赛尔原创 | 顺滑:让语音识别更流畅
作者:哈工大SCIR博士生 王少磊
1 前言
自动语音识别(ASR)得到的文本中,往往含有大量的不流畅现象。这些不流畅现象会对后面的自然语言理解任务(如句法分析,机器翻译等)造成严重的干扰,因为这些系统往往是在比较流畅且规范的文本上进行训练的。不流畅现象主要分为两部分,一部分是ASR系统本身识别错误造成的,另一部分是speaker话中自带的。NLP领域主要关注的是speaker话中自带的不流畅现象,ASR识别错误则属于语音识别研究的范畴。顺滑(disfluency detection)任务的目的就是要识别出speaker话中自带的不流畅现象。随着语音识别技术的不断普及,将会产生大量的含有不流畅现象的文本,顺滑任务的作用也会越来越突出。值得注意的是,由我实验室和科大讯飞公司合作的中文版本的顺滑系统已经率先上线了,相关的信息参见http://www.iflyrec.com/help/product.jsp。
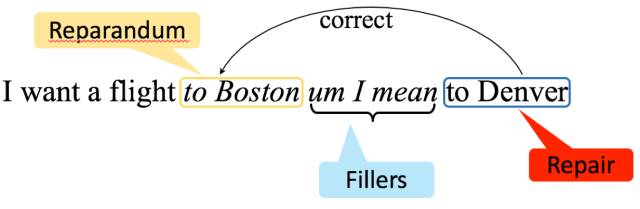
Speaker话中自带的不流畅现象主要分为两大类,分别为Filler类型和Edit类型。以英文为例,Filler类型主要包括“uh”、“oh”等语气词,以及“so”、“well”等话语标记语。Filler类型的一个特点是其对应的不流畅部分属于一个封闭的短语集合,因此,利用简单的规则或者机器学习模型就可以很好的识别Filler类型。Edit类型主要包括重复,以及被后面的短语所纠正的部分。图1是一个英文顺滑任务的示例。在例句中,“um”,“I mean”属于Filler类型,“to Boston”则属于Edit类型,其被后面的“to Denver”所纠正。Edit类型是顺滑任务中最难处理的类型,因为Edit类型的短语长度不固定,出现的位置比较灵活,甚至会出现嵌套的结构。因此,顺滑相关的研究主要集中Edit类型的处理上(后面的内容默认处理的是Edit类型)。对于顺滑任务,目前主要用到的语料是English Switchboard数据,在中文上还没有公开的语料。
图 1: 顺滑示例
对于顺滑任务,其主要有两个难点。一个是长距离依赖问题。这个问题可以从两方面来看:一方面Edit类型的短语块本身长度可能会很长,在English Switchboard数据中,最大的Edit块甚至包含15个词;另一方面,Edit类型和其对应的修正部分之间并不总是相邻,中间可能隔着很多的词。因此要判断一个词是不是Edit类型,需要看到较远距离的信息。另一个难点是要保证顺滑后的句子的句法完整性,如果一个句子的关键成分被误认为Edit类型,将会导致严重的后果。
2 方法介绍
对于顺滑任务,目前的研究方案大致可以归结为四类:序列标注方法、句法和顺滑联合方法、基于RNN的方法、基于seq-to-seq的方法。目前性能最好的是我们实现的基于RNN的方法和基于seq-to-seq的方法。
2.1 序列标注方法
用序列标注方法来解决顺滑问题的工作有很多,这类方法可以分为两大类。一类是基于词的方法。这类方法的做法是利用序列标注模型,给句子中每个词赋一个标签,最后根据标签来判断词的类型。比较有代表性的工作是(Qian and Liu, 2013)[1]采用Max-Margin Markov Networks的方法。另一类是基于块(chunk)的方法,这类方法的输出不再是与输入等长的标签序列,而是一个个带标签的短语块,这类方法的一个优点是可以利用块级别的特征,比较有代表性的工作是(Ferguson et al., 2015)[2]采用Semi-Markov Model的方法,实验证明,在顺滑任务上,其性能要高于其它基于词的序列标注方法。传统的序列标注模型通过设计复杂的离散特征,可以在一定程度上解决长距离依赖问题,但是受限于训练语料的规模,往往会面临稀疏性的问题。而且,这类方法没有能力保证生成的句子的句法合理性。
2.2 句法和顺滑联合方法
English Switchboard数据中包含同时标注了成分句法和顺滑的语料。在这些语料中,不流畅的短语被融入到整个成分句法树中,通过一个特的“EDITED”节点来识别。基于这些语料,一些工作尝试将句法分析和顺滑任务联合起来,先把标注好的成分句法转换成依存句法树,然后通过修改传统的基于转移的依存句法分析模型的转移动作,从而将顺滑任务融入到句法分析中去。以(Wu et al., 2015)[3]在ACL 2015年上的工作为例,其提出的binary classifier transition-based model(BCT)模型在标准的arc-standard转移动作基础上,增加了一个BCT动作,这个动作相当于一个二元分类器,用来判断在当前状态下,队列首部的词是否为不流畅词。基于这些新的转移规则,在依存句法分析过程中,对于每个状态,模型会先调用BCT分类器,如果分类器判定队列首部的词属于不流畅词,那么就赋予其不流畅标签,并将其压入栈中;否则,下一步就会执行原始的arc-standard转移动作。需要注意的是,一旦队列首部的词被识别为不流畅词并被压入栈中,模型在下一步会强制执行REDUCE动作,将其弹出栈,从而保证其不会干扰后续的句法分析。通过融合丰富的句法结构和顺滑相关的特征,联合模型能比较好的解决长距离依赖问题。由于联合模型最终的输出是一个去除不流畅部分的完整的句法树,其有一定的能力保证句子的句法完整性。相关的实验结果表明,在联合方法中,句法分析和顺滑任务确实能够相互促进。从技术角度来看,联合方法是一个不错的顺滑解决方案,但是其问题也是很明显的。一个主要问题是获得同时标注成分句法和顺滑的语料的代价是非常高的,这也降低了联合方法的实用性。另一个问题是,联合方法需要同时进行句法和顺滑分析,相对于序列标注等方法,其速度会比较慢。
2.3 基于RNN的方法
Recurrent Neural Network(RNN)是为了对序列数据进行建模而产生的,其在理论上能很好的解决长距离依赖问题,因此一些研究者尝试将RNN网络应用到顺滑任务中。LSTM(Long Short Term Memory networks)是一种特殊的RNN网络,它可以有效减轻简单RNN容易出现的梯度爆炸和梯度消散问题,我们的工作(Wang et al., 2016)[4]采用双向的LSTM来解决顺滑问题。从我们的实验结果看,直接用双向LSTM的隐层输出来对每个位置的词进行分类,判断其是否为不流畅词,其性能已经超越了之前最好的序列标注方法以及句法和顺滑联合方法。这种直接分类的方法没有考虑输出标签之间的联系,当输出标签之间存在强依赖性时,这种分类方案可能会导致 标签偏置(label bias)的问题。对于顺滑任务,一个不流畅块可能会包含连续的多个词,因此其输出标签之间会有很强的依赖性。为了解决标签偏置的问题,我们尝试采用LSTM-CRF模型。在LSTM-CRF模型中,首先通过双向LSTM学习到每个位置的特征表示,然后将学习到的特征表示直接送到一个线性CRF模型。从实验结果来看,LSTM-CRF模型的F1值要比LSTM高一个点左右。
神经网络方法的一个主要优点是其可以自动学习特征表示,但是一系列用神经网络方法来解决顺滑任务的工作表明,如果不在模型中融入人工特征,其在English Switchboard数据上是PK不过传统的非神经网络方法的。个人认为主要原因是顺滑任务相对于分词,词性标注等序列标注任务,本身更加复杂,English Switchboard训练数据只有八万句左右,而且含有不流畅部分的句子只占到一半左右,受限于语料规模,神经网络模型很难自动学出一个非常好的特征表示。因此,我们尝试在LSTM模型中加入简单的人工特征。具体做法是在每个位置,根据设计好的特征模板,抽取出对应的特征,并用一个对应维度的0-1向量来表示这些离散特征,最后将得到的特征向量和对应位置的词、词性的embedding等一块加放到输入层。表1列出了我们用到的人工特征,可以看到,相对于传统的采用丰富人工特征的序列标注和句法顺滑联合方法,我们采用的特征要少很多,而且,这些特征具有很好的通用性,在中文和英文上都取得了很好的实验效果。基于RNN的方法能很好的解决长距离依赖问题,但是其没有能力保证生成句子的句法完整性。

表 1: 神经网络方法用到的人工特征. p 表示词性. w 表示词. Duplicate表示两个元素是否相同.fuzzyMatch表示两个词的字面相似度.
2.4 基于seq-to-seq的方法
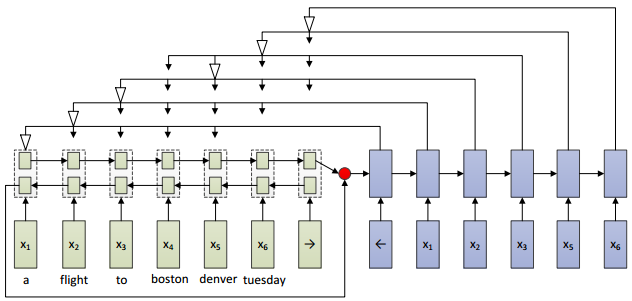
最近,我们发表在COLING 2016的工作(Wang et al., )[5]首次利用seq-to-seq的方法来解决顺滑问题。采用seq-to-seq方法主要有两个动机。一个是seq-to-seq框架在编码阶段会对输入句子学习一个全局的表示,该全局表示有助于解决长距离依赖问题,另一方面,seq-to-seq方法本身可以被看做一个基于条件的语言模型,原始的输入句子相当于语言模型的条件,解码阶段相当于一个语言模型的生成过程,这样就有一定得能力保证生成句子的句法完整性。顺滑任务要求删除不流畅部分后的句子必须是原始输入句子的有序子序列,这意味着生成的句子既不能额外增加一些原始输入句子中不存在的词,也不能改变词的顺序。传统的encode-decode框架显然不能满足顺滑任务的要求,总结起来,其主要有三个局限:一是其每步生成新词的时候,都会在一个固定的词表中去选择一个概率最大的词,这样就可能会生成一个不在原始句子中出现的词,二是其只能在固定的词表中去选词,如果原始句子中出现了一个不在词表中的词,那么这个词就肯定不会被生成,这明显是不符合顺滑任务要求的,最后一个原因是其无法保证生成词的有序性。为了突破传统的encode-decode框架的局限性,(Vinyals et al., 2015)[6]提出了pointer network,其解决了上面的三个局限中的前两个,但是没有能力保证生成词的有序性。我们的方法通过修改pointer network的解码过程,保证了生成词的有序性,从而能够被应用到顺滑问题中,其结构如图2所示。在编码阶段,用一个双向LSTM对句子进行编码,然后将得到的句子表示作为解码阶段单向LSTM的初始隐层输入。在解码阶段,每一步模型都会对输入句子的选定窗口内的词进行attention操作,然后将权重最大的词作为要生成的词,一旦一个词被选中,那么,窗口内位于该词前面的那些词都默认被删除掉,也就是被标注为不流畅词。下一步的窗口将从当前被选中的词的下一个位置的词开始,窗口的长度由训练语料中不流畅块的最大长度和输入句子中剩下的词的个数来决定。图2中的白色箭头代表的就是被选中的权重最大的词。这里只是简单的介绍了一下我们的模型,感兴趣的可以关注我们的文章。实验结果表明,该模型的性能和LSTM-CRF模型的性能接近。从模型本身来看,encode-decode框架能很好的解决长距离依赖问题,还有一定得能力保证生成句子的句法完整性,但是由于我们目前在训练和测试阶段都采用的是贪心搜索策略,一旦中间步骤选错了词,会对后面的步骤产生严重的影响,因此我们也正在尝试用柱搜索的方法来对模型进行优化。
图 2: attention-based network
3 实验结果及分析
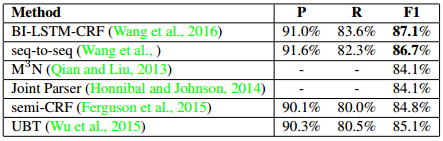
表2给出了各种方案目前的实验结果。从中可以看到,相比于之前的工作,我们的LSTM-CRF和基于seq-to-seq的方法取得了更好的实验结果。根据对实验结果的分析,我们发现目前的方法已经可以解决一些简单的不流畅现象,如简单的重复等。但是对于比较复杂的问题,如语义层面的重复,修正等,现有的基于数据驱动的模型还不能很好地解决,未来还有很大的探索空间。
表 2: 目前各种方法的性能比较
References
[1] Xian Qian and Yang Liu. 2013. Disfluency detection using multi-step stacked learning. In HLT-NAACL, pages 820–825.
[2] James Ferguson, Greg Durrett, and Dan Klein. 2015. Disfluency detection with a semimarkov model and prosodic features. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 257–262. Association for Computational Linguistics.
[3] Shuangzhi Wu, Dongdong Zhang, Ming Zhou, and Tiejun Zhao. 2015. Efficient disfluency detection with transition-based parsing. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 495–503. Association for Computational Linguistics.
[4] Shaolei Wang, Wanxiang Che, Yijia Liu, and Ting Liu. 2016. Enhancing neural disfluency detection with hand-crafted features. In China National Conference on Chinese Computational Linguistics, pages 336–347. Springer.
[5] Shaolei Wang, Wanxiang Che, and Ting Liu. A neural attention model for disfluency detection. In Proceedings of the 26th International Conference on Computational Linguistics (COLING 2016).
[6] Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. 2015. Pointer networks. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems 28, pages 2692–2700. Curran Associates, Inc.
本期责任编辑:郭江
本期编辑:施晓明
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏





