华为诺亚ICLR 2020满分论文:基于强化学习的因果发现算法
机器之心发布
机器之心编辑部
人工智能顶会 ICLR 2020 将于明年 4 月 26 日于埃塞俄比亚首都亚的斯亚贝巴举行,不久之前,大会官方公布论文接收结果:在最终提交的 2594 篇论文中,有 687 篇被接收,接收率为 26.5%。本文介绍了华为诺亚方舟实验室被 ICLR 2020 接收的一篇满分论文。

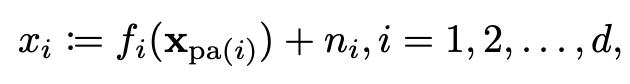
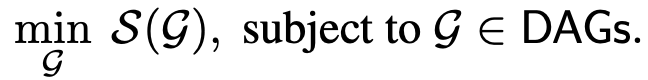
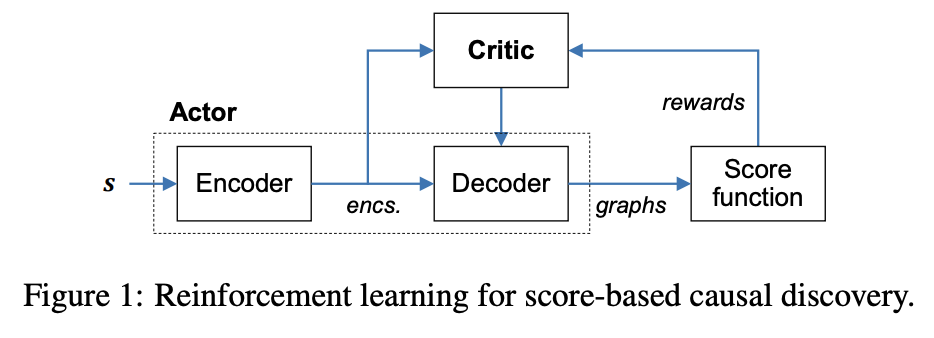

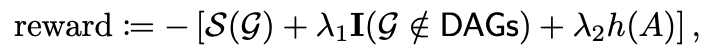
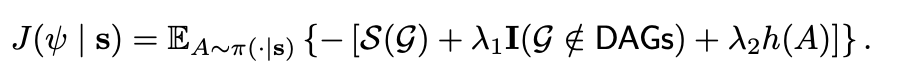
高斯和非高斯噪声的线性数据模型
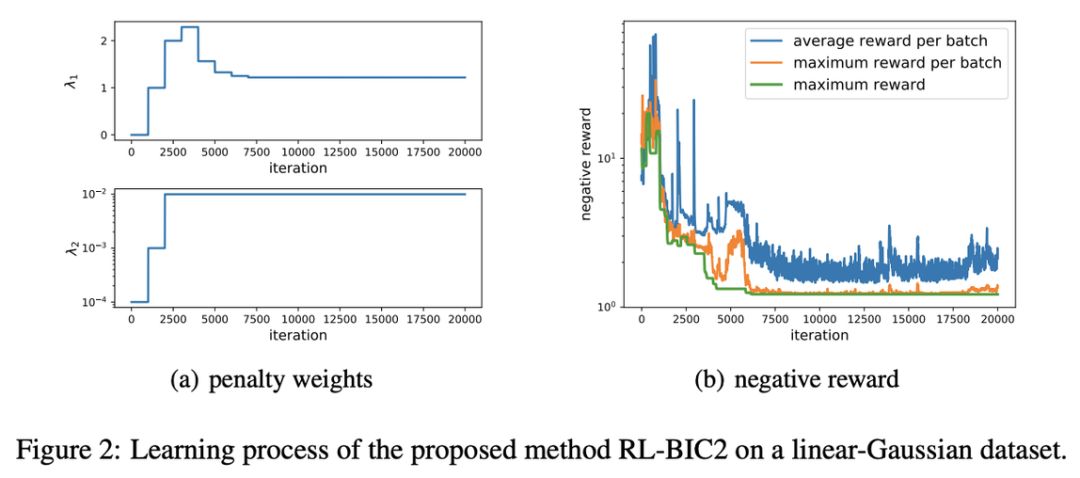
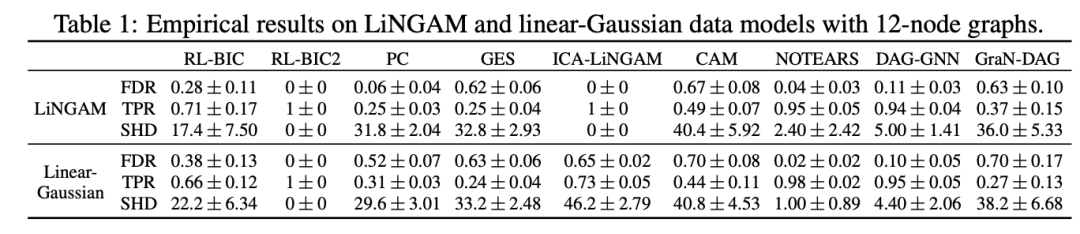


登录查看更多
相关内容
专知会员服务
131+阅读 · 2020年4月19日



相关VIP内容
专知会员服务
131+阅读 · 2020年4月19日
相关资讯
相关论文