FastReID:一个面向学术界和工业界的 ReID Toolbox
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:l1aoxingyu
https://l1aoxingyu.github.io/blogpages/reid/2020/05/29/fastreid.html
本文已由原作者授权,不得擅自二次转载
引言
FastReID 平台已经成为京东人工智能研究(JD AI Research)的开源项目之一,它是面向学术界和工业界的落地项目,主要用于研究和商业落地。
先放上 Github 链接:
https://github.com/JDAI-CV/fast-reid
我们的 FastReID 也有一篇 paper 进行更加详细地介绍,如果想要了解更多关于 FastReID 的信息,可以直接去看原始 paper。

https://arxiv.org/abs/2006.02631
接下来会分享开发 FastReID 初衷以及 FastReID 的特点。
动机
最早的时候和罗博 @罗浩.ZJU 搞了一个 reid strong baseline,不过那个项目在 pytorch 的基础上,又用 ignite 包了一下,开源之后很多人都说 ignite 比较影响使用体验,所以后面在我自己维护的 baseline 版本里面就去掉了 ignite。
我们自己做项目,以及实习生做研究都是基于 strong baseline 去魔改的,后面发现各自搞的 project 和原始的 baseline 差别越来越大,导致我们想要在实际场景中运用研究工作时效果不好,遇到了很多代码不对齐的现象。出现这个问题原因在于其中一个同学修改了某一个训练逻辑或者预处理的地方,他自己忘记了,最终发现把模型合并在一起的效果总是不好,需要花很多时间去解决这些琐碎的问题。
正是由于这个原因,我们决定把 baseline 这套框架封成一个库,大家基于这套库去做工作就更利于找到各自定制化的地方。开源社区中也有几个比较流行的 reid 库,比如 torchreid,Person_reID_baseline_pytorch 等等,都是很好的库,值得我们去学习。最近 Facebook AI Researck 开源了 Detectron2 项目,它里面的整体概念和设计哲学都非常棒,所以我们决定参考 detectron2 的设计来整个 FastReID 架构。基于 FastReID,我们的产品模型和 research 的模型有了比较好的兼容性,同时也比较容易去 customize 一些功能,模块化的设计允许研究人员能自定义地插入自己想要的模块。
我们构建 FastReID 的目的在于满足 JD AI Research 的研究需求,能够快速地准备地实现一些 ideas,并且能够将研究员的研究成果快速地部署到工业实践中。无论在学术界还是工业界,开源项目都有助于整个社区的快速发展,使我们的想法快速付诸于实际落地项目中。我们也希望 FastReID 的发布能够继续加速行人重识别领域的发展。
一些新特性
FastReID 采用高度模块化设计,它具有更高的灵活性和可扩展性,能够在支持多 GPU 训练,它的扩展性设计使其在重构代码的情况快速实现很多研究项目。
下面我们介绍一下其中的一些新特性。
1.基于 FastReID,我们在多个 ReID 任务都获得非常不错的性能,并且用于业务线中,包括行人 ReID、Occluded/Partial 行人 ReID、跨域行人 ReID 和车辆 ReID。
虽然在 ReID 发展的这几年里面,有了很多 ReID 的 paper,大家的刷的点也越来越高了,但是性能好且稳定的方法其实还是基于最简单的 global feature 和分块的 local feature,其他使用额外信息如 pose,mask,parsing 之类的方法在实际使用中都不够稳定,同时也比较笨重。
所以我们在 FastReID 中内置了这两种方法,一种是基于 global feature 的 strong baseline,一种是基于分块的 MGN。然后在 BagofTricks 的基础上,将其他可能有用的 tricks 都实现了一下,包括有效的,比如 circle loss,gem pooling 之类的,也有没有效果的,比如 SWA, AugMix 等等。最终基于 ResNet50-ibn backbone,在三个数据库上实现了下面的性能

在 Marekt1501 上面提升空间已经不大了,因为后面有一些错误标签,但是在 DukeMTMC 和 MSMT17 上还是有比较显著的提升,详情可以去 model zoo 里面查看完整的配置文件。
在 partial re-id 上,我们也基于之前 DSR 的工作,在三个 partial 库上有了持续的提升

具体可以去 projects/PartialReID 中查看代码和训练配置。
在 cross-domain reid 上面,我们也做了一些工作,正在投稿中,之后会在开源在projects/Cross-domain-reid 中,从效果上看,在跨域上已经大大缩小了和有监督 reid 的差距。

在实际场景中我们发现穿黑衣服的人是一个比较难的问题,所以我们也基于 FastReID 构建了头肩模块去解决黑衣人的问题,也实现了比较不错的性能提升,paper 正在投稿,后面会开源在 projects/HAA 中。

在 vehicle re-id 上,我们也在 VeRI 数据集上跑了一下 baseline,得到了一个比较不错的结果,另外两个数据集 VehicleID 和 VERI-Wild 上也跑了一下,具体可以去 model zoo 里面查看。

另外还有一些基于 FastReID 做的工作都在投稿中,就不详细介绍了,后续都会开源在 fast-reid/projects 里面。
2.在模型评估上我们实现了更多的功能,比如我们支持比较灵活的测试方式,通过下面的命令可以实现在 Market1501 和 MSMT17 上联合训练,然后在 Market1501 和 DukeMTMC 上进行测试。
DATASETS:NAMES:("Market1501","MSMT17",)TESTS:("Market1501","DukeMTMC",)另外也提供了更加丰富的指标评估,除了 reid 中最为常见的 CMC 和 mAP,以及在 reid-survey 中提出的 mINP之外,我们还提供了 ROC 曲线和分布图
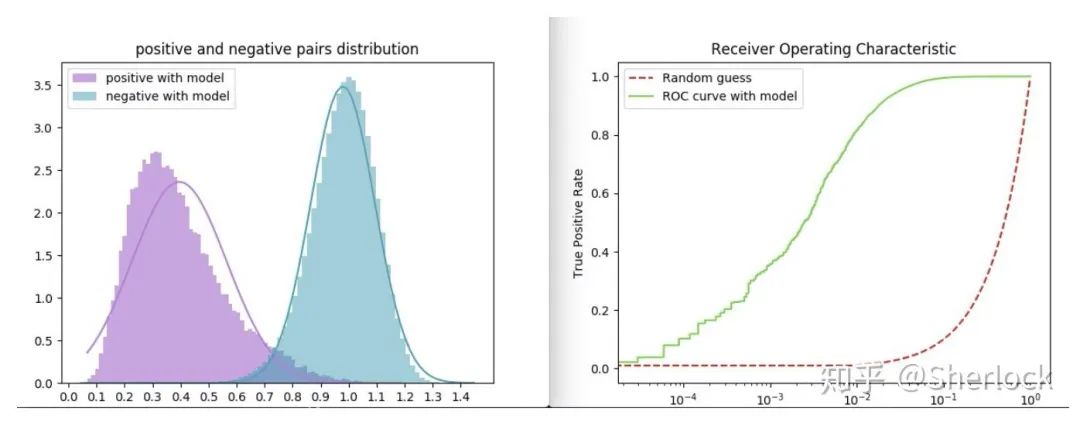
因为我们发现在实际业务场景中往往是开集测试,甚至 gallery 都是在动态变化的,在这种情况下通过单一的 rank1 或者是 mAP 来评估模型就不那么准确了,在实际应用时往往需要卡阈值再出 topK,所以通过分布和 ROC 曲线可以更好地帮我们找到阈值。
除了评估指标,可视化其实非常重要,通过可视化 rank list 可以快速定位模型的问题,同时也会发现一些错误标注,比如通过可视化我们发现 Market1501 里面有一些错误标注,最高的 rank@1 就只能做到 96 左右,而一些公司的 PR 文可以做到 99,我也不知道他们是怎么做到把标注错误都搞定的 !?(・_・;?。
我们发现很多库都只是实现了最基本的可视化功能,比如可视化 rank list,但是这种单一的可视化其实并不能帮助我们从多个维度了解问题,所以我们实现了更好的可视化功能。首先可以根据每个 query 的 AP 进行排序展示,比如 AP 从小到大进行展示,那么可视化出来的第一张图片就是 AP 最低的 query,通过这个方式我们可以了解到模型处理能力最差的 bad case。
另外我们在看预测结果的时候,其实也会想知道到底这个 query 的标注是怎么样的图片,比如我们再看 duke 数据集中下面的 rank list 时,发现他的 AP 是0,下面的蓝色框表示都是错误的匹配。

这时我们就会疑惑,到底这张 query 的标注长什么样,这时如果我们像下面这样将 label 同时可视化出来,我们就可以快速地知道,原来 query 其实是黄衣服后面那个黑衣服的人,因为是用 tracking 算法标注的,他大部分都被前面穿黄衣服的人挡住了,所以模型无法找对,而且这种情况下搞模型结构很难解决的,在实际业务中直接从源头上选择质量好的 query 是一个更好的解决方案。

3.大多数的库都只关注学术界做 research,我们更希望能够产学研结合,research 中 work 的东西能够快速到实际场景中去验证效果,发现实际中真正需要解决的问题。当然在实际研究中可以天马行空去写代码,但是这份代码无法快速地在实际场景中去验证,如果基于 FastReID 去重构和开发,那么我们就能够找到新方法所需要的最小代码实现,就能够很轻易地移植到实际业务中,也不用把大量的时间花在对齐训练逻辑以及预处理上了。
另外就是如何将 pytorch 训练的模型更容易地部署到生产环境上,这也是工业界比较关心的事情,python 写的模型如果没有优化和加速的话,在实际中是很慢的。为了更好地在工业界中应用,我们会在 FastReID 中加上一些脚本能够容易地将 pytorch 训练的模型转到 caffe 和 TensorRT 上,最后做一下模型的量化。目前 pytorch 升级到 1.3 之后慢慢开始支持量化了,我们也会尝试在 pytorch 端直接做量化,和蒸馏小模型。不过这些部分的内容还在整理和开发中,目前还没有 ready。
未来的一些改进方向
上面说了 FastReID 中的一些新特性,同时还有一些地方需要继续改进。
目前的多卡训练还是基于 DataParallel 来实现的,会存在负载不均衡,速度损失以及无法实现多机的缺点,我们正在用 DistributedDataParallel 来替换 DataParallel。
模型转换,量化和蒸馏小模型等部分的代码还没有搞定,后续会慢慢开源一部分。
可能会考虑将 FastReID 推广到通用的 image retrieval 上。
结语
科技的进步是整个社区的努力,包括学术界和工业界。个人的努力永远赶不上整个社区的努力,这也是开源 FastReID 的初衷。我们一直主张共享代码,快速试验新的想法,通过 FastReID 的发布加速整个 ReID 的产业化落地。我们也会继续发展和完善FastReID。希望大家能够 star/fork/watch/pr,大家互相学习,共同推动计算机视觉的发展。
在此感谢 JD AI 组的同事和老师的支持,正是因为大家的努力让 FastReID 变得更好,并且科研项目也都在 FastReID 上取得了很好的性能。
[1] Luo, Hao and Gu, Youzhi and Liao, Xingyu and Lai, Shenqi and Jiang, Wei. Bag of Tricks and a Strong Baseline for Deep Person Re-Identification.
[2] Wang, G. and Yuan, Y. and Chen, X. and Li, J. and Zhou, X. Learning Discriminative Features with Multiple Granularities for Person Re-Identification.
[3] Ye, Mang and Shen, Jianbing and Lin, Gaojie and Xiang, Tao and Shao, Ling and Hoi, Steven C. H.Deep Learning for Person Re-identification: A Survey and Outlook.
[4] Y. Sun, C. Cheng, Y. Zhang, C. Zhang, L. Zheng, Z. Wang, Y. Wei. Circle Loss: A Unified Perspective of Pair Similarity Optimization.
重磅!CVer-ReID 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-Re-ID 微信交流群,目前已汇集300+人!含众多技术大佬,互相交流,一起进步!
同时也可申请加入CVer大群和其他细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
请给CVer一个在看!




