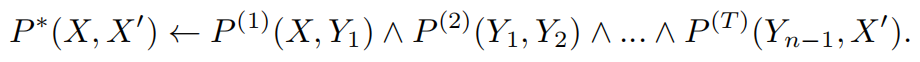
与基于模板的ILP方法(如∂ILP)比,此类方法在规则探索和评估中非常有效。但是,存在两个问题
(P1)规则的表达性不足,仅能表达链状规则,例如等式(2)不是链状的就不能表示。
(P2)注意生成器T(x; w)取决于特定查询q的实体x,这意味着针对目标P*生成的解释可能因查询而异,很难学习KG中全局一致的FOL规则。
2. 算法模型
推理过程中所有中间实体都用首尾实体表示
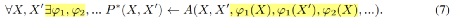
如上将公式(1)转换为(7)所示,实现方法就是通过转换的函数(操作符):将每个谓词k都视为一个操作符ϕk,如下所示,U是一元谓词,B是二元谓词
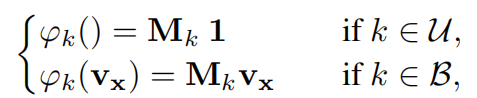
则规则(2)可以表述成规则(8),这样首尾实体在具体实现时用随机初始化的向量表示,摆脱了数据依赖
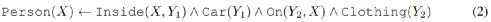
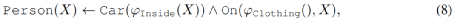
扩展到树状规则
提出Primitive Statements(基本语句)的概念,公式(8)可视为两个基本语句组成,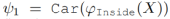
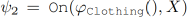
每个基本语句都是从输入空间映射到一个置信度得分标量
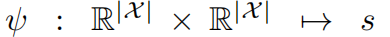
公式(3)可表示为
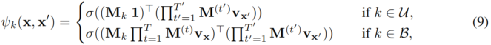
如下图所示,树状规则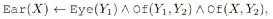
规则之间的组合
把基本语句用{∧,∨,¬}进行逻辑组合,如公式(8)就是两个基本语句的逻辑“and”操作。逻辑 “not” 及逻辑 “and” 运算如下表示

第l级的公式集以及最后的得分就可如下方式推得
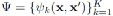
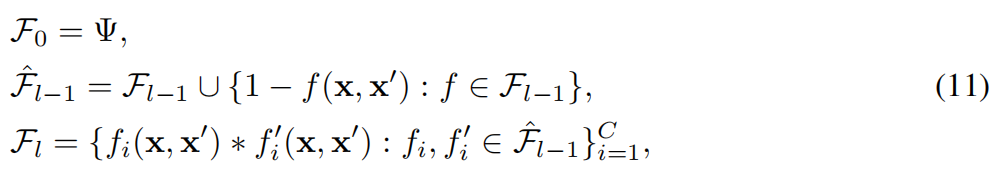
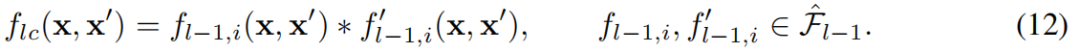
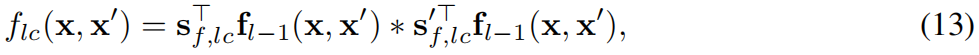

整个流程可以如下图所示
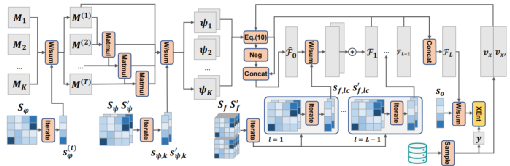
其中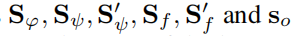
具体实现上:Hierarchical Transformer Networks for Rule Generation,引入“虚拟”自变量X和X’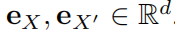
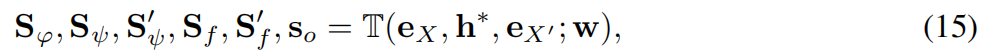
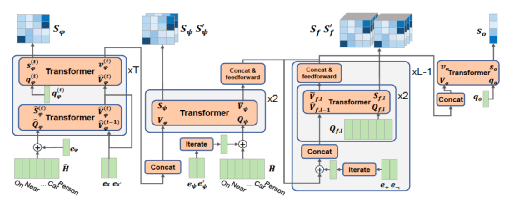
其中h*是P*的嵌入,因此注意力仅相对于P*有所不同。
3. 实验
Baseline
•NeuralLP (Yang , 2017)
•∂ILP (Evans , 2018)
•TransE (Bordes , 2013)
•RotatE (Sun , 2019)
Dataset
•ES(Even-and-Successor) (Evans , 2018) :两个一元谓词Even,Zero和一个二元谓词Successor。目标是学习一组整数上的FOL规则。本文对从0开始的10、50和1K个连续整数评估。
•FB15K-237
•WN18
•VG(Visual Genome),视觉领域数据,以物体检测任务为基础,将图片上的物体之间的关系抽象成小的知识图谱
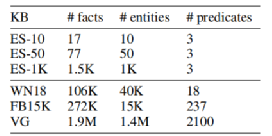
FB15k-237和WN18数据上链接预测
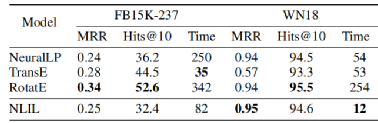
ES数据上与不同算法对比,(a)时间 (mins),(b)规则长度
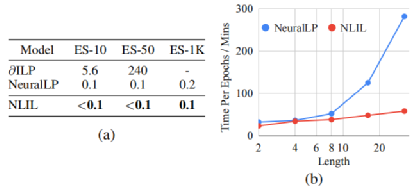
VG数据集,不同training-set大小
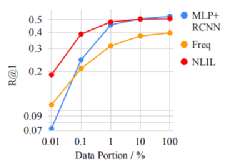
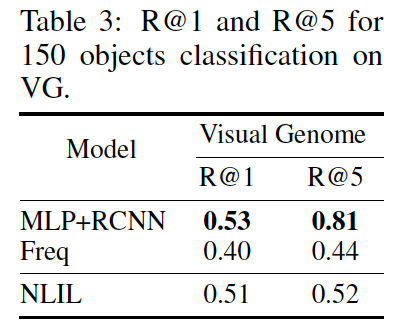
虽然基于丰富标签数据的监督学习方法达到了比较好的效果,但是NLIL仅仅利用稀疏的(0/1)标签就能达到匹敌的效果,甚至显著优于一种监督模型baseline的效果,进一步体现出了模型的有效性。在少样本学习(训练样本仅0.01%)也体现出更好性能。
4.总结
本文提出了神经逻辑归纳学习,这是一个可区分的ILP框架,可以从数据中学习解释性规则。
证明了NLIL可以扩展到非常大的数据集,同时能够搜索复杂的表达规则。更重要的是,本文还证明了可扩展的ILP方法在解释监督模型的决策方面是有效的,这为检查机器学习系统的决策过程提供了另一种视角。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



