阿里巴巴电商推荐之十亿级商品embedding

广告推荐算法系列文章:
-
莫比乌斯: 百度的下一代query-ad匹配算法 -
百度凤巢分布式层次GPU参数服务器架构 -
DIN: 阿里点击率预估之深度兴趣网络 -
基于Delaunay图的快速最大内积搜索算法 -
DIEN: 阿里点击率预估之深度兴趣进化网络 -
EBR: Facebook基于向量的检索 -
阿里巴巴电商推荐之十亿级商品embedding(本篇)
Overall
本文是论文[1]的阅读笔记,论文[1]是阿里在KDD 2018上的论文。
2018年,淘宝上有10亿用户,以及200亿种商品,2017年的GMV成交总额则是3.7万亿。如何帮助用户找到感兴趣的商品是实打实的真金白银。
推荐系统,它根据用户的历史行为来捕捉用户的偏好,从而给用户推荐商品。是占据了淘宝的大部分的收入和流量,是成交总额的一个重要引擎。
下图就是淘宝推荐系统的一个例子。虚实线框柱的部分是个性化的结果,这个主页占据了推荐系统40%的流量。
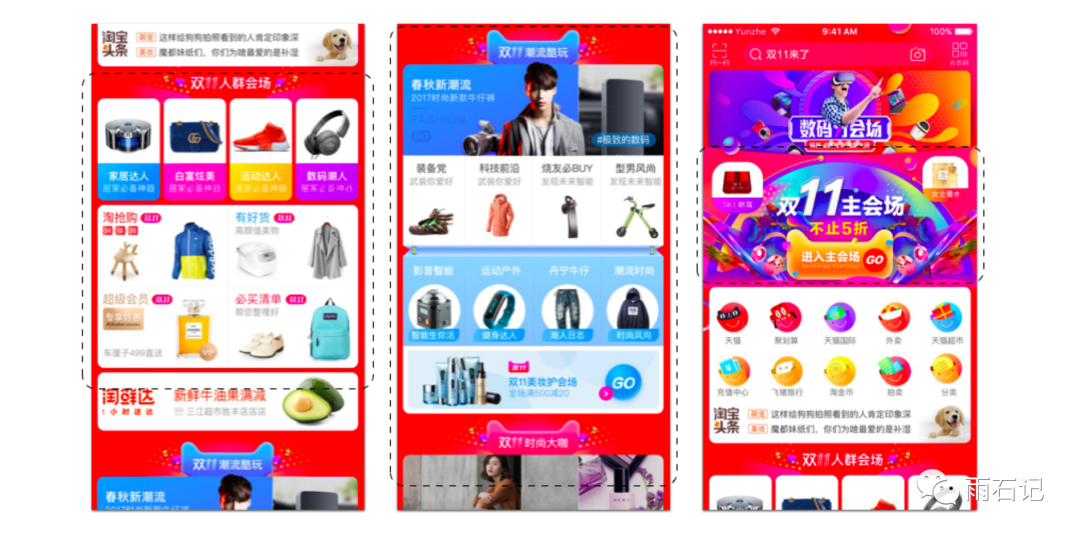
有很多种推荐系统都被应用到淘宝中,例如:
-
协同过滤 -
基于内容的方法 -
基于深度学习的方法
但无论哪种技术,在淘宝的大规模下,都不可避免遇到三个问题:
-
扩展性: 很多技术在小数据集上表现不错,但在大规模数据集上却未必,需要做适应。 -
稀疏性: 相对于总商品数来说,跟用户有关联的商品是很少的,这样就很难把系统做的精准。 -
冷启动: 每小时都有几百万的商品被添加,这些新添加的商品没有任何操作记录,如何去推荐它们,这就是冷启动问题。
推荐系统和广告系统其实类似,都是按照两层框架去走,即matching和ranking。matching的作用是找到用户感兴趣的商品,ranking则用一个深度神经网络去做排序。这点我们在前面几篇文章中已经反复提到了。
论文[1]主要关注解决matching层的问题。提出了Base Graph Embedding(BGE)算法来对商品进行编码,编码后就可以使用向量内积计算相似度来进行商品的检索。
而之前介绍的DIN和DIEN则主要在Ranking层工作。
为了解决冷启动的问题,使用附加信息对新商品进行embedding的计算,提出了Graph Embedding with Side Information算法,即GES算法。主体思想就是使用类似的商品编码来生成新商品的编码。
为了使新商品编码更加精准,又添加了一种加权机制,即Enhanced Graph Embedding with Side Information(EGES)算法。
为了解决性能问题,将提出的算法部署在XTensorflow平台上,XTF是TF在淘宝的一个变种。
接下来,我们会一一解释这三个算法。
Base Graph Embedding - 图构建
既然是Graph Embedding, 那么首先第一步就是图的构建。怎么样对商品构建图呢?
答案是基于会话的用户行为历史,即在一个时间段内,用户的操作历史中,如果两个商品同时出现,则在两个商品间加一条边。
如下图所示,有三个用户的操作序列,根据序列中商品的前后顺序,在图上连有向边,比如U1的序列式DAB,那么就添加D->A, A->B两条边。
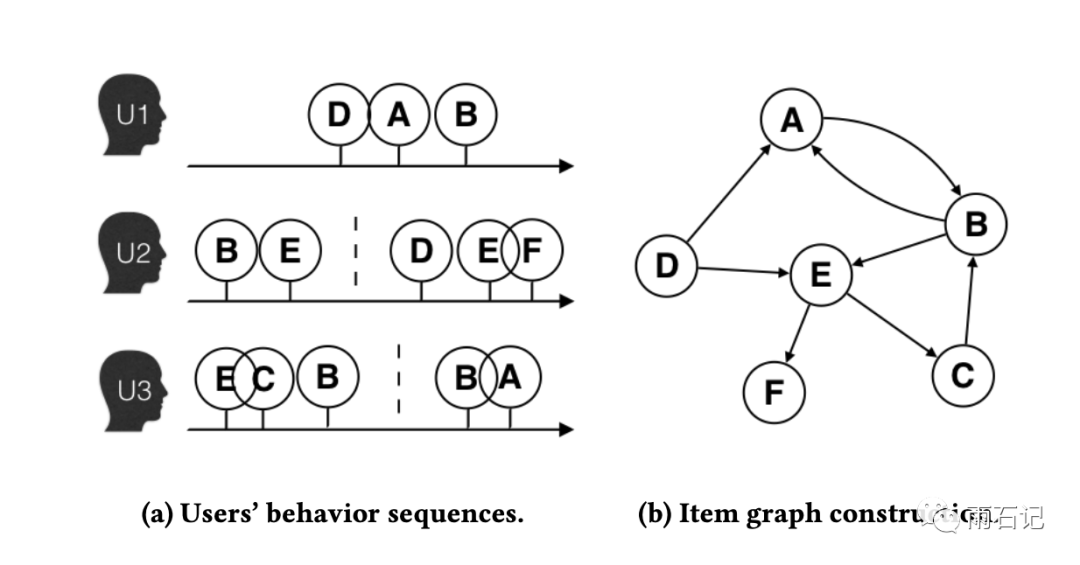
协同过滤也依靠用户的操作序列来计算相似度,但是没有办法考虑序列的前后信息,但基于图的方法可以,这也是Graph Embedding算法的一个优势。
添加了边之后,还需要在边上添加权重,权重很简单,就是A->B在所有用户中出现的次数。
还有一个问题,那就是为何只在一个时间段内选择用户操作历史而不是全部操作历史?原因有二:
-
数据量太大,系统负载很重 -
用户兴趣会漂移,之前感兴趣的未必对最近有大的影响。
当然,构建图的时候,数据中会有很多噪音需要排除,比如:
-
点击一个商品后,停留的时间没有超过一秒,那么就意味着这次点击是无意的。 -
那些过于活跃的用户是垃圾用户,根据长时间的观察,如果一个用户三个月内买了1000件商品,或者三个月内有3500次点击,那么很有可能这是个垃圾用户。 -
零售商会持续更新商品,他们的访问记录应该被去掉,因为并不代表普通用户。
太可怕了,过于活跃不仅不会被当成重点用户,反而是垃圾用户,不被算法考虑进来。剁手党们要注意了。哈哈,
Just a Joke,我猜测,更多的原因是如果一个账号购买太多,那么它很可能并不代表一个普通用户,或许代表一个机构,所以不能被当做普通用户处理。
Base Graph Embedding - embedding训练
BGE是基于两种算法做embedding训练的:
-
Random Walk: 用来生成商品序列 -
skip-gram: 著名的word2vec中的一种训练方式。在这里可以基于商品序列去得到embedding。
有时间我们会再分享这两种方法,这里,不了解这两种方法的话也不影响对BGE的理解。
在构建了图之后,就可以使用Random Walk生成商品序列。在做这个事情之前,我们首先将图上边的权重从count变成概率,即对每一个节点的出度做归一化:
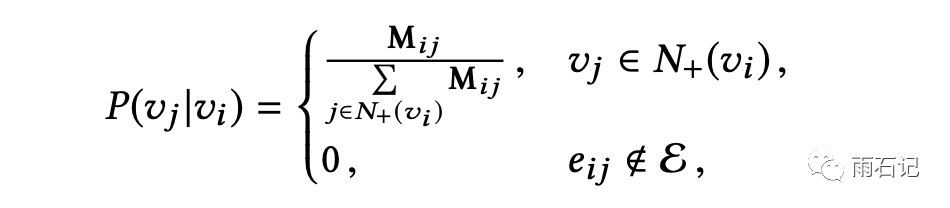
生成的序列如下图左图。即从某个节点开始,根据出度的边概率,随机采样得到的。
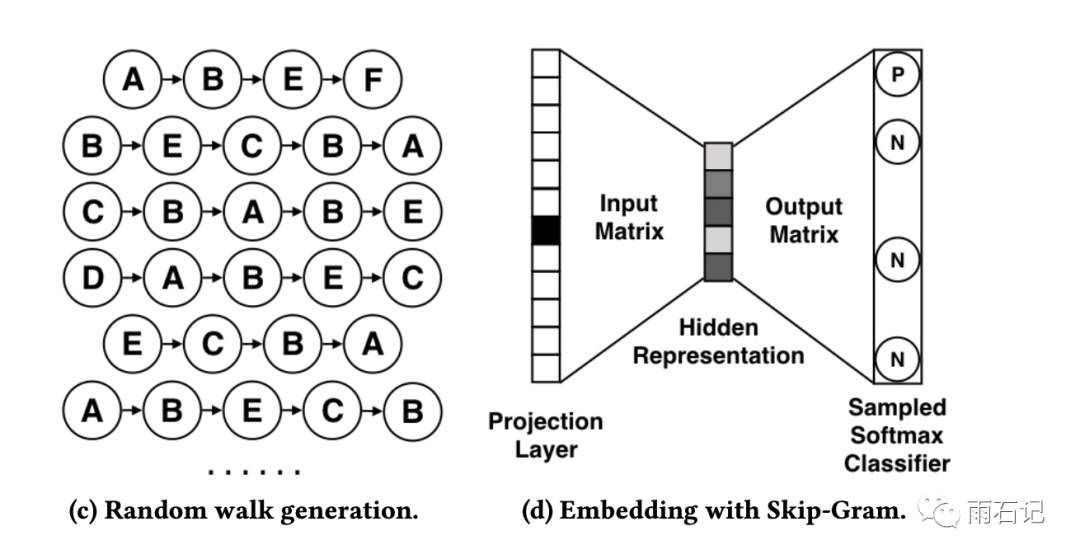
基于Random Walk的结果,使用skip-gram的方式去训练embedding。在这个模型中,首先让每个商品都对应一个embedding,然后整个序列就成了embedding的序列,然后,对应序列中的每个embedding,输入给一个多层神经网络,去预测当前位置周边的几个位置的商品是什么。这就是skip-gram的训练方式。
skip-gram有个重要参数,那就是窗口大小,即预测的时候预测当前位置周边位置的多少的控制参数。
单个位置的预测公式如下:
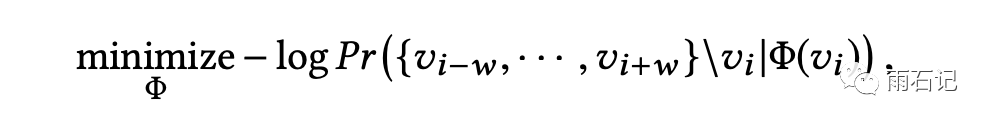
考虑到一个窗口,总体公式如下:
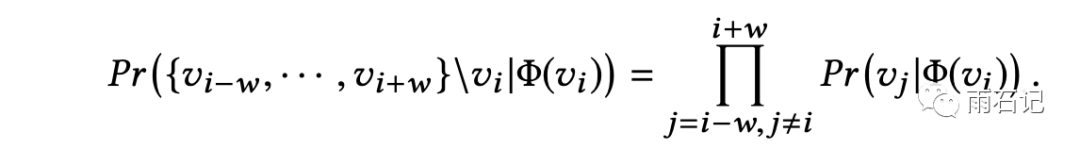
当然,由于商品太多,所以在训练时,会随机采样负例来训练softmax。所以公式又变成:
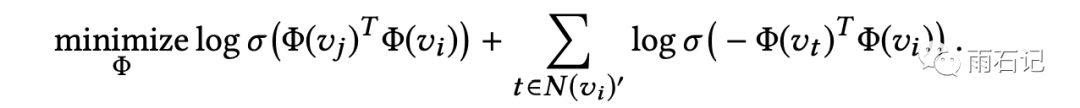
Graph Embedding With Side Information
为了解决冷启动问题,使用附加信息来对新商品训练embedding。这个idea的动机也很明确,比如:
-
优衣库的两个外套的embedding应该类似。 -
尼康镜头和佳能相机的embedding应该也相近。
因此,为了利用附加信息,对商品的embedding做扩展,除了本身的embedding外,还要对商品的每一项附加信息做embedding,这样,对于一个商品而言,就有多个embedding,将这些embedding做平均,得到整个商品的embedding。
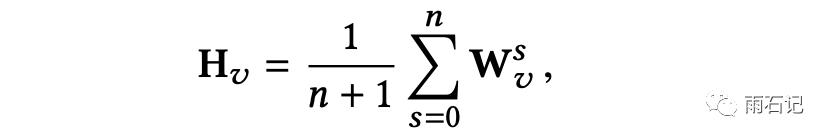
这样,对于新商品而言,虽然没有商品的embedding,但是有附加信息的embedding,所以仍然是有embedding的。
Enhanced Graph Embedding With Side Information
上面的GES算法虽然有效,但有个问题,那就是所有的附加信息的作用是等价的,我们知道,这显然不是一个好的策略,不同情境下,不同附加信息的作用不同,比如:
-
买了iphone的用户因为品牌去关注Macbook和iPad。 -
为了方便和价格,用户可能会在同一个商店买不同牌子的衣服。
所以为了解决这个问题,Enhance方法提出了加权,如下图,各种embedding通过加权组成一个embedding,然后再去训练skip-gram。
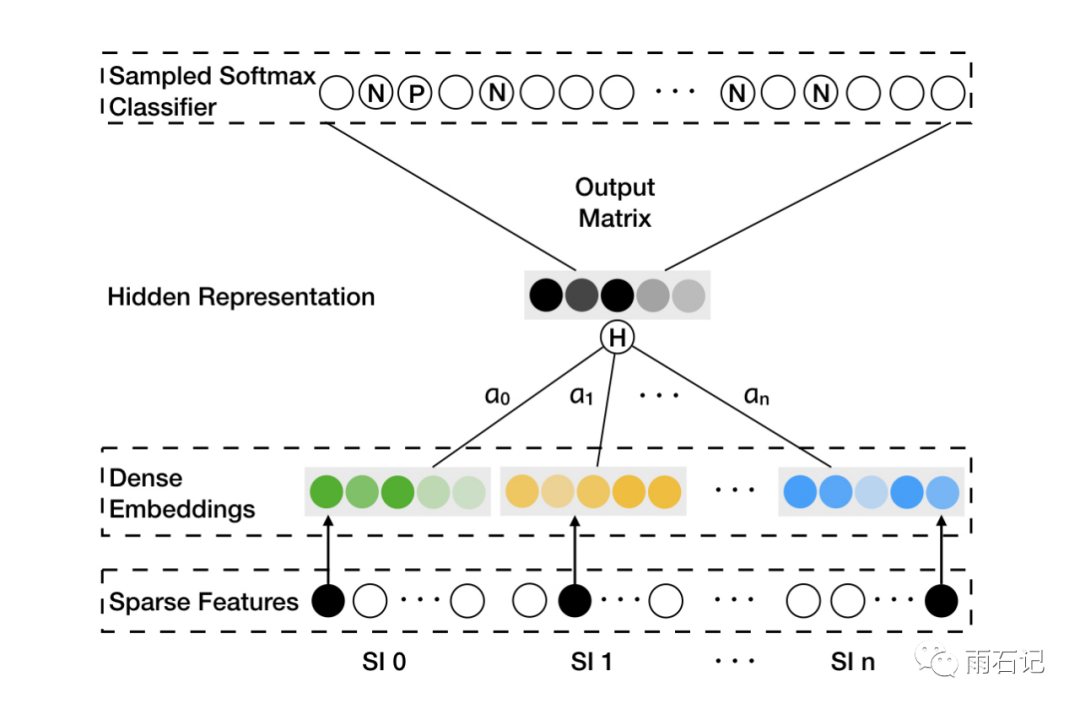
汇总下来,算法如下:


实验
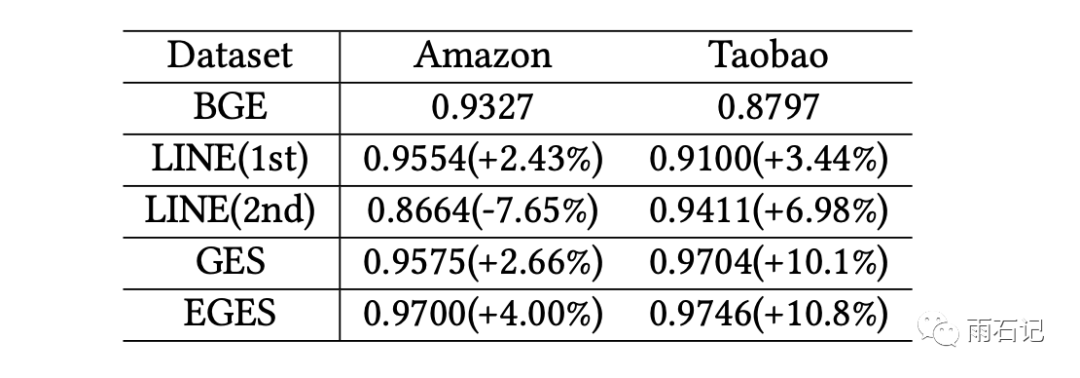
使用Link prediction任务对embedding进行衡量,Link prediction是指在一个图中,随机将1/3的边去掉,然后去进行预测,结果如下:
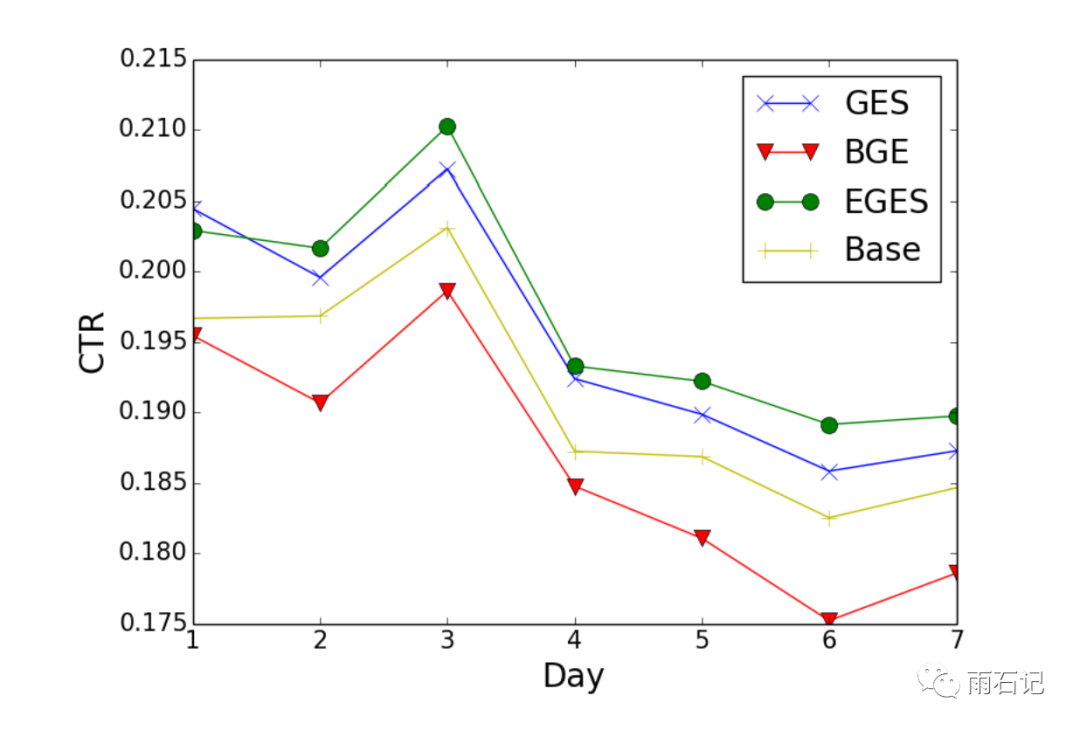
在真实系统上,得到的CTR提升:
可视化
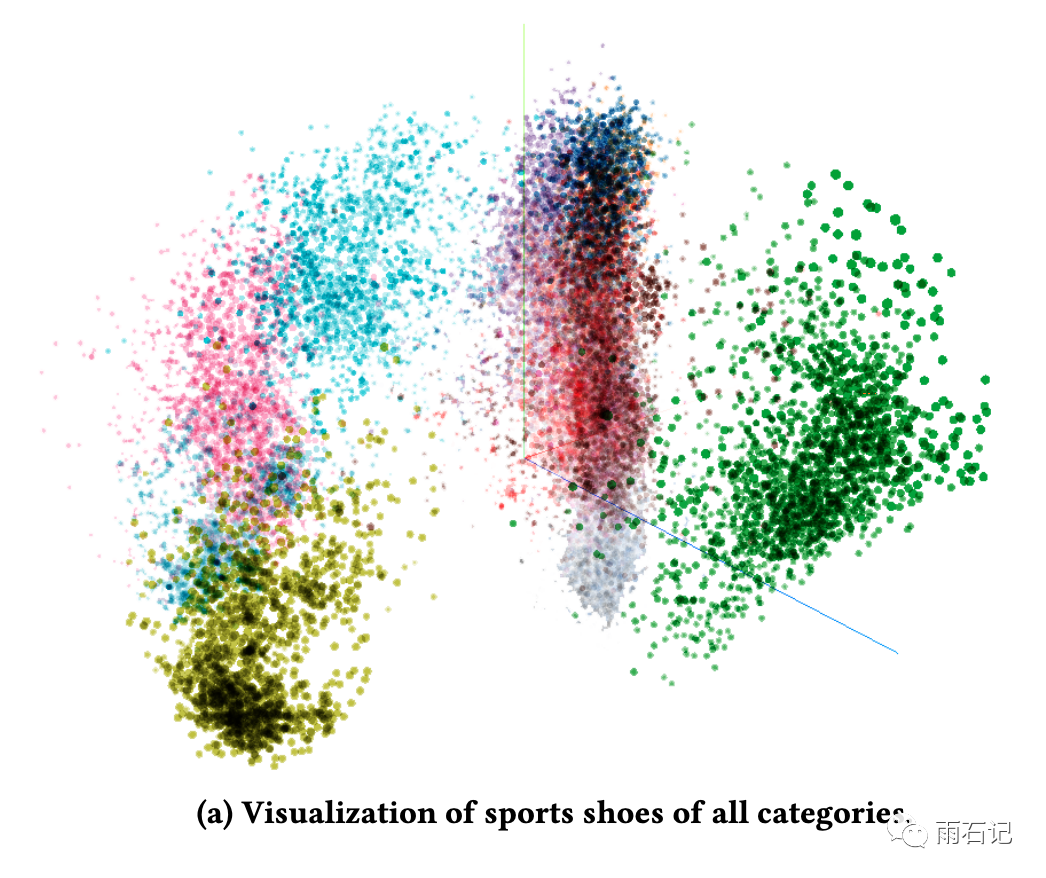
使用Tensorflow的可视化工具对embedding进行可视化,比如对所有的鞋进行可视化,可以看到,不同品牌的鞋会聚集在一起。
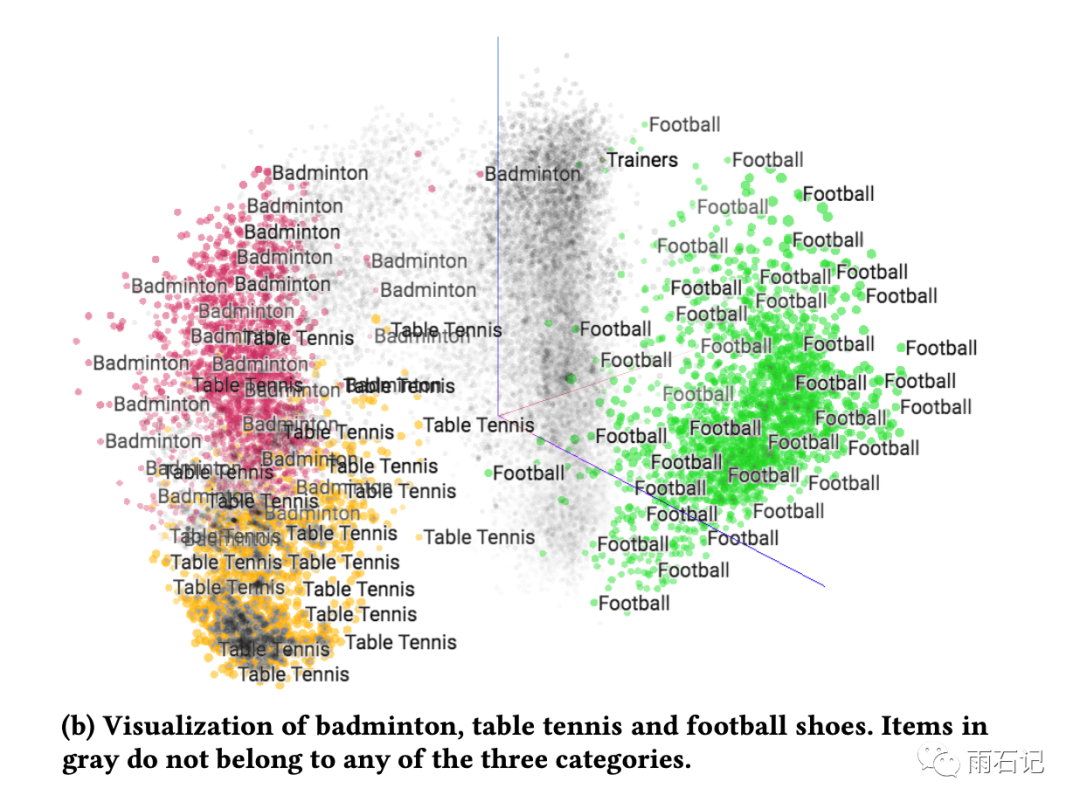
有相同附加信息的商品应该会离得更近,如下图,羽毛球和乒乓球离得更近,因为都是室内运动,而足球具体它们较远。
对于冷启动而言,我们看看新商品的编码是不是和已有的类似商品接近,对于新商品,在商品库中找到最接近的Top-4进行查看,如下,可以看到附加信息的有效性。

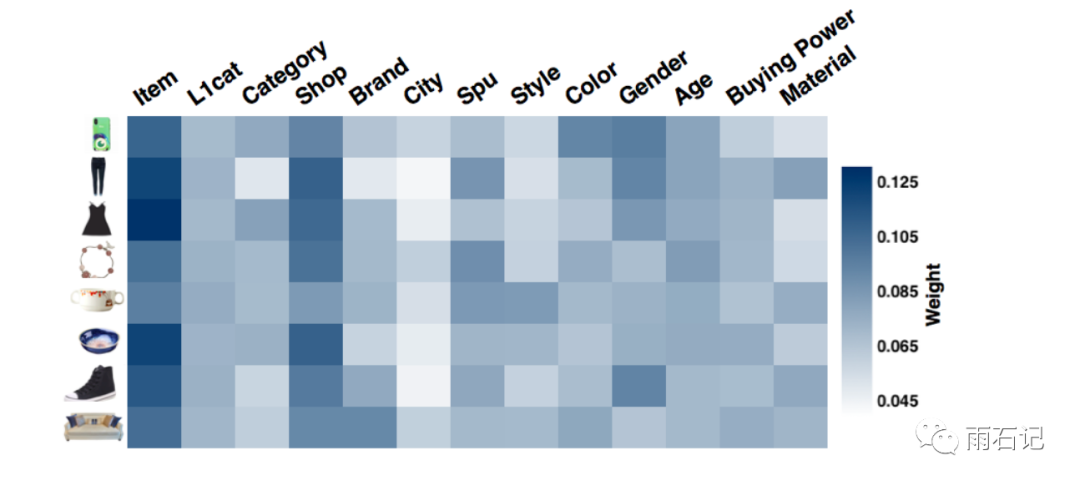
EGES的权重可视化如下,可以看到:
-
不同的附加信息的权重不同 -
在所有的权重中,item本身的权重大于附加信息的,由此可见,item中包含有大量有用的信息。 -
除开item外,shop的权重最大,与用户在淘宝的习惯是一致的,即容易在同一个商店内购买商品。
系统部署
系统架构如下:
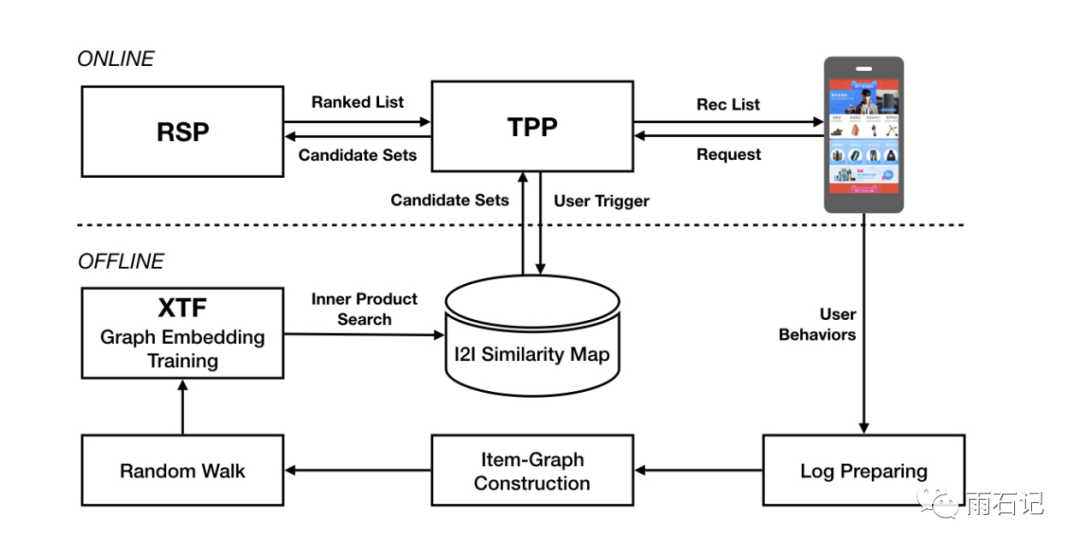
当用户打开淘宝app的时候,TPP(Taobao Personality Platform)会抽取用户最近的信息,并检索相似的条目。然后这些条目会被输入给RSP(Ranking Service Platform)进行排序。
用户的操作历史会被保存在日志中,在线下进行处理。
一些细节如下:
-
选择最近三个月的日志进行处理,处理前会先用反垃圾过滤系统进行筛选,筛选后大概有600个billion的条目保留。 -
整张图被切分成子图,在ODPS中进行处理,每个子图中有50M个节点 -
使用ODPS的iteration-based分布式图框架进行random walk的生成,生成的序列有150个billion。 -
XTF平台使用100个GPU。 -
所有的步骤,包括日志查找,反垃圾过滤,图构建,random walk生成序列,embedding,相似度计算和图生成,可以在6个小时内计算完成。
总结与思考
本文的知识点包括:
-
用户行为序列构建商品图 -
Random Walk生成商品序列 -
Skip-gram学习商品Embedding -
附加信息解决冷启动 -
附加信息加权来增强效果
勤思考,多提问是Engineer的良好品德。
提问:
-
在图构建的过程中,在同一个用户一段时间内的操作历史中的商品都被用来构建图,但是在一段时间内,用户也可能有多个兴趣,所以这样构建图是否合理? -
skip-gram的学习方式越来越多的被Bert类算法替代,这个场景下有没有可能应用Bert,如何做
加上个讨论区,大家有想法可以在这里回复。
参考文献
-
[1]. Wang, Jizhe, et al. "Billion-scale commodity embedding for e-commerce recommendation in alibaba." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




