强化学习的起源:从老鼠走迷宫到AlphaGo战胜人类

新智元报道
新智元报道
编辑:如願
【新智元导读】本文介绍了基于模型的和无模型的两种强化学习。用人类和动物的学习方式进行举例,讲述了两种强化学习类型的起源、区别以及结合。
谈到强化学习,很多研究人员的肾上腺素便不受控制地飙升!它在游戏AI系统、现代机器人、芯片设计系统和其他应用中发挥着十分重要的作用。
强化学习算法有很多不同的类型,但主要分为两类:「基于模型的」和「无模型的」。

无模型的强化学习
无模型的强化学习


基于模型的强化学习


基于模型 VS 无模型

多种学习模式
多种学习模式
尽管取得了显著的成就,强化学习的进展仍然缓慢。一旦RL模型面临复杂且不可预测的环境,其性能就会开始下降。
Lee说:「我认为我们的大脑是一个学习算法的复杂世界,它们已经进化到可以处理许多不同的情况。」
除了在这些学习模式之间不断切换之外,大脑还设法一直保持和更新它们,即使是在它们没有积极参与决策的情况下。
心理学家Daniel Kahneman表示:「维护不同的学习模块并同时更新它们是有助于提高人工智能系统的效率和准确性。」

参考资料:
https://thenextweb.com/news/everything-you-need-to-know-about-model-free-and-model-based-reinforcement-learning


登录查看更多
相关内容

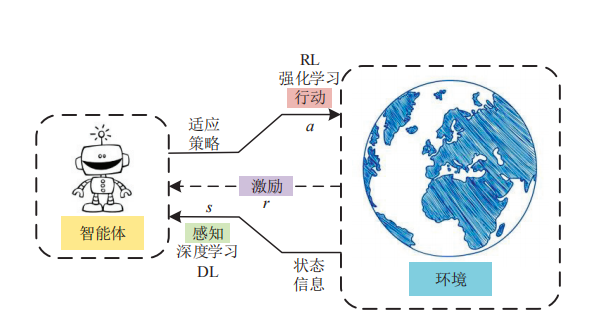
强化学习(RL)是机器学习的一个领域,与软件代理应如何在环境中采取行动以最大化累积奖励的概念有关。除了监督学习和非监督学习外,强化学习是三种基本的机器学习范式之一。
强化学习与监督学习的不同之处在于,不需要呈现带标签的输入/输出对,也不需要显式纠正次优动作。相反,重点是在探索(未知领域)和利用(当前知识)之间找到平衡。
该环境通常以马尔可夫决策过程(MDP)的形式陈述,因为针对这种情况的许多强化学习算法都使用动态编程技术。经典动态规划方法和强化学习算法之间的主要区别在于,后者不假设MDP的确切数学模型,并且针对无法采用精确方法的大型MDP。
专知会员服务
24+阅读 · 2022年3月19日
专知会员服务
48+阅读 · 2019年12月13日
Arxiv
16+阅读 · 2018年1月31日

相关VIP内容
专知会员服务
24+阅读 · 2022年3月19日
专知会员服务
48+阅读 · 2019年12月13日
相关资讯