谷歌最新抠图算法:让背景虚化细节到头发丝!有单反的感觉了...
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
当真是买算法送手机!
这不,谷歌又给“亲儿子”Pixel 6塞福利了,让手机抠图也能细节到头发丝。
看这效果,原本模糊的头发轮廓,咻地一下,就变成了纤毫毕现的样子!

连发丝之间的缝隙也能精准抠到。
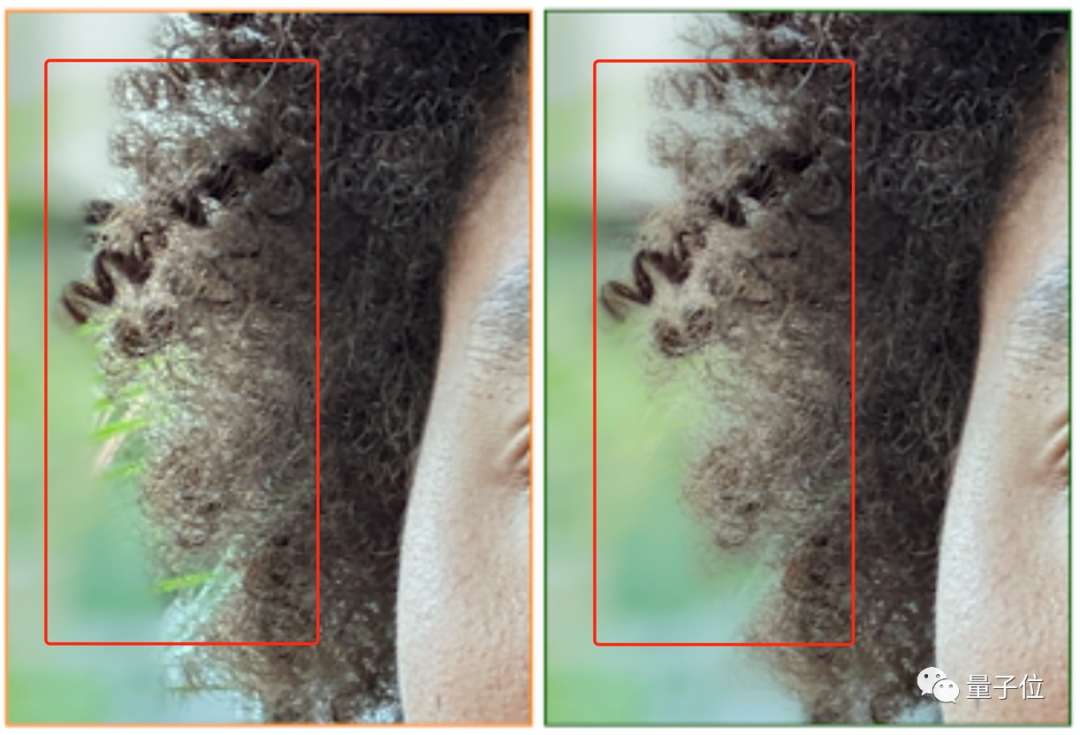
这样一来,就避免了使用人像模式拍照时人物与虚化背景割裂的情况,让人物照片的纵深感更加逼真。
四舍五入一下,这不就是手握单反拍照?(手动狗头)
Alpha遮罩+监督学习
在介绍最新的方法之前,先来了解一下过去手机的人像模式拍照到底是怎么实现的。
传统方法是使用二进制将图像分割,然后对分离出的背景进行虚化,在视觉上产生一种纵深感,由此也就能更加突出人物主体了。

虽然带来的视觉效果非常明显,但是在细节上的表现还不够强大。
由此,谷歌将常用于电影制作和摄影修图的Alpha遮罩搬到了手机上,提出了一个全新的神经网络,名叫“Portrait matting”。
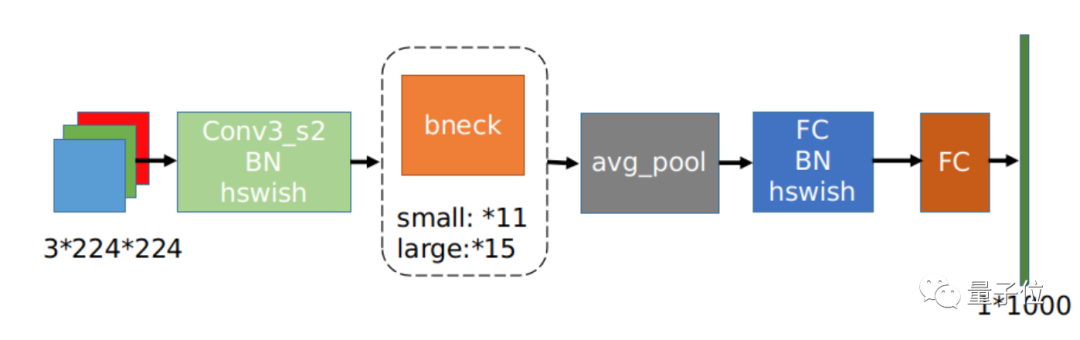
其中,主干网络是MobileNetV3。
这是一个轻量级网络,特点是参数少、计算量小、推理时间短,在OCR、YOLO v3等任务上非常常见,具体结构长这样:
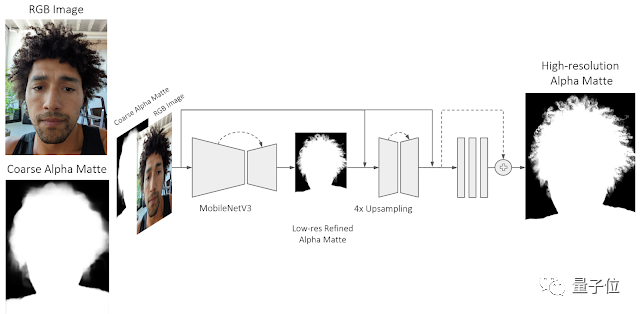
在推理时,Portrait matting首先将RGB图像和低分辨率的Alpha遮罩作为输入,用MobileNetV3来预测分辨率更高的Alpha遮罩。
然后再利用一个浅层网络和一系列残差块,来进一步提升Alpha遮罩的精细度。
其中,这个浅层网络更加依赖于低层特征,由此可以得到高分辨率的结构特征,从而预测出每个像素的Alpha透明度。
通过这种方式,模型能够细化初始输入时的Alpha遮罩,也就实现了如上细节到头发丝的抠图效果。谷歌表示,神经网络Portrait matting可以使用Tensorflow Lite在Pixel 6 上运行。
此外,考虑到使用Alpha遮罩抠图时,背光太强往往会导致细节处理不好。
谷歌使用了体积视频捕捉方案The Relightables来生成高质量的数据集。
这是谷歌在2019年提出的一个系统,由一个球形笼子组成,装有331个可编程LED灯和大约100个用于捕获体积视频的摄像机。
相比于一般的数据集,这种方法可以让人物主体的光照情况与背景相匹配,由此也就能呈现更为逼真的效果。

而且这种方法还能满足人像被放置在不同场景中时,光线变化的需求。

值得一提的,谷歌还在这一方法中使用了监督学习的策略。
这是因为神经网络在抠图上的准确度和泛化能力还有待提升,而纯人工标注的工作量又太大了。
所以,研究人员利用标记好的数据集来训练神经网络,从而大量数据中来提高模型泛化能力。

One More Thing
用算法来优化摄影效果,其实是谷歌的传统艺能了。
比如Pixel 4中,就使用算法来拍摄星空。

HDR+算法更不必说,曾经引发过大众热议。

这一功能可以在相机启动时、没有按快门的情况下连续捕捉图像,并且会缓存最近保存的9张。这些照片将会与按下快门后的图像一并处理,最终得到一张最优的图像。
同时它还能让Pixel在夜间模式下拍照时,不用像其他手机那样长时间停留。
由于提升摄影效果不靠硬件,谷歌也将这些功能整合到一个APP上,适用于各种安卓手机。
感兴趣的小伙伴,可以去试玩看看or分享自己的体验~
参考链接:
https://ai.googleblog.com/2022/01/accurate-alpha-matting-for-portrait.html
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号





