![]()
阿里妹导读:阿里主搜(淘宝天猫搜索)是搜索离线平台非常重要的一个业务,具有数据量大、一对多的表很多、源表的总数多和热点数据等特性。对于将主搜这种逻辑复杂的大数据量应用迁移到搜索离线平台总是不缺少性能的挑战,搜索离线平台经过哪些优化最终实现全量高吞吐、增量低延迟的呢?
作者简介:王伟骏,花名鸿历,阿里巴巴搜
索推荐事业部高级开发工程
师。
2016年硕士毕业于南京邮电大学。A
pache Hadoop && Flink && Eagle Contributor。目前负责阿里巴巴搜索离线平台Runtime层相关工作。
另外,陈华曦(昆仑)给了本文很多建议,文中部分图由李国鼎(石及)贡献。
前言
在阿里搜索工程体系中我们把搜索引擎、在线算分等ms级响应用户请求的服务称之为“在线”服务;
与之相对应的,将各种来源数据转换处理后送入搜索引擎等“在线”服务的系统统称为“离线”系统。
搜索离线平台
作为搜索引擎的数据提供方,是集团各业务接入搜索的必经之路,也是整个搜索链路上极为
重
要的一环,离线产出数据的质量和速度直接影响到下游业务的用户体验。
搜索离线平台经过多年沉淀,不仅承载了集团内大量搜索业务,在云上也有不少弹外客户,随着平台功能的丰富,Blink(阿里内部版本的Flink) 版本的领先。我们在2019年年初开始计划把主搜(淘宝天猫搜索)迁移到搜索离线平台上。
主搜在迁移搜索离线平台之前的架构具有架构老化、Blink版本低、运维困难、计算框架不统一等不少缺点,随着老主搜人员流失以及运维难度与日俱增,重构工作早已迫上眉睫。
对于将主搜这种逻辑复杂的X亿数据量级应用迁移到搜索离线平台总是不缺少性能的挑战,业务特点与性能要求决定了主搜上平台的过程中每一步都会很艰辛。为了让性能达到要求,我们几乎对每个Blink Job都进行了单独调优,最初的理想与最后的结局都是美好的,但过程却是极其曲折的,本文将主要介绍主搜在迁移搜索离线平台过程中在性能调优方面具体做了哪些尝试。
主搜迁移搜索离线平台的完成对于平台来说有里程碑式的意义,代表搜索离线平台有能力承接超大型业务。
搜索离线平台基本概念
搜索离线平台处理一次主搜全增量主要由同步层和数据处理层组成,它们又分别包括全量和增量流程。为了读者更好理解下文,先简单介绍几个关于搜索离线平台的基本概念。
集团内支撑业务
目前搜索离线平台在集团内支持了包括主搜,AE在内的几百个业务。其中数据量最大的为淘宝天猫评价业务,数据量达到了X百亿条,每条数据近上X个字段。
场景
处理用户的数据源(mysql或odps)表,将数据经过一系列的离线处理流程,最终导入到Ha3在线搜索引擎或ES中。
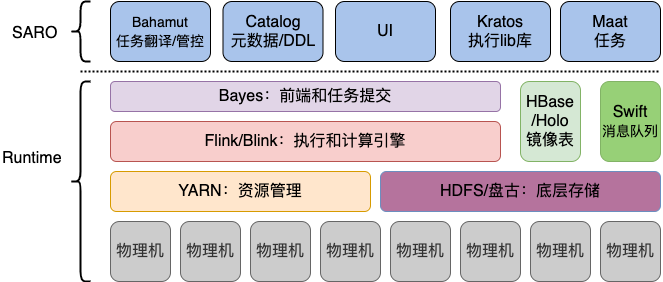
平台相关技术栈
如下图,搜索离线平台目前数据存储基于HDFS/盘古,资源调度依赖于YARN或Hippo,计算框架统一用Flink/Blink执行。
全量
全量是指将搜索业务数据全部重新处理生成,并传送给在线引擎,一般是每天一次。
这么做有两个原因:有业务数据是Daily更新;引擎需要全量数据来高效的进行索引整理和预处理,提高在线服务效率。全量主要分为同步层与数据处理层。
增量
增量是指将上游数据源实时发生的数据变化更新到在线引擎中。
这也就意味着在我们的场景中对于增量数据不需要保证Exactly Once语义,只需要保证At Least Once语义。基于该背景,我们才能用全链路异步化的思维来解一对多问题(下文会详细讲解)。
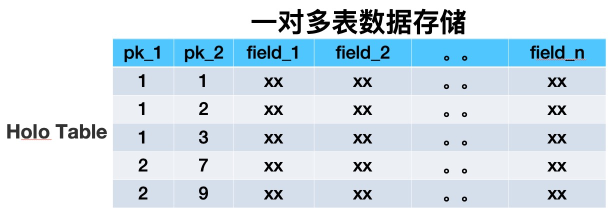
一对多
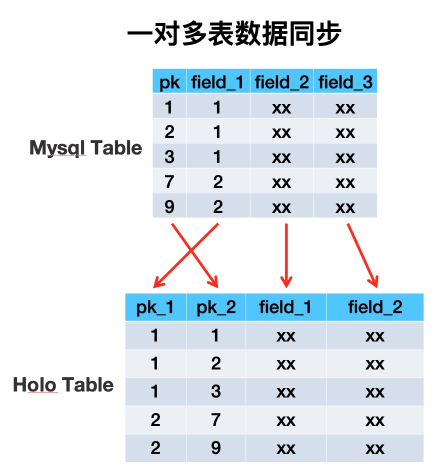
在搜索这个领域某些业务数据需要用一对多的形式来描述,比如商品宝贝和SKU的关系即是个典型的一对多数据的例子。在搜索离线基于Hologres(阿里巴巴自研分布式数据库)存储的架构中,一对多的数据存储在单独的一张双pk的HoloTable中,第一、二主键分别的宝贝ID与SKU_ID。
有了上面这些概念之后,在后续的段落中我们会看到搜索离线平台针对主搜各Blink Job的性能调优,先简要概括下主搜业务特点与性能要求。
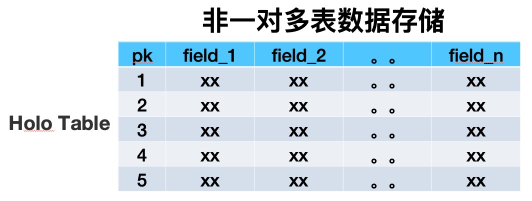
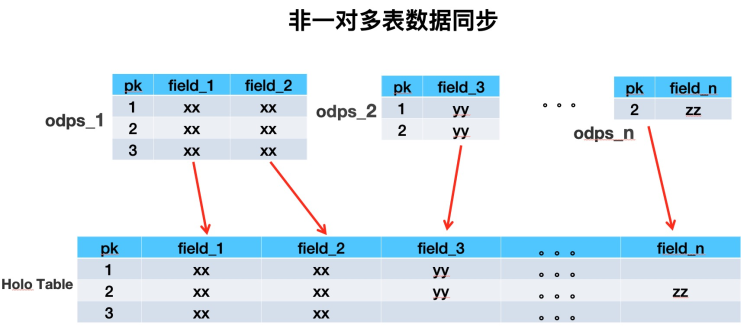
数据存储方式
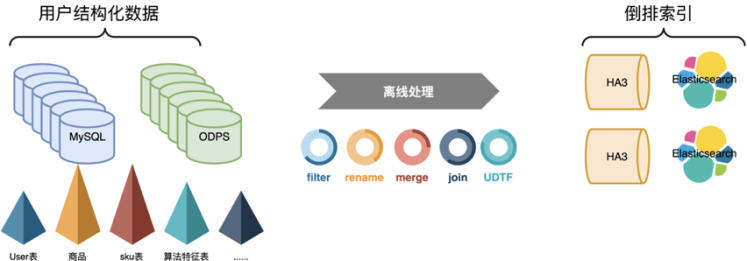
搜索离线平台以前用HBase做镜像表时,是用一张多列族大宽表来存储业务单维度所有数据。经过详细调研之后,我们决定用Hologres替换HBase,所以需要对存储架构做全面的重构。用多表来模拟HBase中的多列族,单HoloTable中包括很多业务数据源表的数据。重构后的数据存储方式大致如下:
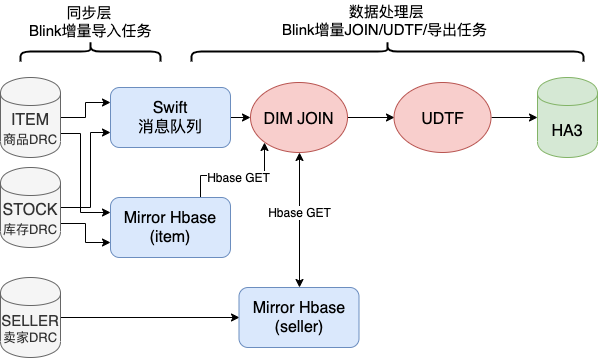
同步层
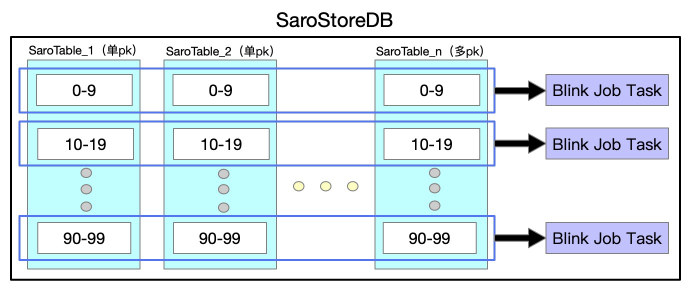
所谓同步层,一般是将上游数据源的数据同步到镜像表,供数据处理层高效处理。由于业务方单维度的数据有很多Mysql表或odps表组成,少则X张,多则像主搜这样X张。所以将同纬度数据聚合到一张Holo表中时,如果多张表两两join的话会产生大量shuffle,所以我们采取异步upsert方式,不同数据源表的数据写Holo表中不同的列来解决海量数据导入问题。
数据处理层
所谓数据处理层,是指将同步层得到的各镜像表(HBase/Holo)的数据进行计算,一般包括多表Join、UDTF等,以方便搜索业务的开发和接入。
主搜业务特点与性能要求
下面首先介绍下主搜业务特点与性能要求,再详细介绍我们进行了怎样的调优才达到了性能的要求。
主搜业务特点
★ 数据量大
主搜有X亿(有效的X亿)个商品,也就是主维度有X亿条数据,相比于平台其他业务(除淘宝评价业务)多出X个数量级。这么多数据我们能否在X个多小时完成全量?如何实现高吞吐?挑战非常大。
★ 一对多的表很多
主搜业务有很多一对多的表需要Join,例如一个商品对应多个SKU,部分商品对应了接近X个SKU信息。这些信息如何能够高性能的转换为商品维度,并与商品信息关联?
★ 源表的总数多
主搜有X多张表(包括一对多的表),平台其他业务的源表个数一般都在个位数。源表数量多会导致一系列的问题,比如读取ODPS数据时如何避免触发ODPS的限制?拉取大表数据时如何做到高吞吐?这些问题都需要我们一一解决。
★ 热点数据
主搜有一些大卖家(饿了么,盒马等)对应了很多商品,导致在数据处理层出现非常严重的数据倾斜等问题。如何解决大数据处理方向经常出现的SKEW?
主搜性能要求
★ 全量(同步层 + 数据处理层)高吞吐!
全量要求每天一次,在有限的资源情况下每次处理X亿的商品,这么大的数据量,如何实现高吞吐,挑战非常大!
★ 增量(同步层 + 数据处理层)低延迟!
增量要在Tps为X W的情况下达到秒级低延迟,并且双11期间有部分表(例如XX表)的Tps能达到X W,增量如何保证稳定的低延迟?值得思考!
下面一一描述我们是如何解决这些问题来达到性能要求的。
Blink Job性能调优详解
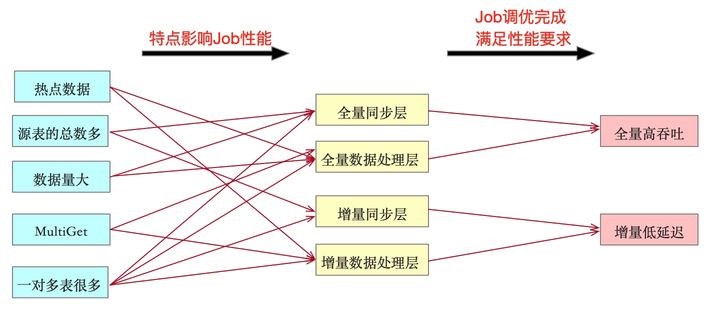
根据上述主搜业务特点与性能要求罗列出下图,左边与中间两列表示主搜哪些特点导致某阶段任务性能差。所以我们要对相应阶段Blink Job进行调优,调优完成也就代表着平台能满足图中最右边一列主搜所需要的全量高吞吐与增量低延迟的性能要求。
下面按照全量,增量,解一对多问题的脉络来给大家介绍我们是如何解决上述五个问题之后达到全量高吞吐以及增量低延迟的性能要求的。
全量高吞吐性能调优
全量主要包括同步层与数据处理层,必须实现高吞吐才能让全量在X个多小时之内完成。同步层在短时间内要同步约X张表中的上X亿全量数据,且不影响同时在运行的增量时效性是一个巨大的挑战。数据处理层要在短时间内处理X多亿条数据,Join很多张镜像表,以及UDTF处理,MultiGet等,最后产生全量HDFS文件,优化过程一度让人频临放弃。这里重点介绍数据处理层的性能调优历程。
该Job的调优历时较长,尝试方案较多,下面按照时间顺序讲解。
★ 初始形态
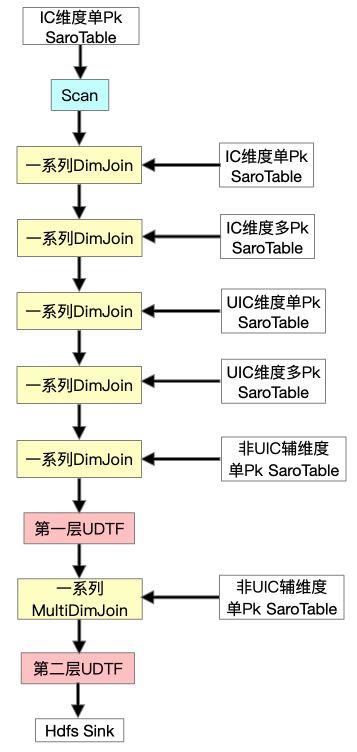
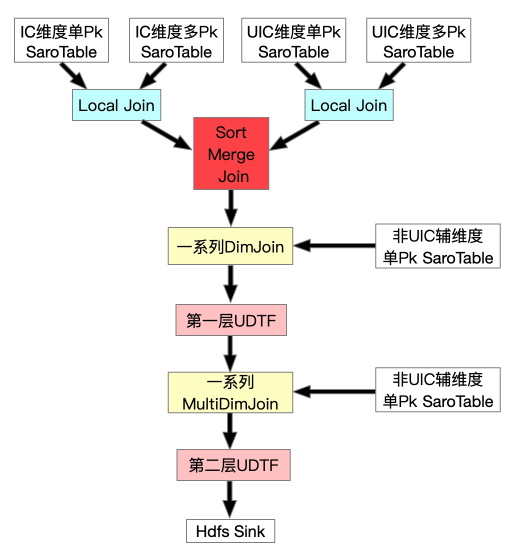
首先提一下IC维度为商品维度,UIC维度为卖家维度,并且最开始我们的方案是没有FullDynamicNestedAggregation和IncDynamicNestedAggregation的(后文会详细提到这两个Job)。Scan IC维度单Pk表之后做一系列的DImJoin、UDTF、MultiJoin。在测试过程中发现DimJoin多pk表(一对多表)的数据时,性能非常低下,全链路Async的流程退化成了Sync,原因是我们一对多的数据存在单独的一个SaroTable(对多个HoloTable的逻辑抽象)中,对指定第一pk来取对应所有数据用的是Partial Scan,这是完全Sync的,每Get一次都要创建一个Scanner,虽然我们不但对于DimJoin加了Cache,并且对于主搜特有的MultiGet也加了对于SubKey的精准Cache。但是测试下来发现,性能还是完全得不到满足,所以尝试继续优化。
★ 引入LocalJoin与SortMergeJoin
由于性能瓶颈是在DimJoin多pk的SaroTable这里,所以我们想办法把这部分去掉。由于一对多的SaroTable只有两个维度具有,所以我们尝试先分别将IC维度与UIC维度的所有表(包括单pk与多pk)进行LocalJoin,结果再进行SortMergeJoin,然后继续别的流程。
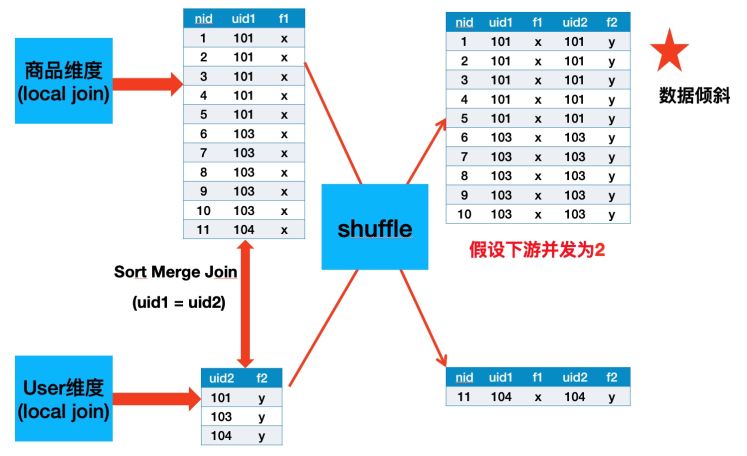
首先介绍下Local Join。由于HoloStore保证相同DB中所有表都是按照相同的Partition策略,并且都是按照主键字典序排好序的,所以我们可以将同纬度同Partition的数据拉取到一个进程中进行Join,避免了Shuffle,如下图所示。
经过测试,由于业务上面存在大卖家(一个卖家有很多商品),导致SortMergeJoin之后会有很严重的长尾,如下图所示,Uid为101与103的数据都是落到同一个并发中,我曾经尝试再这个基础之上再加一层PartitionBy nid打散,发现无济于事,因为SortMergeJoin的Sort阶段以及External Shuflle对于大数据量的Task需要多次进行Disk File Merge,所以该长尾Task还是需要很长时间才能Finish。
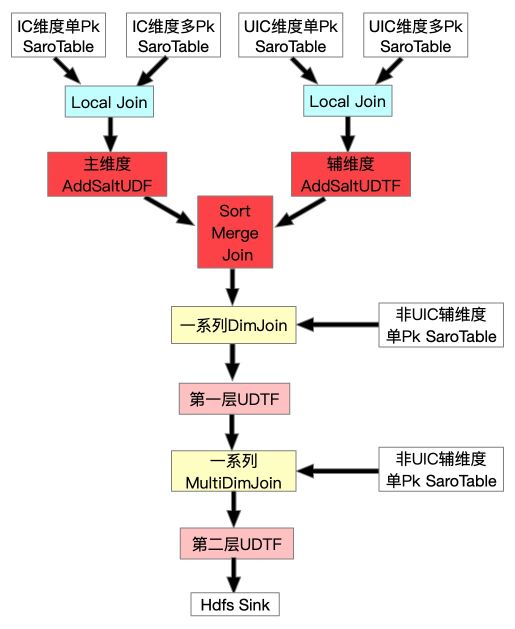
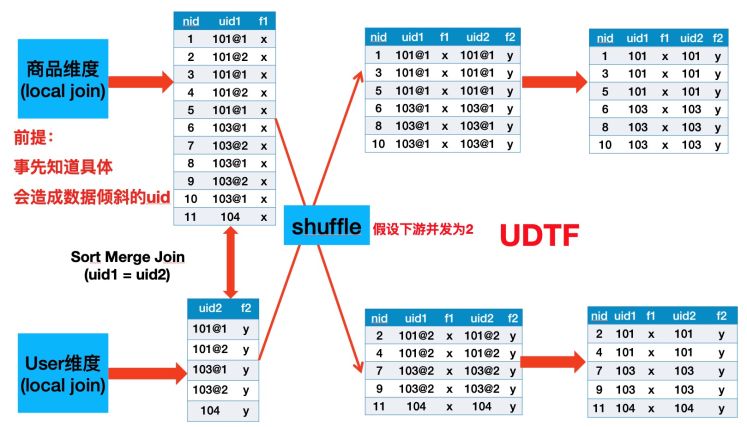
所以我们需要继续调优。经过组内讨论我们决定对大卖家进行加盐打散,从ODPS源表中找出Top X的大卖家ID,然后分别在主辅维度Scan + Local Join之后分别加上UDF与UDTF,具体流程图与原理示例见下面两幅图:
如上图所示,Uid为101与103的数据被打散到多个并发中了,并且因为我们在SortMergeJoin之后加了UDTF把加的Salt去掉,所以最终数据不会有任何影响。
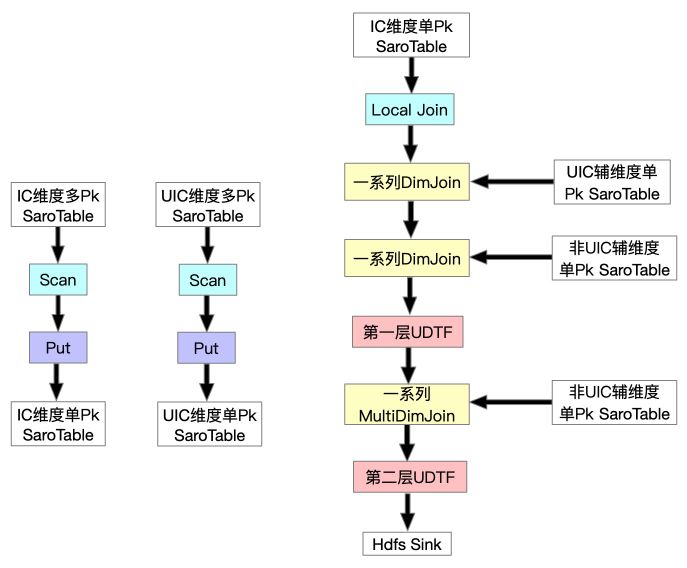
★ 最终形态
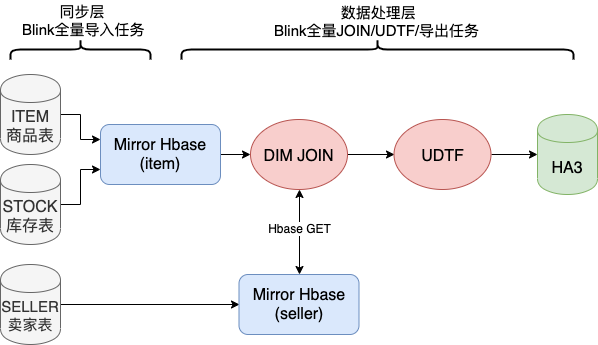
这样全量FullJoin总算完成了,并且性能也勉强达标,所以我们开始调整增量流程(IncJoin),这时发现IncJoin跟FullJoin的初始形态存在一样的问题,追增量非常慢,永远追不上,所以组内讨论之后决定在同步层针对全量新增一个FullDynamicNestedAggregation Job(下文会详细提到),这是一个Blink Batch Job它将各维度一对多的SaroTable数据写到对应维度的主表中,然后在FullJoin最开始Scan时一起Scan出来,这样就避免了DimJoin多pk的SaroTable。最终达到了全量高吞吐的要求,全量FullJoin最终形态如下:
增量性能主要受困于数据处理层IncJoin,该Job最开始是一个Blink Stream Job,主要是从SwiftQueue中读出增量消息再关联各个镜像表中的数据来补全字段,以及对数据进行UDTF处理等,最后将增量消息发往在线引擎SwiftQueue中。
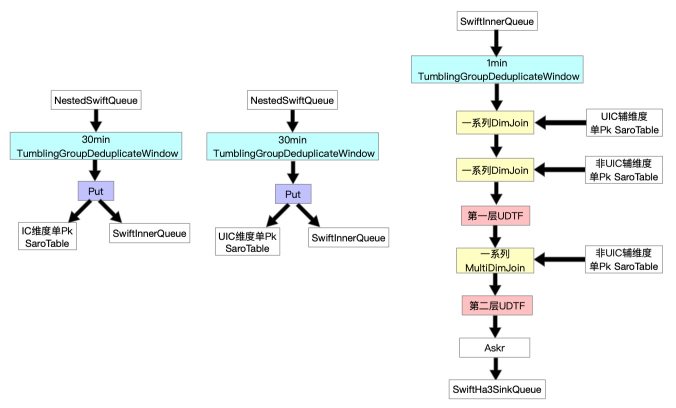
基于“流批一体”的思想,经过一系列尝试,我们增量数据处理层Job的最终形态如下。
与全量不同的是由于增量是实时更新的,所以更新记录不仅要写到Swift Queue中,还要写入SaroTable中。另外,我们根据业务特点给各个Job分别加了按pk对记录去重的window。
主搜有很多一对多的表,在数据处理层如何高效的将数据Get出来转换为主维度之后进行字段补全,困扰我们很久。
为了提升效率我们必须想办法提升Cpu利用率。所以Get记录改为全链路异步来实现,由于我们一对多数据存在多pk的HoloTable中,指定第一pk去获取相关数据在Holo服务端是以Scan来实现的。这样由于异步编程的传染性,全链路异步会退化为同步,性能完全不达标。
★ 解决方法
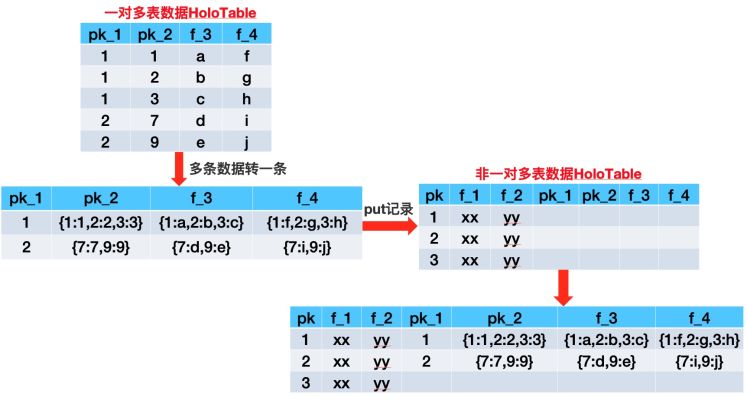
为了将“伪异步”变成真正的全链路异步,经过多次讨论与实践之后,我们决定将一对多表中相同第一pk的多条数据Scan出来GroupBy为一条数据,将每个字段转化为Json之后再Put进主表中,主要步骤如下图所示。
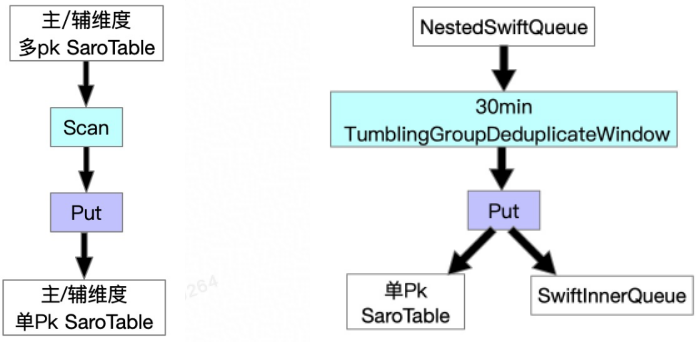
我们针对全量与增量在同步层加Job来解决,分别为FullDynamicNestedAggregation(Blink Batch Job)与IncDynamicNestedAggregation(Blink Stream Job),这两个Job大致流程为如下图所示。
![]()
值得一提的是,正如前文介绍增量时提到的背景,我们的场景中对于增量数据不需要保证Exactly Once语义,只需要保证At Least Once语义。所以基于该背景,我们能够将数据处理层增量Job拆分为两个Job执行,一对多的问题得以解决。
这样我们在数据处理层就不需要去Scan HoloTable了,从而可以用全链路异步化的方式来提升增量整体性能。
★ 截断优化
为了避免将多条数据转为一条数据之后由于数据量过大导致FullGC的“大行”问题。基于业务的特性,我们对于每个一对多表在Scan时支持截断功能,对于相同的第一pk记录,只Scan一定条数的记录出来组装为Json,并且可以针对不同的表实现白名单配置。
★ 加过滤Window优化
针对业务的特点,一对多的很多表虽然可以接受一定时间的延迟,但是为了避免对离线系统以及在线BuildService造成太大的冲击,所以更新不能太多,所以我们加了30min的去重窗口,这个窗口作用非常大,平均去重率高达X%以上。
结语
经过一
系列优化,主搜不仅在资源上相对于老架构有不少的节省,而且同时实现全量高吞吐与增量低延迟,并且在2019年度双11 0点应对突增流量时表现的游刃有余。
对系统进行性能调优是极其复杂且较精细的工作,非常具有技术挑战性。不仅需要对所选用技术工具(Flink/Blink)熟悉,而且对于业务也必须了解。加window,截断优化,加盐打散大卖家等正是因为业务场景能容忍这些方法所带来的相应缺点才能做的。
除了本文提到的调优经验,我们对同步层全增量Job与MultiGet也进行了不少调优,篇幅原因与二八原则这里就不详细介绍了。
主搜成功迁移也使得搜索离线平台完成了最后一块拼图,成为阿里巴巴集团搜索中台以及核心链路的基础模块。
欢迎对Hadoop、Flink等大数据技术感兴趣的同学加盟我们。扫描下方二维码,或者点击文末
“阅读原文”
,即可进入岗位投递 link 。
![]()