比可微架构搜索DARTS快10倍,第四范式提出优化NAS算法
机器之心发布
神经架构搜索一直被认为是高算力的代表,尽管可微架构搜索的概念非常吸引人,但它目前的效率与效果仍然不尽人意。在最近的 AAAI 2020 中,第四范式提出了一种基于临近迭代(Proximal Iterations)的 NAS 方法,其速度比 DARTS 快了 10 倍以上。

论文:https://arxiv.org/abs/1905.13577
代码:https://github.com/xujinfan/NASP-codes
视频:https://www.tuijianxitong.cn/cn/school/video/26
PPT:https://www.tuijianxitong.cn/cn/school/openclass/27
论文:https://arxiv.org/pdf/1906.12091
代码:https://github.com/quanmingyao/SIF

-
除了以往 NAS 普遍讨论的搜索空间、完备性和模型复杂度之外,该工作确定了一个全新且重要的一个因素,即 NAS 对体系结构的约束; -
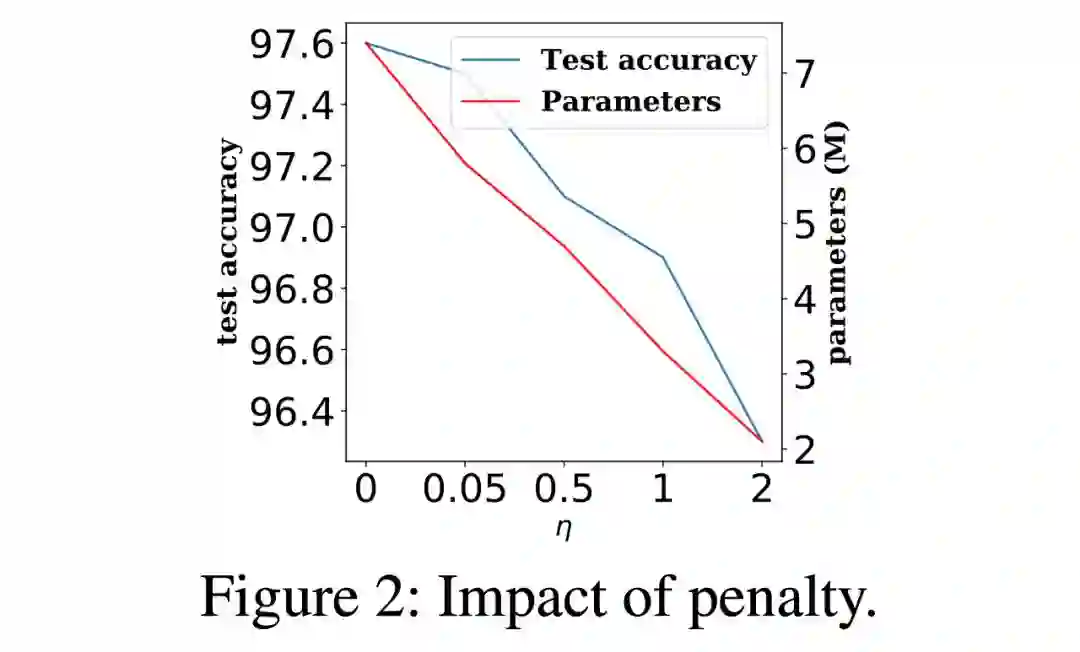
我们将 NAS 描述为一个约束优化问题,保持空间可微,但强制架构在搜索过程中是离散的,即在反向梯度传播的时候尽量维持少量激活的操作。 这有助于提高搜索效率并在训练过程中分离不同的操作。 正则化器也被引入到新目标中,从而控制网络结构的大小; -
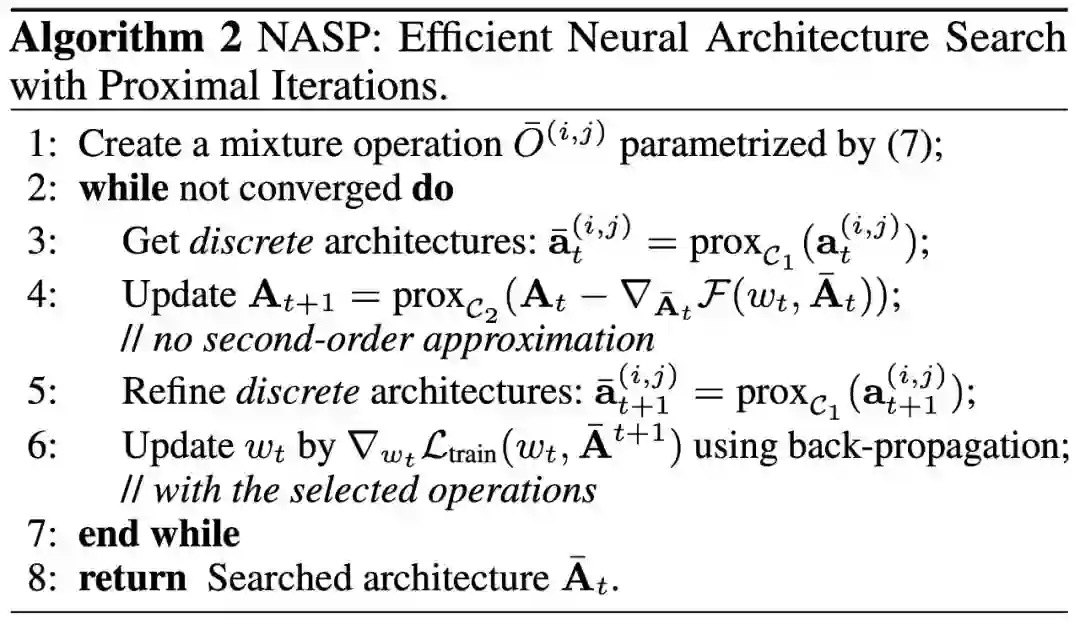
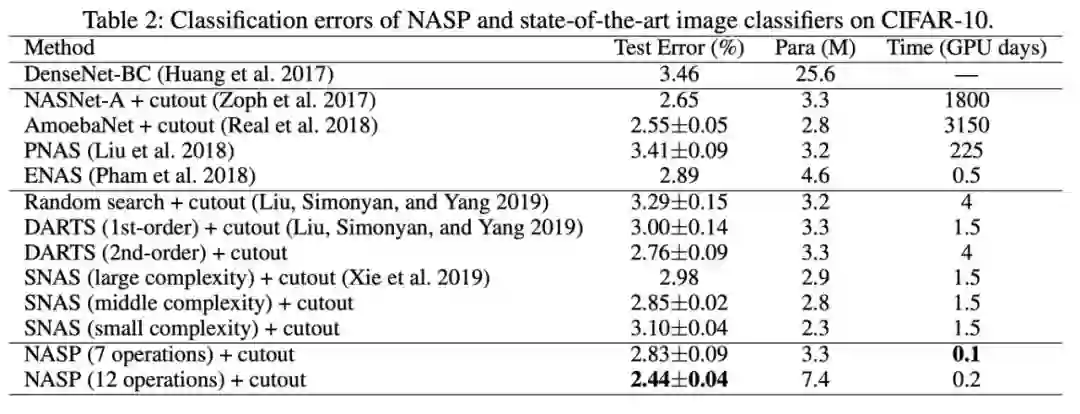
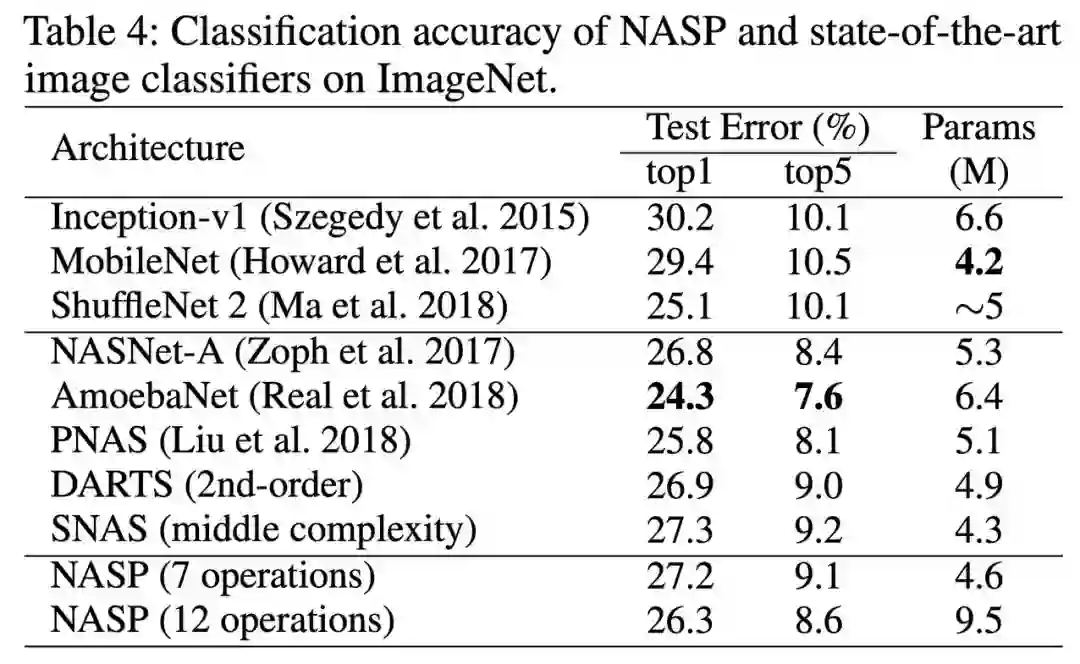
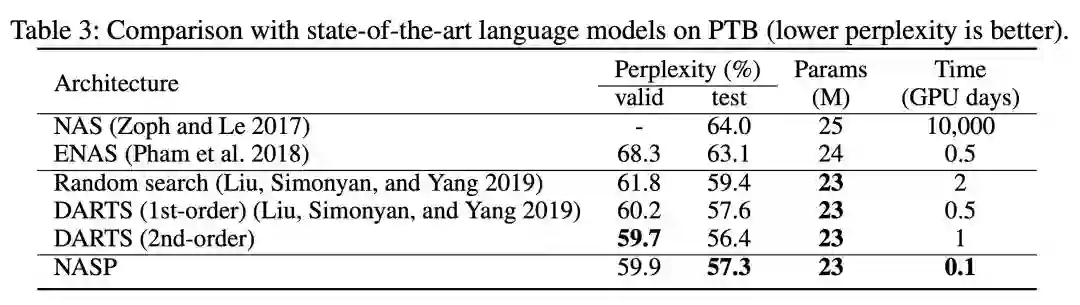
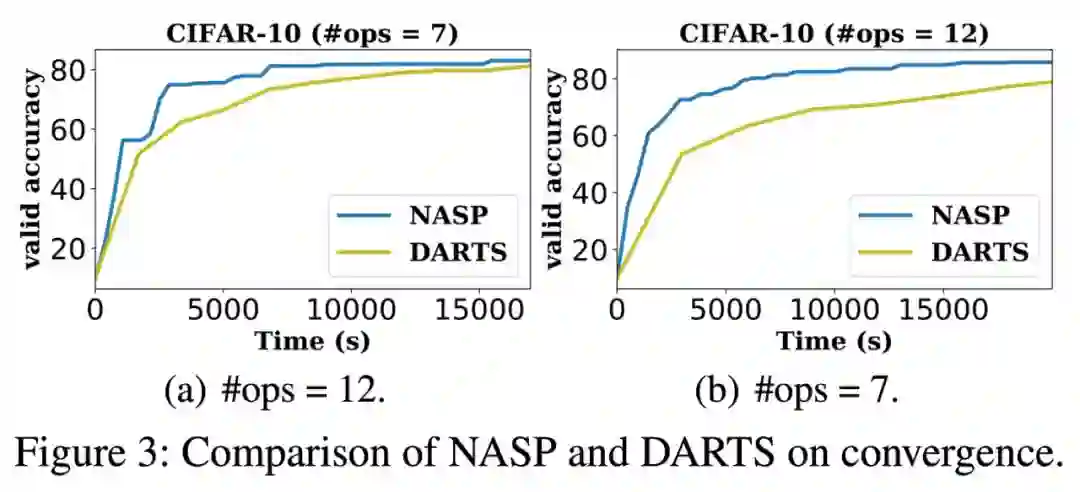
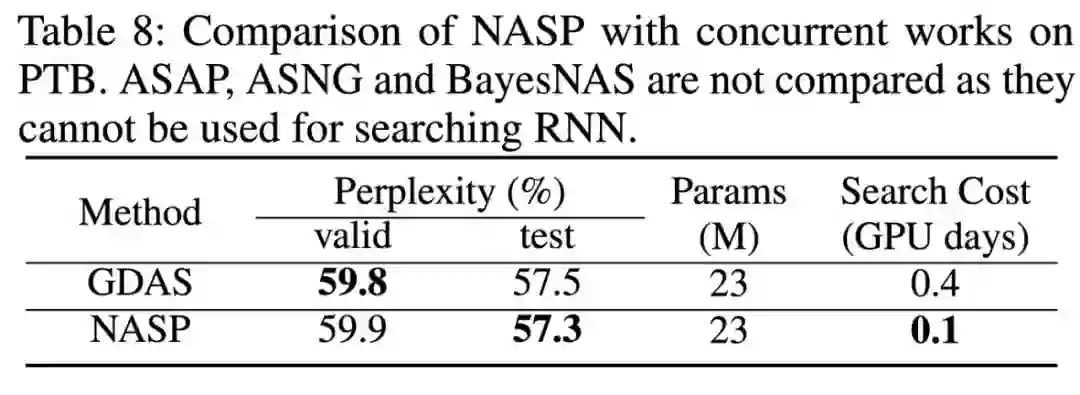
由于这种离散约束难以优化,且无法应用简单的 DARTS 自适应。 因此,第四范式提出了一种由近端迭代衍生的新优化算法,并且消除了 DARTS 所需的昂贵二阶近似,为保证算法的收敛性,我们更进一步进行了理论分析。 最后,在设计 CNN 和 RNN 架构时,使用各种基准数据集进行了实验。与最先进的方法相比,提出的 NASP 不仅速度快(比 DARTS 快 10 倍以上),而且可以发现更好的模型结构。实验结果表明,NASP 在测试精度和计算效率上均能获得更好的性能。

登录查看更多
相关内容
专知会员服务
57+阅读 · 2020年3月13日



相关VIP内容
专知会员服务
57+阅读 · 2020年3月13日
相关资讯
相关论文