选自谷歌博客
作者:Michael S. Ryoo、AJ Piergiovanni
参与:王子嘉、Geek AI
近年来,针对图像任务的神经网络架构搜索(NAS)逐渐成为了各大研究机构和业界关注的「明星技术」。然而,针对视频理解的神经网络架构搜索却由于其在时空上的复杂性而鲜为研究人员所涉及。
近日,来自谷歌机器人的研究科学家 Michael S. Ryoo 和实习研究员 AJ Piergiovanni 连续发文介绍了他们在视频理解网络 NAS 方面的工作,对于该领域的研究具有很强的引领作用。
![]()
视频理解是一个极具挑战性的问题。因为视频包含时空(Spatio-temporal)数据,所以需要通过特征表征同时提取其静态表观信息和画面动态信息。这不仅对于自动理解视频的语义内容(如网络视频分类或体育活动识别)是必不可少的,而且对于机器人的感知和学习也十分关键。与人类相类似,机器人摄像头的输入一般很少是对世界的「静态快照」,而是连续的视频。
现在的深度学习模型的性能在很大程度上依赖于它们的网络架构。用于处理视频的卷积神经网络(CNN)一般是手动地将人们熟知的二维架构(如 Inception 和 ResNet)扩展成三维架构,或者是通过精心设计一种将静态表观信息和画面动态信息融合在一起的双流 CNN 架构(two-stream CNN)而实现的。然而,设计一个能够充分利用视频中的时空信息的理想视频架构仍然是一个有待探索的问题。
对于图像任务来说,尽管用于探索性能优秀的网络架构的神经架构搜索(NAS)方案(如 Zoph 等人发表的「Using Machine Learning to Explore Neural Network Architecture」,与 Real 等人发表的「Using Evolutionary AutoML to Discover Neural Network Architectures」)已经被广为研究,但是用于视频任务的神经网络架构的自动优化方案(machine-optimized neural architectures)尚未被研究。用于视频的 CNN 通常需要大量的计算和内存,因此设计一种既能表征其独特的属性,又能进行有效搜索的方法非常困难。
为了应对这些挑战,我们针对更理想的视频理解网络架构的自动搜索进行了一系列研究。
我们展示了三种不同的神经架构演化算法:学习层及其模块配置的 EvaNet,学习多流连接的 AssembleNet,以及构建计算高效的简洁网络的 TinyVideoNet。
我们开发的视频架构在多个公共数据集上的性能明显优于现有的手动设计的模型,并证明了我们的网络运行时间可减少至 1/10 至 1/100。
我们在 ICCV 2019 上提出了「Evolving Space-Time Neural Architectures for Videos」(EvaNet),这是对于视频神经网络架构搜索设计的首次尝试。
![]()
EvaNet 是一个模块级的架构搜索方法,主要关注查找时空卷积层的类型以及它们的最佳串行或并行计算配置。本算法使用带有突变操作符的演化算法进行搜索,迭代地更新结构的「种群」。这使得对搜索空间的并行化的、更高效的探索成为了可能,也是视频架构搜索考虑不同时空层及其组合的必要条件。EvaNet 中开发了多个模块(在网络中的不同位置)来生成不同的架构。
我们的实验结果证实了通过演化异构模块获得的此类视频 CNN 架构的优点。该方法发现,由多个并行层组成的重要模块效率通常是最高的,因为它们比手动设计的模块更快,性能更好。
另一个值得注意的方面是,由于使用了演化策略,我们获得了许多性能相似但结构各异的架构,并且无需进行额外的计算。对这些模型进行集成可以进一步提高他们的性能。由于它们的并行特性,即使是集成模型也比(2 + 1)维的 ResNet 这样的标准视频网络在计算上更加高效。
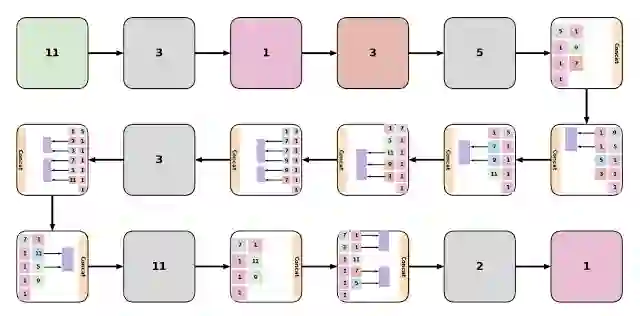
![]()
EvaNet 产生的不同架构示例。每个大彩色框和小的彩色框都代表一个网络层,框的颜色代表其类型:蓝色代表三维卷积,橙色代表(2 + 1)维卷积,绿色代表 iTGM,灰色代表最大池化,紫色代表平均,粉色代表 1x1 的卷积。各个层一般会被分组成模块(大一点的框)。每个框中的数字表示卷积核(filter)的大小。
AssembleNet:建立更强更好的(多流)模型
在论文「AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures (https://arxiv.org/abs/1905.13209)」中,我们研究了一种将具有不同输入模态(如 RGB 和光流)的不同的子网络和时间分辨率融合在一起的新方法。
![]()
论文链接:https://arxiv.org/abs/1905.13209
AssembleNet 是一系列可学习的网络架构,它们提供了一种学习跨输入模态的特征表征之间「连通性」的通用方法,同时针对目标任务进行了优化。
我们提出了一种通用方法,可以将各种形式的多流 CNN 表征为有向图,并结合一个高效的演化算法来探索高级网络连接。这样做是为了从视频中学习到更好的关于静态表观和动态画面视觉线索的特征表征。
与以前使用后期融合或固定中间融合的手工设计的双流模型不同,AssembleNet 可以演化出很多过度连接、多流且多分辨率的架构,并通过对连接权重的学习引导突变。我们正首次研究具有各种中间连接的四流架构——每个 RGB 和光流都有 2 个流,每个流具有不同的时间分辨率。
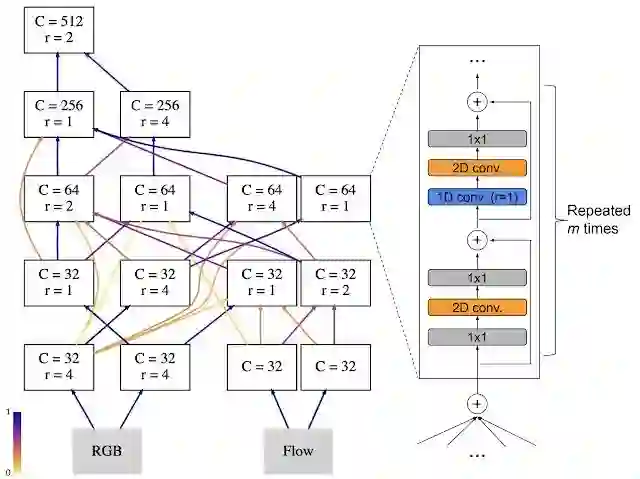
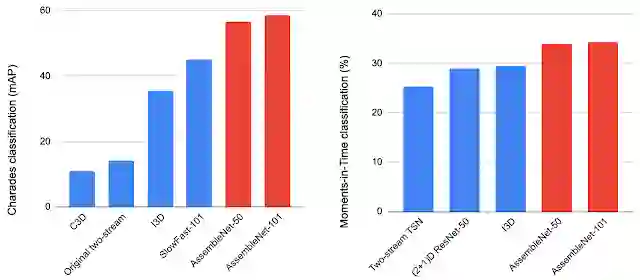
下图展示了一个 AssembleNet 架构示例,它是通过对一组随机初始化的多流架构进行 50 到 150 轮的演化发现的,我们在两个非常流行的视频识别数据集 Charades 和 Moments-in-Time(MiT) 上测试了 AssembleNet。AssembleNet 在 MiT 上的性能位列第一,准确率超过 34%。在 Charades 中它的表现更让人吃惊,平均准确率(mAP)达到了 58.6%,而之前为人所知的最佳结果是 42.5% 和 45.2%。
![]()
使用 MiT 数据集进行演化的代表性 AssembleNet 模型。一个节点对应一个时空卷积层模块,每条边代表它们的连通性。较暗的边缘意味着较强的连接。AssembleNet 是一组可学习的多流架构,针对特定目标任务进行优化。
![]()
在 Charades(左)和 MiT(右)数据集上,将 AssembleNet 与最先进的手动设计的模型进行了比较。AssembleNet-50 与 AssembleNet-101 的参数量和双流 ResNet-50 与 ResNet-101 相当。
Tiny Video Networks:最快的视频理解网络
![]()
论文链接:https://arxiv.org/abs/1910.06961
为了使视频 CNN 模型在现实世界的设备上(如机器人所需的设备)上能够正常运行,必须进行实时、高效的计算。但是,要在视频识别任务上取得目前最先进的结果,需要非常大的网络,通常具有数十到数百个卷积层,这些卷积层将被应用于大量的输入帧上。这也就导致了这些网络的运行时间通常很长,对长度为 1 秒的视频片段进行识别至少需要在现在的 GPU 上运行 500+ ms 以上的时间,在 CPU 上则至少需要 2000+ ms。
在 Tiny Video Networks 中,我们通过自动设计的网络取得了不错的性能,而其计算成本却大大降低。
我们的 Tiny Video Networks(TinyVideoNets)有很高的准确率和运行效率,能够以实时或更高的速度高效运行。要想识别大约 1 秒钟的视频片段,在 CPU 上只需要运行 37 至 100 ms,在 GPU 上只需要运行 10 ms,比以前手动设计的网络快了数百倍。
我们通过在架构的演化过程中明确定义模型运行时间,并限制算法探索的搜索空间(同时包括空间和时间分辨率以及通道大小),大大减少了计算量,从而实现了性能的提升。
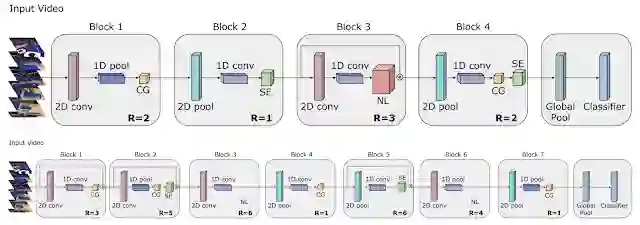
下图说明了 TinyVideoNet 发现的两种简单但非常有效的网络架构。有趣的是,本算法学习到的模型架构比经典的视频架构的卷积层数更少:因为 Tiny Video Networks 更倾向于轻量级元素,例如二维池化,门控层和挤压激发(squeeze-and-excitation)层。此外,TinyVideoNet 能够同时优化参数和运行时间,以提供可用于未来网络探索的高效网络。
![]()
经过演化得到的 TinyVideoNet(TVN)架构,可以最大限度地提高识别性能,同时将计算时间保持在限制时间之内。例如,TVN-1(上面一列)在 CPU 上的运行时间为 37 毫秒,在 GPU 上的运行时间为 10 毫秒。TVN-2(下面一列)在 CPU 上的运行时间为 65 毫秒,在 GPU 上的运行时间为 13 毫秒。
![]()
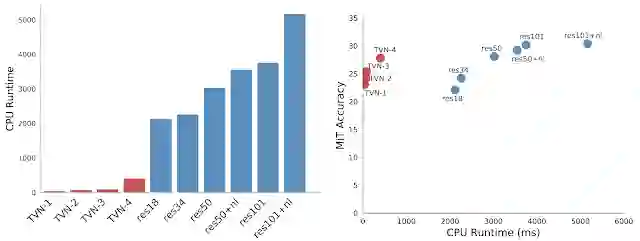
左图是 TinyVideoNet 模型与以前的模型的 CPU 运行时间对比图,右图是 TinyVideoNet 模型与(2+1)维 ResNet 模型关于运行时间和模型准确率的对比图。
值得注意的是,TinyVideoNets 的点只占了这个时间—准确率空间的一小部分(这部分空间中不存在其它模型),也就是说 TinyVideoNets 可以非常迅速地找到准确率很高的架构。
据我们所知,这是关于视频理解神经网络架构搜索第一项研究。我们用新型演化算法生成的视频架构在公共数据集上的表现要远远超过最著名的手动设计的 CNN 架构。我们还证明了通过学习得到计算效率高的视频模型(TinyVideoNets)是可行的。这项研究开辟了新的研究方向,并说明自动演化的 CNN 在视频理解任务中有很好的研究前景。
原文链接:
https://ai.googleblog.com/2019/10/video-architecture-search.html
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com