维基百科你已经是个大百科了,该自己学会用ML识别原文出处了
选自wikimediafoundation
作者:Miriam Redi、Jonathan Morgan、Dario Taraborelli、Besnik Fetahu
机器之心编译
参与:Nurhachu Null、思源
维基百科可能是我们认为比较客观真实的材料了,但它包罗万象却又会引起一些小问题,例如很多句子或说法提供不了引用出处。那么机器学习在预测引用,并给出引用原因方面就显得非常重要,它会让这一自由的百科全书更加完美无瑕。
让维基百科保持高质量的一个关键机制就是内联引用的使用。通过引用,读者和编辑者可以确定一篇文章中的信息准确反映了其来源。正如维基百科的可验证性原则所要求的,「受到质疑的材料,或者很可能受到质疑的材料,以及所有的引文,都要具有可靠的、已发布的来源」,没有来源的材料应该被删除,或者使用「需要引用」的标记来提出质疑。
然而,决定哪些句子需要引用可能不是一项简单的任务。一方面,编辑者被强烈要求避免为很明显的或者常识性的信息添加引用——例如「天空是蓝色的」。另一方面,有时候天空并不一定是蓝色的——所以或许我们还是需要一个引用?
将这个问题扩大到整个百科全书的规模可能会变得难以应付。维基百科编辑者的专业知识很有价值,但他们的时间却是有限的,那么他们的引用工作应该集中在哪些类型的事实、文章和主题上呢?此外,最近的统计表明,相当一部分比例的文章只有很少的参考文献,英文维基百科中四分之一的文章根本就没有任何参考文献。这意味着,有大约 35 万篇文章包含一个或多个需要添加引用的标记,而且我们可能遗漏了更多。
我们最近设计了一个框架,帮助编辑者在维基百科中识别哪些句子需要引用,并且确定需要引用的优先顺序。通过针对英语、意大利语和法语维基百科的编辑者们开展的一项大型研究,我们首先确定了维基百科文章中单个句子需要引用的共同原因。然后我们使用这项研究的结果来训练一个机器学习模型分类器,它能够预测英语维基百科中任何一个给定的句子是否需要一个引用,以及为何需要引用。这个模型将在 3 个月内部署到其他语言的版本中。
通过识别维基百科获取信息的位置,我们能开发系统,以支持志愿者驱动的验证和事实检查,从而有可能提升维基百科的长期可靠性,抵御信息偏差、信息质量的差距以及虚假宣传。
我们为何要引用?
为了教会机器如何识别不经验证的陈述,我们首先要将句子需要引用的原因进行系统的分类。
我们首先检查了与英语、意大利语和法语维基百科中与可验证性相关的政策和指南,并尝试特征化这些政策中的标准,即是否添加引用的标准。为了验证和丰富实践的集合,我们要求来自于这三个语言社区的 36 名维基百科编辑者参与试点实验。我们使用 WikiLabels 收集了编辑者们对维基百科文章中句子的反馈:编辑者要决定一个句子是否需要引用,并且以自由形式的文本给出他们的理由。
我们的方法,以及最终关于是否需要添加引用的理由可以在项目网页中看到:
地址:https://meta.wikimedia.org/wiki/Research_talk:Identification_of_Unsourced_Statements/Labeling_Pilot

添加引用的理由

不添加引用的理由
教机器学习引用
接下来,我们训练机器学习模型来发现需要引用的句子,并提供对应的理由。
我们首先训练一个模型,从整个编辑者社区中学习如何识别需要引用的句子。我们创建了一个英语维基百科的「精选文章」数据集,这是一个高质量的文章选集,每一篇都引用了很多文章。精选文章中包含内联引用的句子被标记为正例,没有内联引用的句子被标记为负例。使用这些数据,我们基于句子中的词序列训练了一个 RNN 分类模型,它能够预测一个句子为正例(需要引用)还是负例(不需要引用)。最终模型对正例的分类准确率高达 90%。
解释算法预测
那么为什么模型具有高达 90% 的准确率呢?在决定句子是否需要引用的时候,算法是什么样子的呢?
为了解释这些结果,我们对需要引用的句子进行了采样,并且将模型考虑最多的单词进行了高亮标注。例如,在陈述「opinion」的例子中,模型将最高的权重给了「claimed,宣称」一词。在「statistics,统计」这项引用原因中,对模型最重要的单词是分析数值时最常用的动词。在「scientific,科学」引用原因的例子中,模型将更多的注意力给了领域专用的单词,例如「quantum,量子」。

模型认为需要引用的句子样本,关键单词高亮标注。
预测句子引用的原因
更进一步,我们希望模型提供引用原因的完整解释。我们首先使用 Amazon Mechanical Turk 设计了一个众包实验,用来收集引用的理由,并将其作为标注。我们从精选文章中随机抽取了 4000 个句子,让众包工作人员使用我们在之前的研究中识别出的八个原因进行标注。我们发现,当句子与科学或历史事实相关,或者是直接、间接引语时,我们需要提供引用。
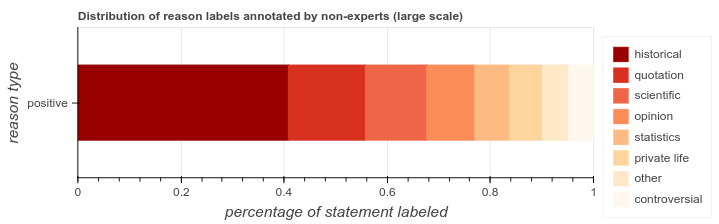
我们修改了在之前的研究中所用的神经网络,以便能够将无源的句子分类为 8 个引用原因类别中的一个。我们使用众包标记的数据集重新训练了这个网络,发现它在预测引用原因的时候达到了合理的准确率(精度 0.62),尤其是对于具有大量训练数据的类别。
后续步骤:预测跨语言和主题的「引用需要」
这个项目的下一个阶段将会涉及到修改我们的模型,以让它们能够为维基百科上的任何一种可用的语言进行训练。我们将会使用这些跨语言模型来量化维基百科不同版本中未经验证的内容的比例,并将引文的覆盖范围映射到不同的文章主题,以帮助编辑者识别那些非常需要添加高质量引用的地方。
我们计划尽快提供这些新模型的源代码。同时,您可以查看我们的研究论文「Citation Needed: A Taxonomy and Algorithmic Assessment of Wikipedia's Verifiability」,这篇论文最近被 The Web Conference 2019 接收,它的补充材料详细分析了引用政策以及我们用于模型训练的所有数据。

论文链接:https://arxiv.org/abs/1902.11116
论文补充材料:https://figshare.com/articles/Summaries_of_Policies_and_Rules_for_Adding_Citations_to_Wikipedia/7751027
数据:https://figshare.com/articles/%20Citation_Reason_Dataset/7756226
原文链接:https://wikimediafoundation.org/2019/04/03/can-machine-learning-uncover-wikipedias-missing-citation-needed-tags/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



