复杂数据处理(下):1816-2013年拉萨年平均气温变化分析(附数据集)

作者:郭小龙,R语言中文社区专栏作者。知乎专栏:https://www.zhihu.com/people/guo-xiao-long-3-18/posts
公众号后台回复“西藏”下载数据集
西藏拉萨一直是很多人心目中向往的圣地,也是我心目中最想去的地方之一。蓝天白云、布达拉宫、藏传佛教等等,每年光顾的骑行者、旅游者以及佛教徒络绎不绝。作为中国受工业经济发展影响较少的城市,近百年来气候变化又如何呢?本文从年平均气温角度,用R语言简单分析了拉萨1816-2013年的年平均气温变化。
1、数据来源说明
研究数据来源于Kaggle网站的全球城市气温资料,其中包括全球主要国家大部分城市的气温、经纬度等信息(见下图)。本文研究的是拉萨1816-2013年的气温数据,计算平均气温时删去一年不够12个月的数据。
2、用R语言进行数据分析处理和绘图
(1)读取下载的CSV格式全球气温资料
###读取下载的全球城市气温数据
library(openxlsx)
readFilepath <- "G:/大数据作业实践和有用资料/第四关作业实践/下载环境数据/GlobalLandTemperaturesByCity.csv"
Temdata <- read.csv(readFilepath,header = TRUE,sep = ",")(2)数据预处理:选择子集
#选择子集
library(dplyr)
myData <- select(Temdata,
dt,AverageTemperature,City,Country)(3)数据预处理:删除缺失数据并选择拉萨
ChinaData <- filter(Temdata,
!is.na(AverageTemperature),
!is.na(City),
!is.na(Country),
Country == "China",
City == "Lasa")
ChinaData <- select(ChinaData,
dt,AverageTemperature,City)(4)数据预处理:对列进行拆分和重命名
#对列进行拆分和重命名
library(stringr)
timeDate <- str_split_fixed(ChinaData$dt,"-",n = 3)
ChinaData$dt <- timeDate[,1] #想要实现把1986-03-01分解成年月日3列,后面继续研究
ChinaData$dt <- as.numeric(ChinaData$dt) #年字符段转换为数值型,这一步非常重要,否则影响后续分组计算
ChinaData <- rename(ChinaData,AveT = AverageTemperature)(5)数据的分组和计算
###数据按年份进行分组并计算
#按年份进行分组
Year_data <- group_by(ChinaData,dt)
TLasa <- summarise(Year_data,
count = n(),
T = mean(AveT,na.rm = TRUE))
TLasa <- filter(TLasa,count > 11)(6)数据的图形绘制
###数据图形显示
library(ggplot2)
ggplot(data = TLasa) +
geom_point(mapping = aes(x = dt,y = T)) +
geom_smooth(mapping = aes(x = dt,y = T))(7)结论
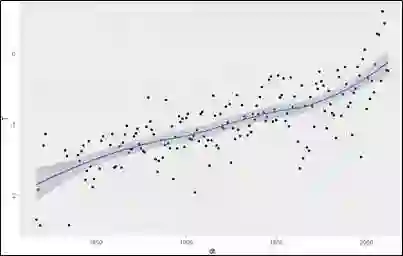
从1816年至2012年(上图横坐标表示年份,纵坐标表示温度),随着时间的推移,拉萨年平均气温呈逐年上升的趋势,并且从90年代开始呈加速上升趋势。
3、收获和总结
(1)本次学习解决了打开RStudio文件时中文乱码问题。通过在弹出的编码中,选择UTF-8编码,具体方法如下。

(2)代码写好后运行没错,但再打开时前面总出现感汉号。是因为Tool—Global Options—code—中“变量没有定义是否报警”或“变量有定义但是没有使用进行提示”被选中。我个人觉得这个提示符号特别不舒服,坚决去掉^_^^_^^_^

(3)R语言特有的诊断(如空格的提示),对养成良好的代码习惯编写很有帮助,强烈建议选中code界面中“Provide R style diagnostics”选项。
(4)dplyr包的管道函数(%>%)省略了中间的赋值步骤,在初期学习代码相对简单情况下可能用处不大,但随着代码复杂时管道函数的作用会越来越大。
(5)数据处理的模块化思维和代码的断点调试等知识,是贯穿程序语言学习始终的。这块知识属于方法论,后续学习中一定要逐步实践实践再实践。

公众号后台回复关键字即可学习
回复 R R语言快速入门免费视频
回复 统计 统计方法及其在R中的实现
回复 用户画像 民生银行客户画像搭建与应用
回复 大数据 大数据系列免费视频教程
回复 可视化 利用R语言做数据可视化
回复 数据挖掘 数据挖掘算法原理解释与应用
回复 机器学习 R&Python机器学习入门



