Github标星3400+!3.5M超超轻量中英文OCR模型开源,火了!
导读
先看下飞桨文字识别套件PaddleOCR自今年年中开源以来,短短几个月在GitHub上的表现:
7月,8.6M超轻量模型发布,GitHub Trending全球日榜榜单第一!
8月,开源CVPR 2020顶会SOTA算法,再上GitHub趋势榜单!
9月,GitHub Star数量已超过3.4K, 近期又带来哪些重磅更新?
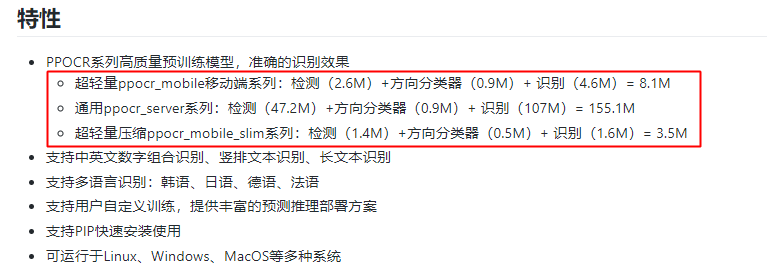
数量上,这次PaddleOCR一口气发布了三个系列模型,满足移动端、服务器端各种场景需求。而且,多语言也妥妥安排上了,全部训练代码和模型毫无保留开源。其中3.5M超轻量文字识别模型,堪称目前业界开源的最轻量OCR模型了。
质量上,如此轻量的模型,效果有保障吗?不看广告,直接看疗效。
先看几个常见的通用场景识别效果:



3.5M的模型能达到这个识别精度,绝对是良心之作了!
传送门:
快速体验PaddleOCR的
3.5M超轻量OCR模型
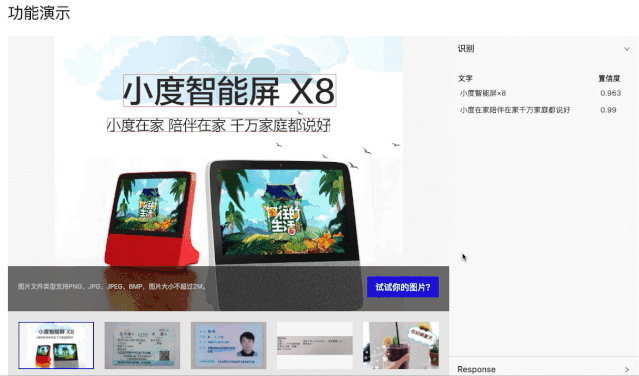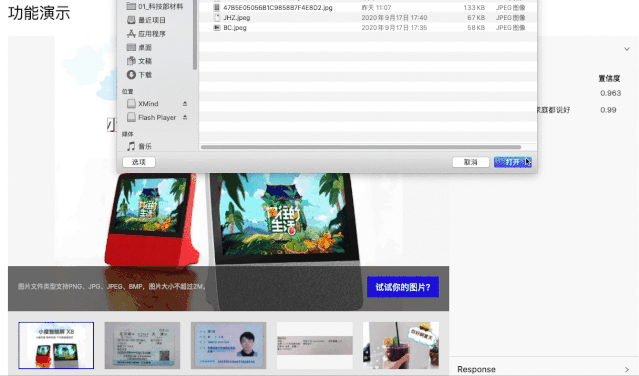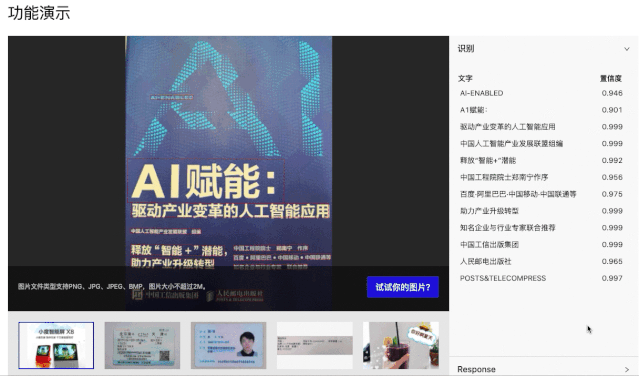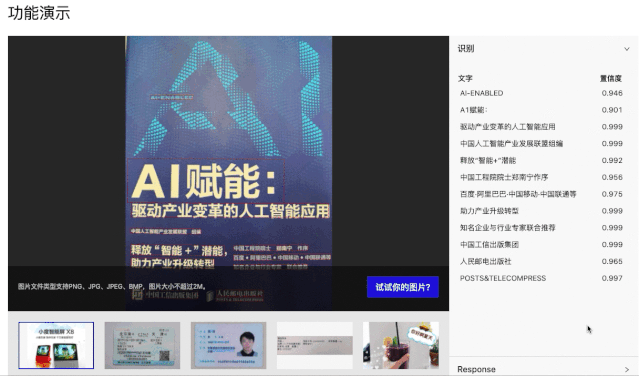
PC端快速尝试:(打开网页,选一张图片,即可实时看到结果)
手机端App安装体验
PaddleOCR在百度大脑EasyEdge上开放了文字识别APP demo。
示例效果如下(可以在github首页找到下载二维码):

多个开源repo测试对比
简单对比一下目前主流OCR方向开源repo的核心能力:
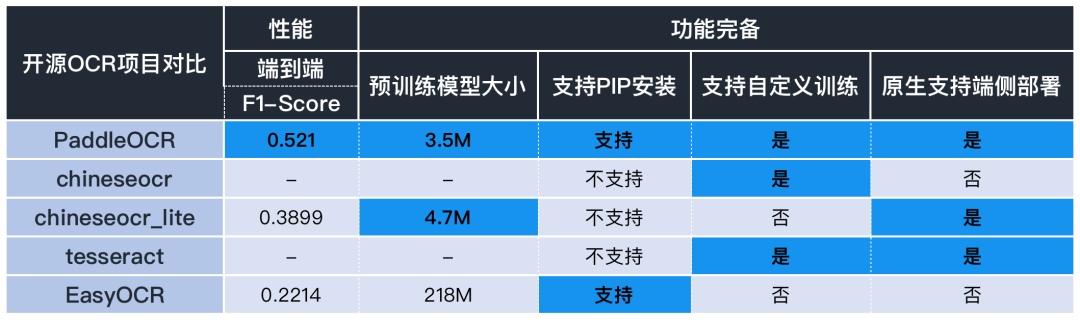
从性能指标来看:
针对OCR实际应用场景,包括合同,车牌,铭牌,火车票,化验单,表格,证书,街景文字,名片,数码显示屏等,收集的300张图像,每张图平均有17个文本框,PaddleOCR的F1-Score超过0.5,这个性能已经很不错了。
预训练模型大小:EasyOCR目前暂无超轻量模型,chineseocr_lite最新的模型是4.7M左右,而PaddleOCR提供的3.5M无疑是目前业界已知最轻量的。
PIP安装:目前仅PaddleOCR和EasyOCR支持。
自定义训练:实际业务场景中,预训练模型往往不能满足需求,对于自定义训练和模型Finetuning,目前只有PaddleOCR支持。
部署方面:EasyOCR模型较大不适合端侧部署,Chineseocr_lite和PaddleOCR都具备端侧部署能力。
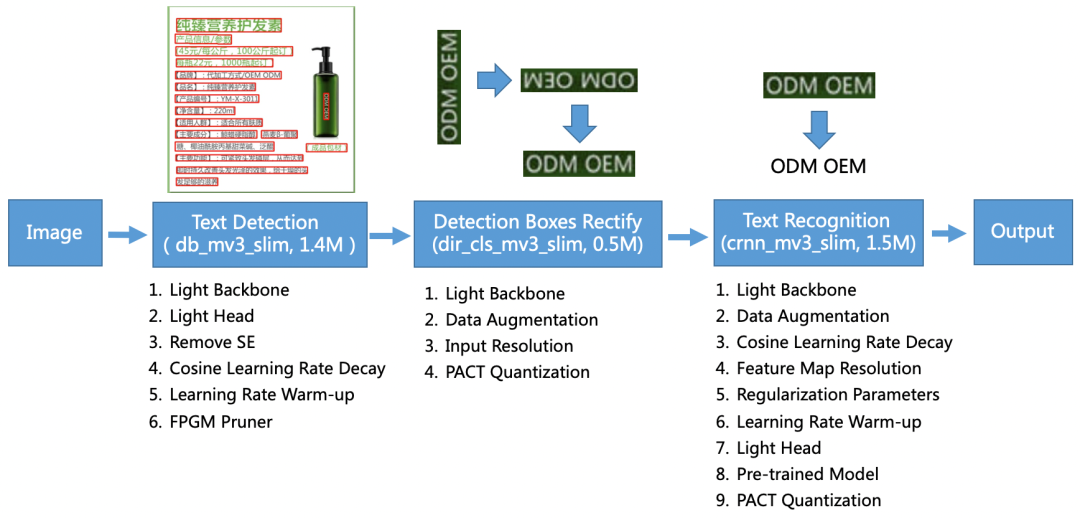

除了3.5M超轻量OCR模型,PaddleOCR提供了多语言预训练模型(英、德、法、韩、日),支持自定义训练和丰富的部署方式。
想了解更多。欢迎加入PaddleOCR技术交流群,第一时间获得技术支持。

招募活动预告





