「知识图谱」领域近期值得读的 6 篇顶会论文
CIKM 2017

论文 | Hike: A Hybrid Human-Machine Method for Entity Alignmentin Large-Scale Knowledge Bases
链接 | https://www.paperweekly.site/papers/1528
解读 | 罗丹,浙江大学硕士
1. Motivation
随着语义网络的迅速发展,越来越多的大规模知识图谱公开发布,为了综合使用多个来源的知识图谱,首要步骤就是进行实体对齐(Entity Alignment)。
近年来,许多研究者提出了自动化的实体对齐方法,但是,由于知识图谱数据的不均衡性,导致此类方法对齐质量较低,特别是召回率(Recall)。
因此,可考虑借助于众包平台提升对齐效果,本文提出了一个人机协作的方法,对大规模知识图谱进行实体对齐。
2. Framework
方法主要流程如图所示:
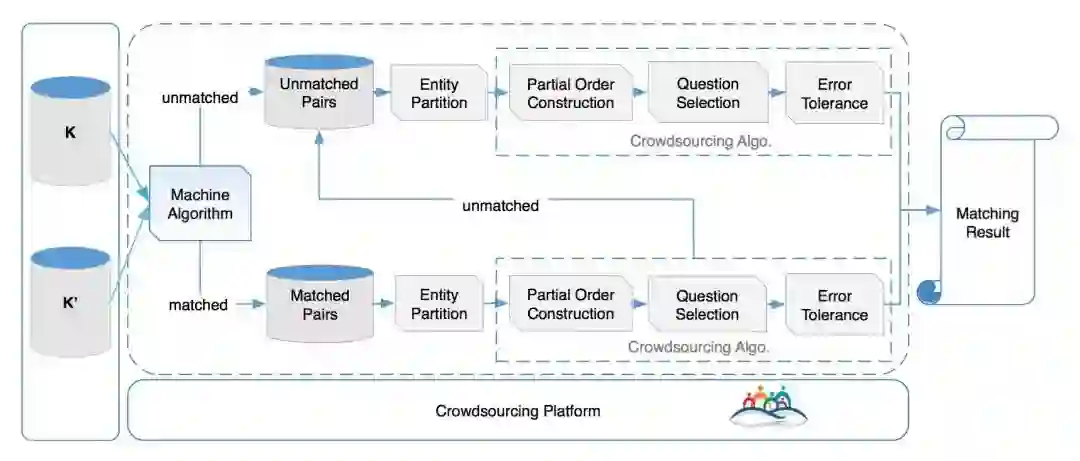
首先,通过机器学习方法对知识库进行粗略的实体对齐,然后分别将以对齐实体对(Matched Pairs)和未对齐实体对(Unmatched Pairs)放入众包平台,让人进行判断。
两条流水线的步骤类似,主要包括四个部分:实体集划分(Entity Partition)、建立偏序(Partial Order Construction)、问题选择(Question Selection)、容错处理(Error Tolerance)。
实体集划分的目的是将同类的实体聚类到一个集合,实体对齐只在集合内部进行,集合之间不进行对齐操作。实体集划分的依据是属性,通常同一类实体的属性是相似的。 偏序定义如下:

建立偏序的目的在于找出最具有推理期望(Inference Expectation)的实体对,偏序集实例如下:
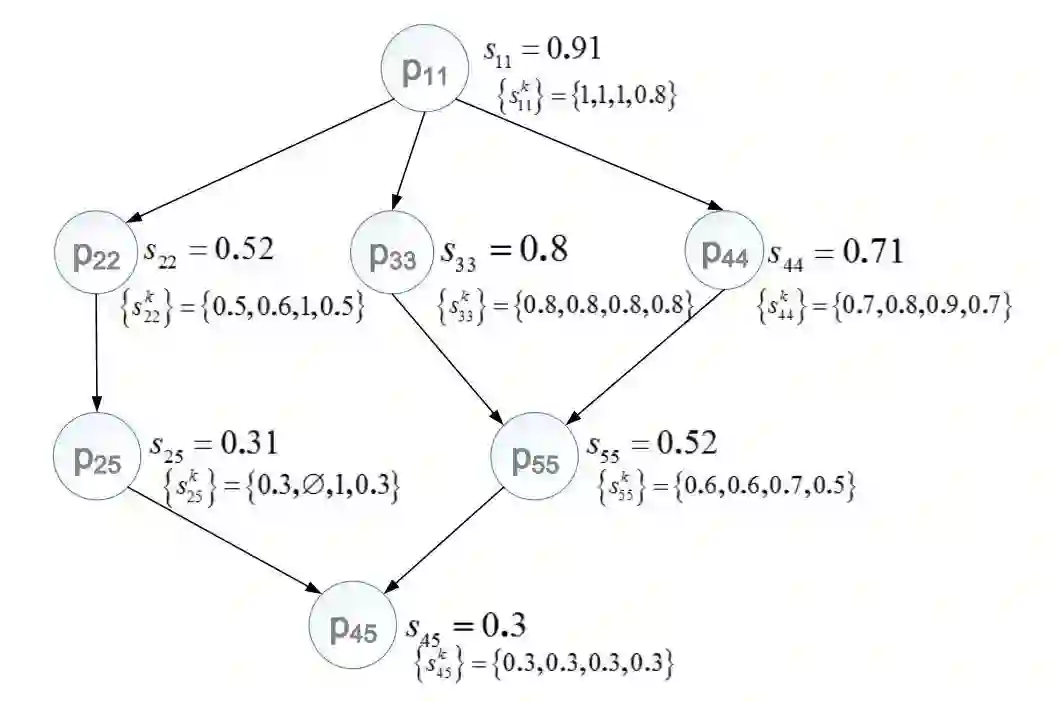
其中,如果 P11 被判断为 Unmatch,则所有偏序小于 P11 的节点都可以推断为 unmatch。反之,如果 P45 被推断为 Match,则所有偏序大于 P45 的节点都可以推断为 Match。推理期望公式如下:
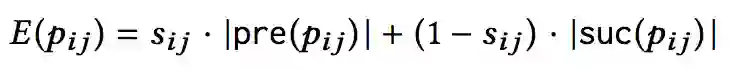
其中,pre 和 suc 分别表示前驱和后继节点。
对于问题选择,文章提出了两个贪心算法,分别为一次选一个节点以及一次选多个节点。算法如下:


3. Experiment
数据集:Yago,DBPedia
对比方法:PARIS,PBA
众包平台:ChinaCrowds
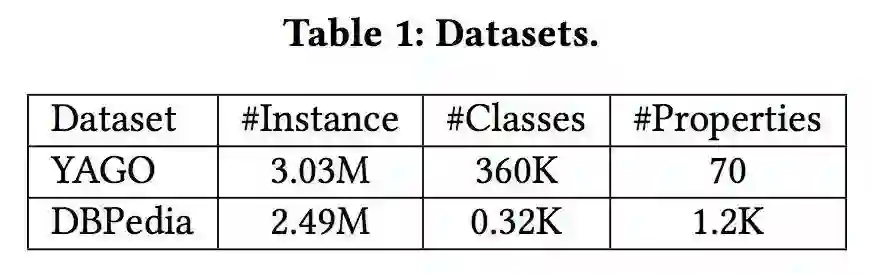
评估问题选择方法:
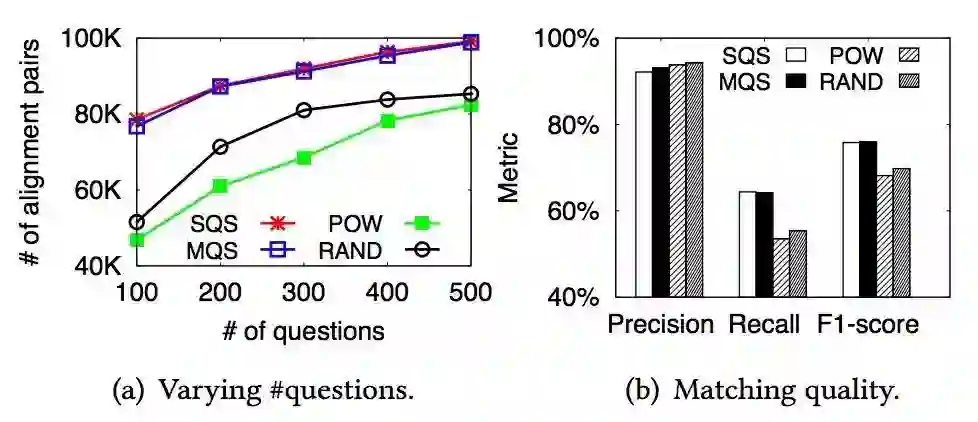
可以看到,两个贪心算法差别不大,但是比随机选择性能好。
评估问题集大小:
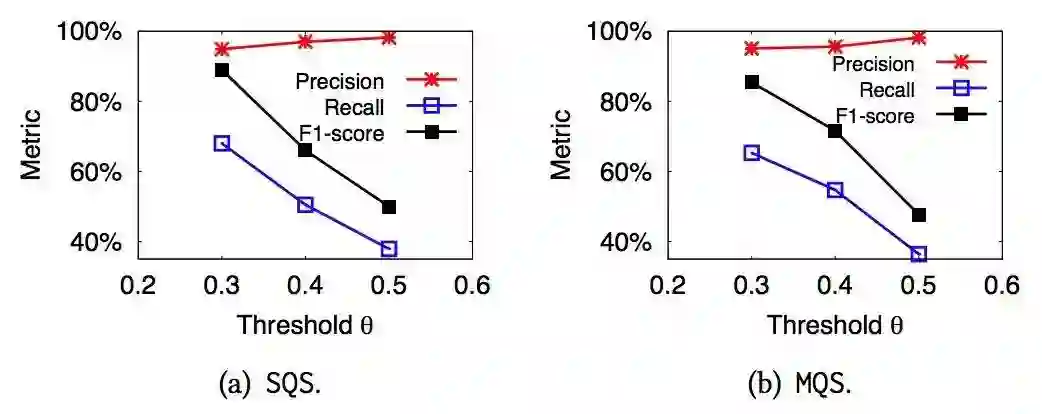
随着问题集合的增加,较精确率、召回率、F 值均有提升。
评估实体对齐结果:

实验表明,各项评估指标具有提升,证实了人机协作的有效性,但是 MQS 算法复杂度太高,导致运行时间过长。
ACL 2017

论文 | Learning with Noise: Enhance Distantly Supervised Relation Extraction with Dynamic Transition Matrix
链接 | https://www.paperweekly.site/papers/1529
解读 | 王冠颖,浙江大学硕士
1. 动机
Distant supervision 是一种生成关系抽取训练集的常用方法。它把现有知识库中的三元组 作为种子,匹配同时含有 e1 和 e2 的文本,得到的文本用作关系 r 的标注数据。这样可以省去大量人工标记的工作。
但是这种匹配方式会产生很多噪音:比如三元组 ,可能对齐到『Donald Trump was born in New York』,也可能对齐到『DonaldTrump worked in New York』。
其中前一句是我们想要的标注数据,后一句则是噪音数据(并不表示 born-in)。如何去除这些噪音数据,是一个重要的研究课题。
2. 前人工作
第一种方法是通过定义规则过滤掉一些噪音数据,缺点是依赖人工定义,并且被关系种类所限制。
另一种方法则是 Multi-instancelearning,把训练语句分包学习,包内取平均值,或者用 attention 加权,可以中和掉包内的噪音数据。缺点是受限于 at-least-one-assumption:每个包内至少有一个正确的数据。
可以看出前人主要思路是『去噪』,即降低噪声数据的印象。这篇文章提出用一个噪音矩阵来拟合噪音的分布,即给噪音建模,从而达到拟合真实分布的目的。
3. 模型
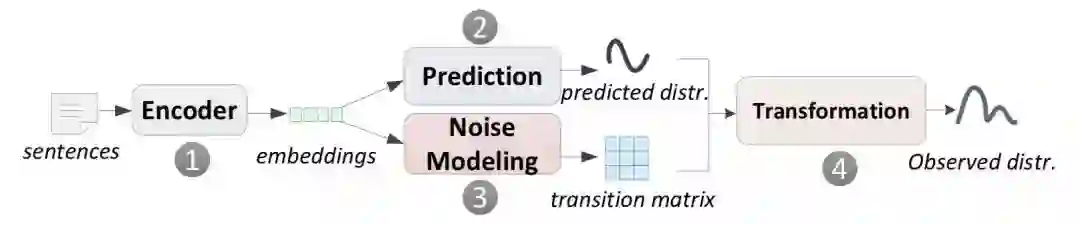
其中 1 和 2 是普通的关系抽取模型过程,3 和 4 是噪音拟合的过程。
transition matrix 是一个转移矩阵,大小为 n * n,n 是关系种类的数目。T_ij 的元素的值是 p( j| i ),即该句子代表关系为 i,但被误判为 j 的概率。 这样我们就可以得到:
𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑 𝑑𝑖𝑠𝑡𝑟𝑖𝑏𝑢𝑡𝑖𝑜𝑛 × 𝑇𝑟𝑎𝑠𝑖𝑡𝑖𝑜𝑛 𝑚𝑎𝑡𝑟𝑖𝑥=𝑂𝑏𝑠𝑒𝑟𝑣𝑒𝑑 𝑑𝑖𝑠𝑡𝑟𝑖𝑏𝑢𝑡𝑖𝑜𝑛
其中,predicted 是我们想要的真实分布,observed 是我们观测到的噪音分布,这样就可以用噪音数据进行联合训练了。
3.1 全局转移矩阵 & 动态转移矩阵
Global transition matrix 在关系层面上定义一个特定的转移矩阵,比如:
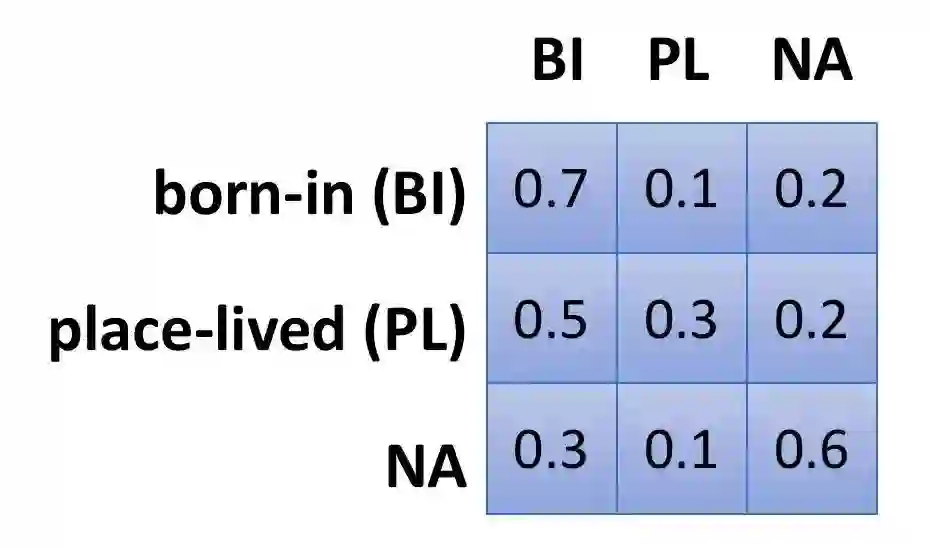
属于 A 关系的句子,被误判为 B 关系的概率是恒定的。 Dynamic transition matrix 是在句子层面上定义的,即使同属于 A 关系,a1 句子和 b1 句子被误判成 B 关系的概率也不同。
比如下面两句话,带有 old house 的被误判成 born-in 的概率更大。

动态转移矩阵更有优势,粒度更细。
3.2 训练方法
如果单纯用 observed 的 loss,会出现问题,因为在初始化的时候,我们并不能保证 p 一定拟合真实分布,转移矩阵也没有任何先验信息,容易收敛到局部最优。
因此,文中用 curriculum learning 进行训练:
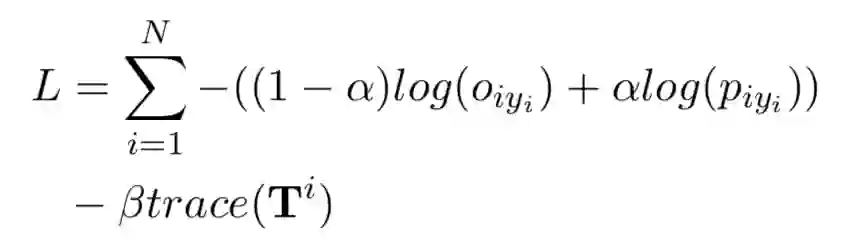
trace 是转移矩阵的迹,用于控制训练过程中噪音的作用,是矩阵的正则项。在没有噪音的情况下,矩阵是一个单位矩阵,迹较大,此时矩阵没有效果。迹越小,矩阵施加的效果越明显。
curriculum learning 的步骤:
初始阶段,alpha 为 1,beta 取一个很大的值,只学习 p 分布,让 p 获得关系判定的能力; 后续阶段,逐渐减小 alpha 和 beta,强化矩阵的作用,学习噪音分布 o,最后获得真实的 p 分布和噪音 o 分布。
这样通过调控过程,就可以避免学习出无意义的局部最优值了。
3.3 先验知识
可以给矩阵增加一些先验知识,比如在 timeRE 的数据集上,根据时间粒度,对数据集进行可信度划分,先训练可信数据,再训练噪音数据,这样可以优化最终的训练结果。
4. 实验结果
作者在 timeRE 和 entityRE (NYT) 上均进行了训练,取得了降噪的 state-of-art。具体分析结果可以参照论文。
AAAI 2017

论文 | Distant Supervision for Relation Extraction with Sentence-level Attention and Entity Descriptions
链接 | https://www.paperweekly.site/papers/179
解读 | 刘兵,东南大学博士
1. 论文动机
关系抽取的远程监督方法通过知识库与非结构化文本对其的方式,自动标注数据,解决人工标注的问题。但是,现有方法存在无法选择有效的句子、缺少实体知识的缺陷。
无法选择有效的句子是指模型无法判断关系实例对应的句子集(bag)中哪个句子是与关系相关的,在建模时能会将不是表达某种关系的句子当做表达这种关系的句子,或者将表达某种关系的句子当做不表达这种关系的句子,从而引入噪声数据。
缺少实体知识是指,例如下面的例句种,如果不知道 Nevada 和 Las Vegas 是两座城市,则很难判断他们知识是地理位置上的包含关系。
[Nevada] then sanctioned the sport , and the U.F.C. held its first show in [Las Vegas] in September 2001.
本文为了引入更丰富的信息,从 Freebase 和 Wikipedia 页面中抽取实体描述,借鉴表示学习的思想学习得到更好的实体表示,并提出一种句子级别的注意力模型。
本文提出的模型更好地实现注意力机制,有效降低噪声句子的影响,性能上达到当前最优。
2. 论文贡献
文章的贡献有:
引入句子级别的注意力模型来选择一个 bag 中的多个有用的句子,从而充分利用 bag 种的有用信息;
使用实体描述来为关系预测和实体表达提供背景信息;
实验效果表面,本文提出的方法是 state-of-the-art 的。
3. 论文方法
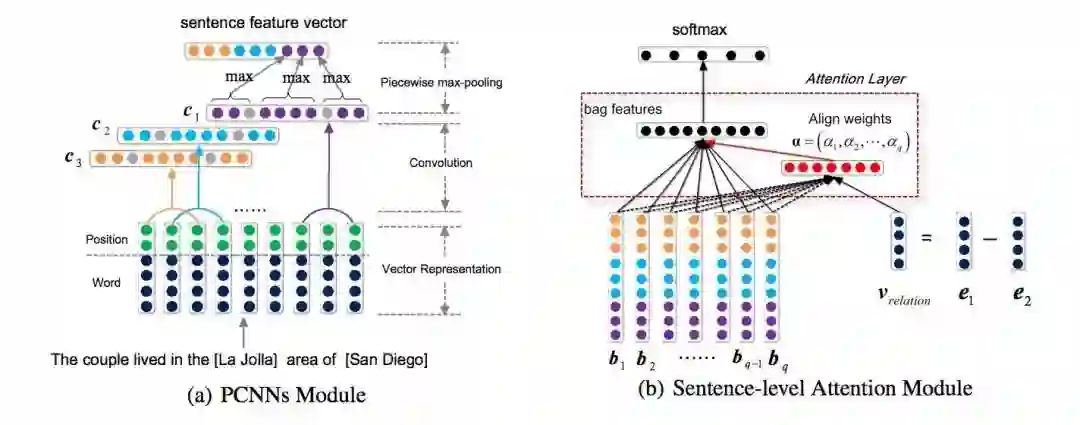
本文的方法包括三个部分:句子特征提取、实体表示和 bag 特征提取。
句子特征提取模型结构如下图(a)所示,模型流程如下:
使用词向量和位置向量相连接作为单词表示,句子的词表示序列作为模型的输入;
使用卷积神经网络对输入层提取特征,然后做 piecewise 较大池化,形成句子的特征表示。
实体表示在词向量的基础上,使用实体描述信息对向量表示进行调整,形成最终的实体向量表示。
模型主要思想是,使用 CNN 对实体的描述信息进行特征提取,得到的特征向量作为实体的特征表示,模型的训练目标是使得实体的词向量表示和从描述信息得到的实体特征表示尽可能接近。
Bag 特征提取模型的关键在句子权重学习,在得到 bag 中每个句子的权重后,对 bag 中所有句子的特征向量进行加权求和,得到 bag 的特征向量表示。
模型中用到了类似 TransE 的实体关系表示的思想:e1+r=e2。使用(e2-e1)作为实体间关系信息的表达,与句子特征向量相拼接,进行后续的权重学习。
Bag 特征提取模型如上图(b)所示:
使用 bag 中的所有句子的特征向量表示,结合 e2-e1方式得到的关系表示,作为模型的输入;
利用权重学习矩阵,得到每个句子的权重;
对句子进行加权求和,得到 bag 的最终表示。
4. 实验
文章在远程监督常用的数据集(Rediel 2010)上,按照常规的远程监督的实验思路,分别进行了 heldout 和 manual 实验。
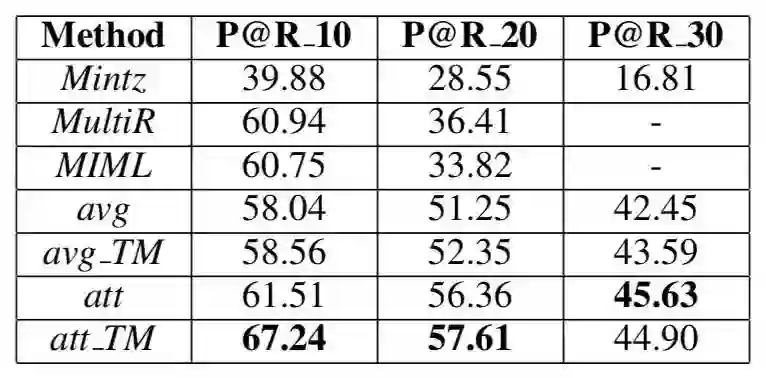
Heldout 实验即使用知识库中已有的关系实例标注测试集,验证模型的性能,结果如下面的 Precision-Recall 图所示,超过其他较好的方法。

Manual 实验对知识库中不存在的关系实例进行预测,然后使用人工标注预测结果的正确性,使用 top-K 作为评测指标,结果如下表所示,本文提出的方法也达到了当前较好的效果。

此外,实验还通过 case study,研究了模型对于 bag 中每个句子的注意力分配效果,表明本模型可以有效地区分有用的句子和噪声句子,且本文的引入实体描述可以使得模型得到更好的注意力分配。
IJCAI 2017

论文 | Dynamic Weighted Majority for Incremental Learning of Imbalanced Data Streams with Concept Drift
链接 | https://www.paperweekly.site/papers/1530
解读 | 邓淑敏,浙江大学 2017 级直博生
1. 论文动机
数据流中发生的概念漂移将降低在线学习过程的准确性和稳定性。如果数据流不平衡,检测和修正概念漂移将更具挑战性。目前已经对这两个问题分别进行了深入的研究,但是还没有考虑它们同时出现的情况。
在本文中,作者提出了一种基于块的增量学习方法,称为动态加权多数增量学习(DWMIL)来处理具有概念漂移和类不平衡问题的数据流。DWMIL 根据基分类器在当前数据块上的性能,对基分类器进行动态加权,实现了一个整体框架。
2. Algorithm & Ensemble Framework
算法的输入:在时间点 t 的数据 D^(t)={xi belongs to X,yi belongs to Y}, i=1,...,N, 删除分类器的阈值 theta, 基分类器集合 H^(t-1)={H^(t-1)_1,...,H^(t-1)_m}, 基分类器的权重 w^(t-1), 基分类器的数量 m, 集成的规模大小 T。
Step 1:通过集成分类器对输入的进行预测。

Step 2:计算当前输入的数据块在基分类器上的错误率 epsilon^t_j,并更新基分类器的权重。
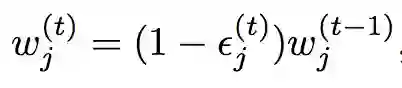
Step 3:移除过时的分类器(权重值小于阈值 theta)并更新基分类器数量。

Step 4:构建新的分类器并对其初始化。
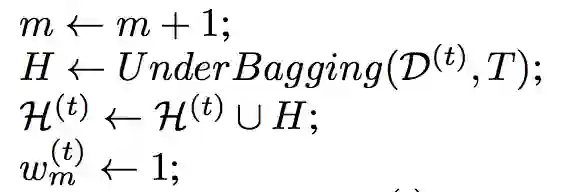
算法的输出:更新的基分类器集合 H^(t), 基分类器的权重 W^(t),基分类器的数量 m,目标预测值 bar_y。
本文的算法如下图所示:


3. Experiments
本文选取了 4 个合成、2 个真实的均具有概念漂移的数据集。并且在集合方法、自适应方法、主动漂移检测方法中各选取了一个具有代表性的作为 baseline,分别是:Learn++.NIE(LPN)、Recursive Ensemble Approach (REA)、Class-Based ensemble for Class Evolution(CBCE),并与 Dynamic Weighted Majority (DWM) 也进行了比较。
对具有概念漂移的合成数据集和实际数据集的实验表明,DWMIL 与现有技术相比,性能更好,计算成本更低。
4. Comparisons
与现有方法相比,其优点在于以下 4 点:
能够使非偏移的数据流保持稳定,快速适应新的概念;
它是完全增量的,即不需要存储以前的数据;
模型中保持有限数量的分类器以确保高效;
简单,只需要一个阈值参数。
DWMIL 与 DWM 相比:
在学习数据流的过程中,DWMIL 和 DWM 都保留了一些分类器。但是,在决定是否创建一个新的分类器时,DWM 的依据是单个样本的预测性能。如果数据不平衡,则样本属于多数类的概率比少数类的高得多,并且对多数类样本错误分类的概率较低。
因此,DWM 在不平衡数据流上创建新分类器的机会很低。事实证明,它可能无法有效地适应新的概念。相比之下,DWMIL 为每个数据块创建一个新的分类器,以及时学习新的概念。
在决定是否移除一个过时或低效的分类器时,DWM 中分类器的权重通过固定的参数β减少,并且在归一化之后再次减小。
相反,DWMIL 根据性能降低了权重,没有任何标准化。因此,如果当前概念与创建分类器的概念类似,则分类器可以持续更长时间来对预测做出贡献。
DWMIL 与 Learn++ 相比:
Learn++ 和 DWMIL 都是为每个数据块创建分类,并使用分类错误率来调整权重。
但是,关于降低在过去的数据块上训练的分类器的权重这一问题,Learn++ 使用了时间衰减函数 σ。这个 σ 取决于两个自由参数:a 和 b,其中不同的值会产生不同的结果。在 DWMIL 中,减重仅取决于没有自由参数的分类器的性能。
关于分类器权重的影响因素,在 Learn++ 中,权重不仅取决于当前数据块,还取决于创建的分类器到当前数据块的数据块。在这种情况下,可能会产生偏差。
具体来说,如果一个分类器在其创建的数据块上表现得非常好,它将在接下来几个数据块中持续获得更高的权重。如果概念发生变化,那么在旧概念上训练的分类器的高权重将降低预测效果。
关于分类器的性能,Learn++ 会保留所有的分类器。如果数据流很长,累积的分类器会增加计算负担,因为它需要评估当前分块上所有过去的分类器的性能。相比之下,DWMIL 放弃了过时或无用的分类器来提高计算效率。
笔者认为,这篇文章的主要创新点在于:用数据块的输入代替传统的单一样本输入,使得模型可以更快地对概念漂移作出反应;通过对分类器性能的检测,动态调整它们的权重,并及时剔除过时或低效的分类器,使得模型比较高效。
AAAI 2018

论文 | Reinforcement Learning for Relation Classification from Noisy Data
链接 | https://www.paperweekly.site/papers/1260
解读 | 周亚林,浙江大学硕士
1. 论文动机
Distant Supervision 是一种常用的生成关系分类训练样本的方法,它通过将知识库与非结构化文本对齐来自动构建大量训练样本,减少模型对人工标注数据的依赖。
但是这样标注出的数据会有很多噪音,例如,如果 Obama 和 United States 在知识库中的关系是 BornIn,那么“Barack Obama is the 44th President of the United States.”这样的句子也会被标注为 BornIn 关系。
为了减少训练样本中的噪音,本文希望训练一个模型来对样本进行筛选,以便构造一个噪音较小的数据集。模型在对样本进行筛选时,无法直接判断每条样本的好坏,只能在筛选完以后判断整个数据集的质量,这种 delayed reward 的情形很适合用强化学习来解决。
2. 模型
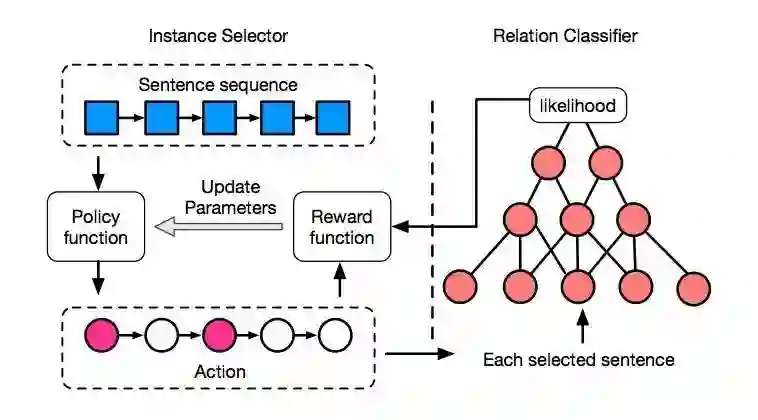
模型框架如图所示,左边是基于强化学习的 Instance Selector,右边是经典的基于 CNN 的 Relation Classifier。
Instance Selector 根据 Policy function 对样本逐个筛选,每个样本都可以执行“选”或“不选”两种 Action,筛选完以后会生成一个新的数据集。
我们用 Relation Classifier 来评估数据集的好坏,计算出一个 reward,再使用 policy gradient 来更新 Policy function 的参数,这里的 reward 采用的是数据集中所有样本的平均 likelihood。
为了得到更多的反馈,提高训练效率,作者将样本按照实体对分成一个个 bag,每次 Instance Selector 对一个 bag 筛选完以后,都会用 Relation Classifier 对这部分数据集进行评估,并更新 Policy function 的参数。
在所有 bag 训练完以后,再用筛选出的所有样本更新 Relation Classifier 的参数。 具体训练过程如下:

3. 实验
论文在 NYT 数据集上与目前主流的方法进行了比较,注意这里是 sentence-level 的分类结果,可以看到该方法取得了不错的效果。
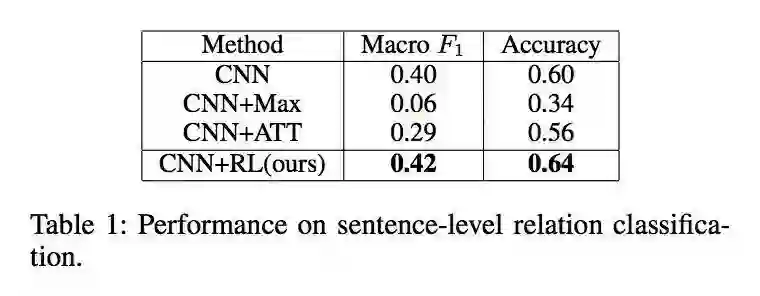
论文分别在原始数据集和筛选以后的数据集上训练了两种模型,并用 held-out evaluation 进行评估,可以看出筛选以后的数据集训练出了更好的关系分类模型。
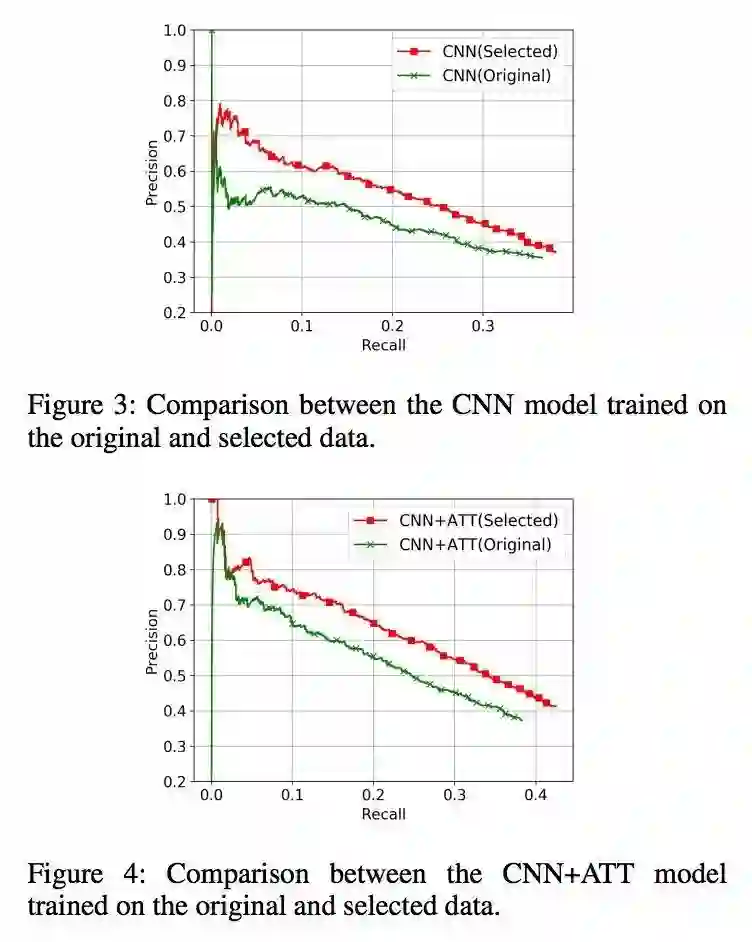
作者又比较了使用强化学习和 greedy selection 两种筛选样本的方法,强化学习的效果更好一些。
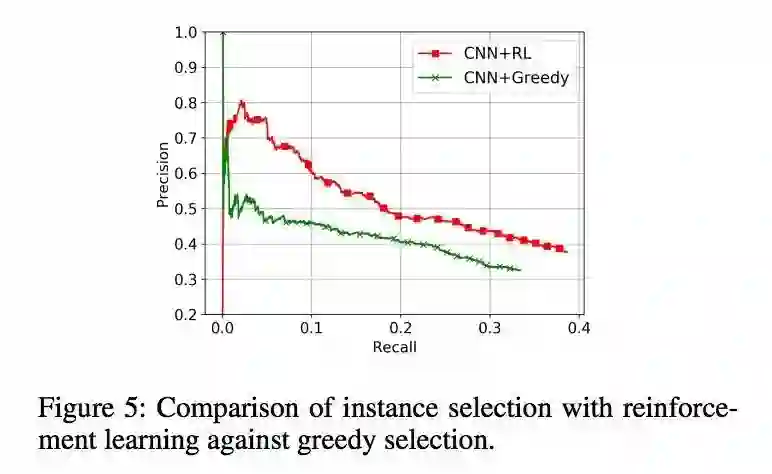
AAAI 2017

论文 | Leveraging Knowledge Bases in LSTMs for Improving Machine Reading
链接 | https://www.paperweekly.site/papers/1531
解读 | 李娟,浙江大学博士生
这篇论文是今年发表在 ACL 的一篇文章,来自 CMU 的工作,提出通过更好地利用外部知识库的方法解决机器阅读问题。
由于传统方法中用离散特征表示知识库的知识存在了特征生成效果差而且特征工程偏特定任务的缺点,本文选择用连续向量表示方法来表示知识库。
传统神经网络端到端模型使得大部分背景知识被忽略,论文基于 BiLSTM 网络提出扩展网络 KBLSTM,结合 attention 机制在做任务时有效地融合知识库中的知识。
论文以回答要不要加入 background knowledge,以及加入哪一些信息两部分内容为导向,并借助以下两个例子说明两部分内容的重要性。
“Maigretleft viewers in tears.”利用背景知识和上下文我们可以知道 Maigret 指一个电视节目,“Santiago is charged withmurder.”如果过分依赖知识库就会错误地把它看成一个城市,所以根据上下文判断知识库哪些知识是相关的也很重要。
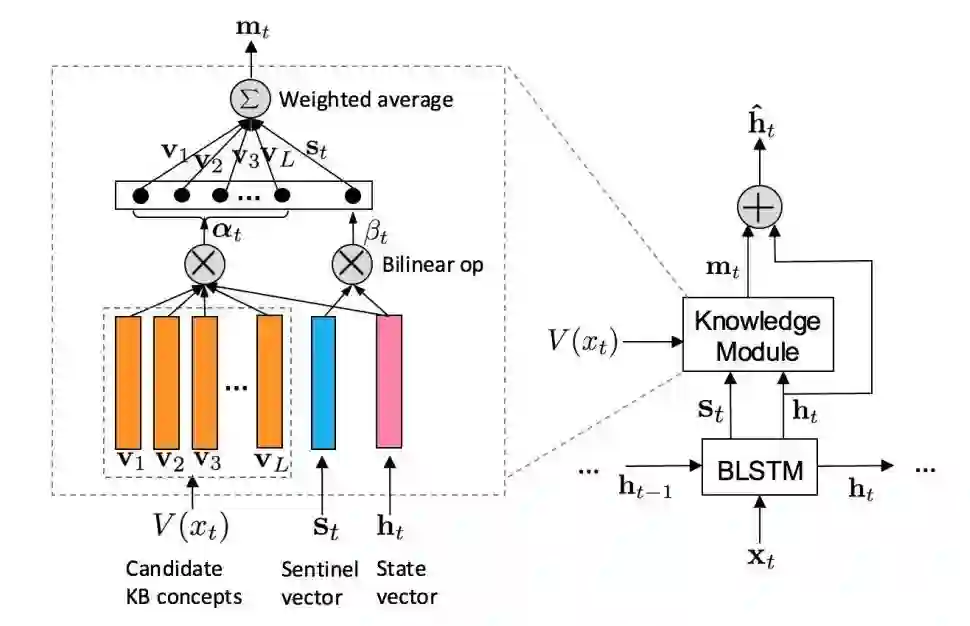
KBLSTM(Knowledge-aware Bidirectional LSTMs)有三个要点:
检索和当前词相关的概念集合V(x_t)
attention 动态建模语义相关性
sentinel vector S_t 决定要不要加入 background knowledge
主要流程分两条线:
1. 当考虑背景知识的时候就把 knowledge module 考虑进去;
2. 如果找不到和当前词相关的概念则设置 m_t 为 0,直接把 LSTM 的 hidden state vector 作为最后的输出。
后者简单直接,这里说明前者的结构。knowledge module 模块把 S_t、h_t、V(x_t) 作为输入,得到每个候选知识库概念相对于 h_t 的权重 α_t,由 S_t 和 h_t 得到 β_t 作为 S_t 的权重,最后加权求和得到 m_t 和 h_t 共同作为输入求最后输出,这里通过找相关概念和相关权重决定加入知识库的哪些知识。
论文用 WordNet 和 NELL 知识库,在 ACE2005 和 OntoNotes 数据集上做了实体抽取和事件抽取任务。两者的效果相对于以前的模型都有提升,且同时使用两个知识库比任选其一的效果要好。
文章来源:PaperWeekly

《知识图谱实战》课程通过实战构造有价值的知识图谱,用数据,代码,具体的算法,落地的产品,多方位全面揭示知识图谱的各个方面,使学习者能快速上手,打造自己的知识图谱产品,并复制到一系列典型场景中。点击下方二维码报名课程





