二阶梯度优化新崛起,超越 Adam,Transformer 只需一半迭代量
选自arXiv
作者:Rohan Anil等
机器之心编译
参与:思源、一鸣、杜伟
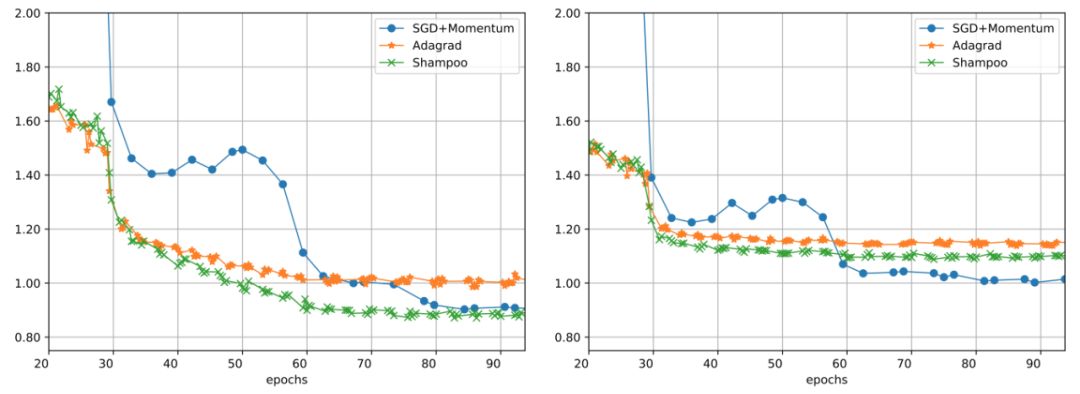
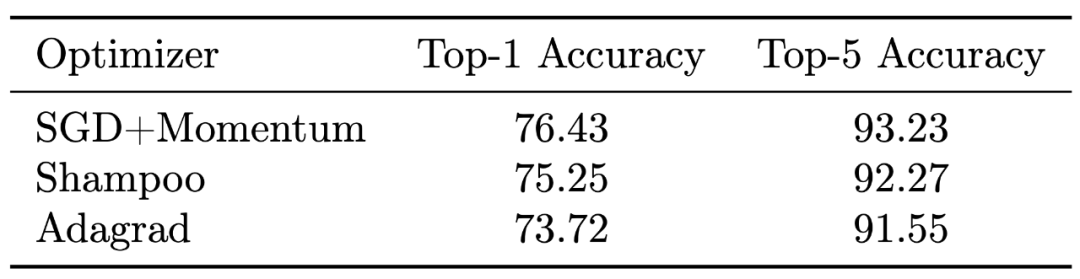
常见的最优化器,如 Adam、AdaGrad、SGD+Momentum 等,都是一阶的。但是二阶梯度的收敛速度相比它们就快了太多。近日,谷歌研究者联合普林斯顿大学等,提出了真正应用的二阶梯度最优化器 Shampoo,让这个理论上颇有前景的设想变为现实。

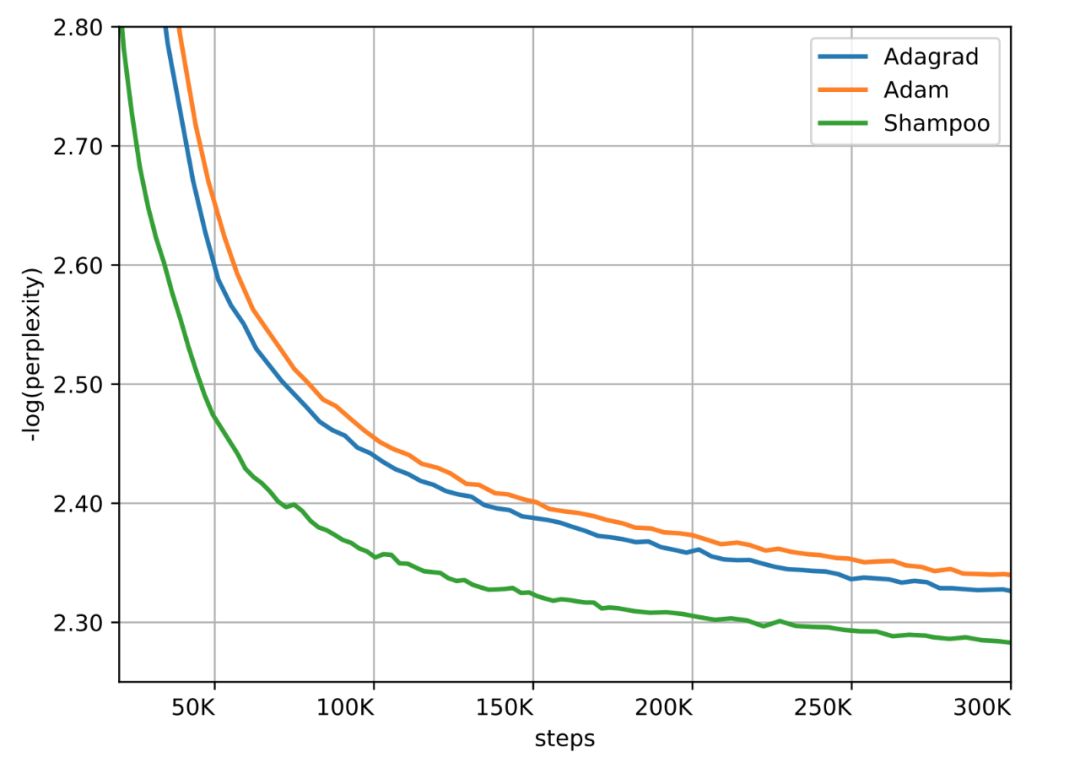
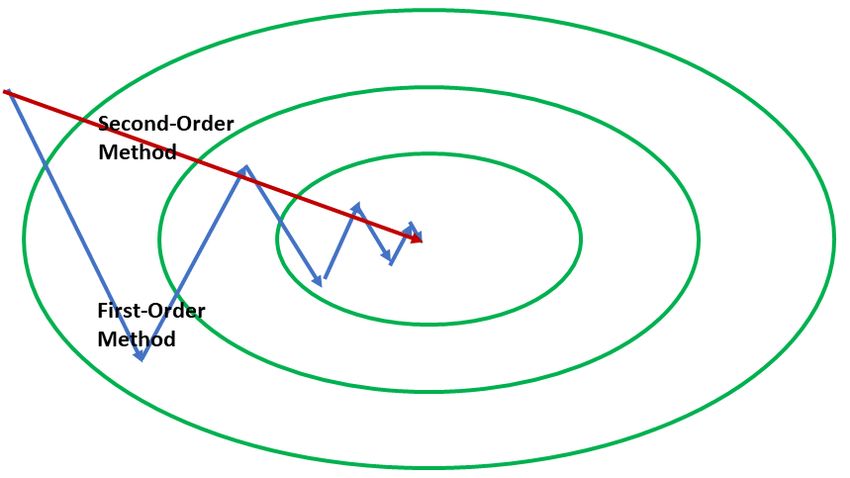
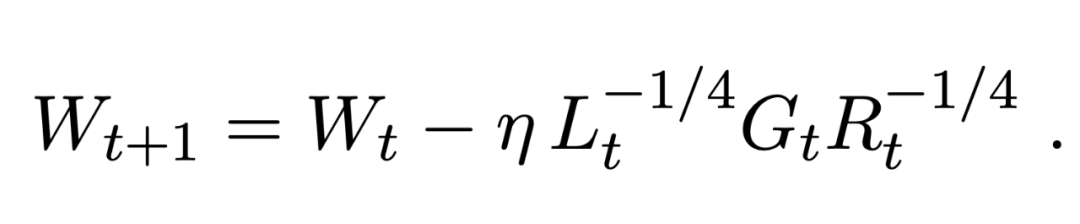
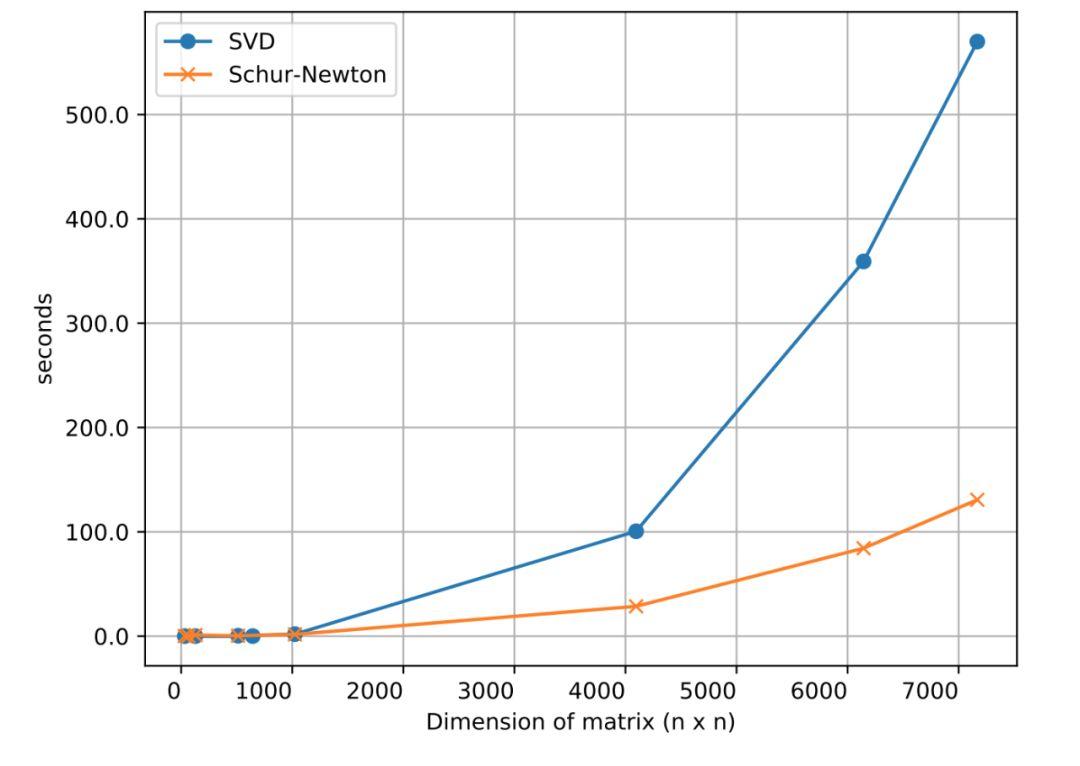
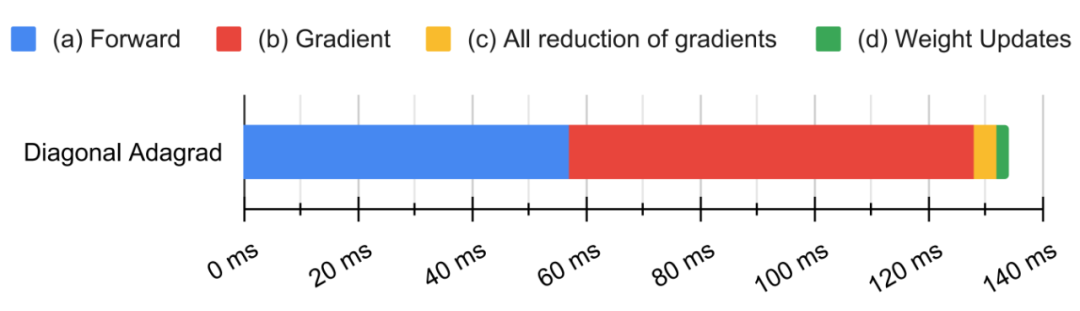
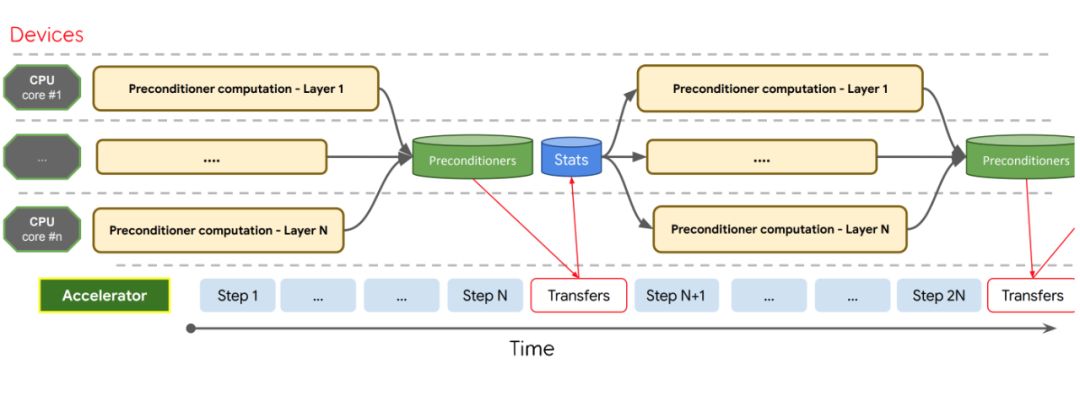
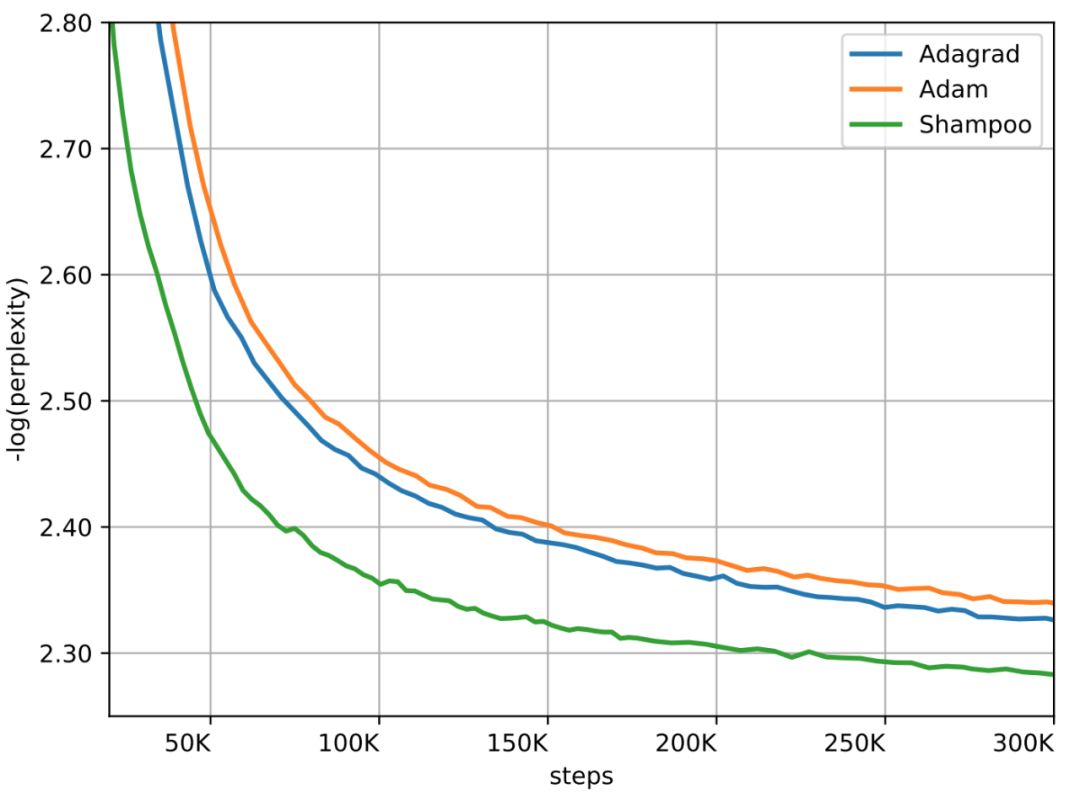
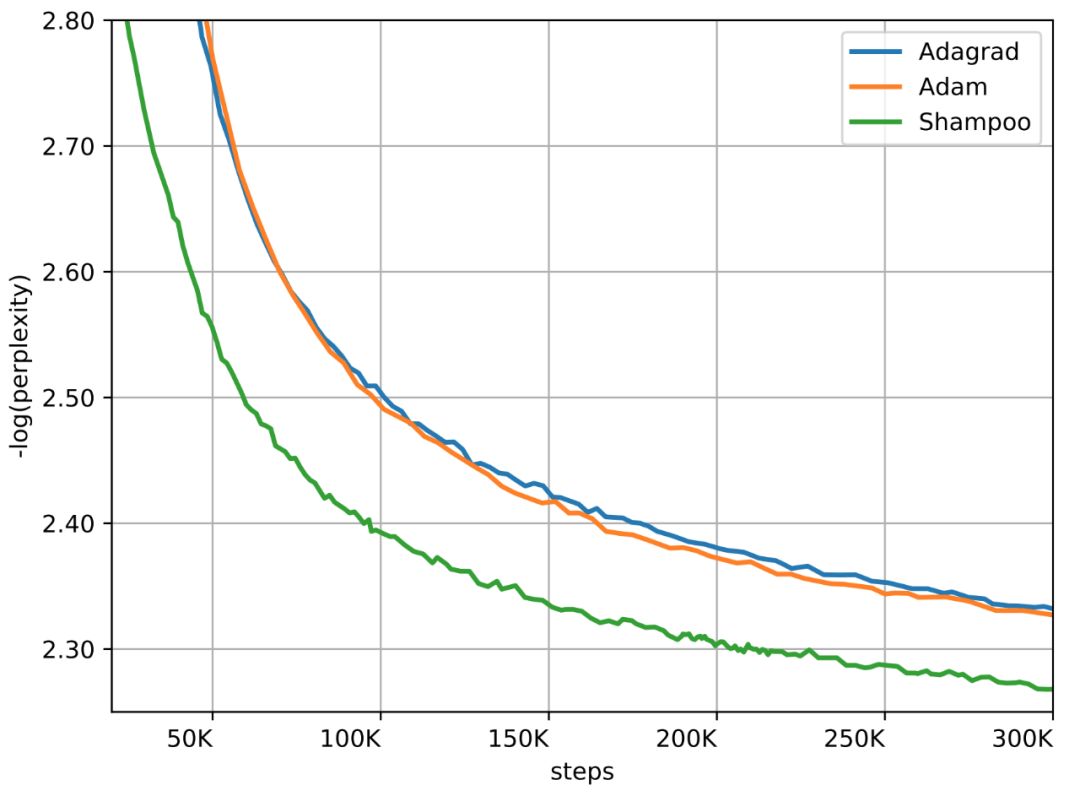
登录查看更多
相关内容
Arxiv
4+阅读 · 2019年4月15日
Arxiv
8+阅读 · 2018年11月21日



相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年4月15日
Arxiv
8+阅读 · 2018年11月21日