文本挖掘从小白到精通(二十二)短文本主题建模的利器 - BERTopic

文本挖掘从小白到精通(一)---语料、向量空间和模型的概念
文本挖掘从小白到精通(三)---主题模型和文本数据转换
文本挖掘从小白到精通(五)---主题模型的主题数确定和可视化
文本挖掘从小白到精通(六)---word2vec的训练、使用和可视化
文本挖掘从小白到精通(七)--- Word2vec的增量学习
文本挖掘从小白到精通(八)--- 从海量文章中挖掘主要观点
文本挖掘从小白到精通(九)--- 文本相似性度量
文本挖掘从小白到精通(十)--- 不需设定聚类数的Single-pass
文本挖掘从小白到精通(十一)--- 不需设定聚类数的DBSCAN
文本挖掘从小白到精通(十二)--- 7种简单易行的文本特征提取方法
文本挖掘从小白到精通(十三)--- 文本挖掘中会涉及的若干降维方法
文本挖掘从小白到精通(十四)--- 如何将训练所得的word2vec模型用于后续任务
文本挖掘从小白到精通(十五)--- NLP小白也能轻松学会的BERT使用指南
文本挖掘从小白到精通(十六)--- 像使用scikit-learn一样玩转BERT
文本挖掘从小白到精通(十七)--- 只有少量标注文本数据怎么办?
文本挖掘从小白到精通(十八)---文本层次聚类
文本挖掘从小白到精通(十九)--- 目前有比Topic Model更先进的聚类方式么
文本挖掘从小白到精通(二十)- 如何更有效率的加载大型词嵌入模型?
文本挖掘从小白到精通(二十一)如何使用造好的轮子快速实现各项文本挖掘任务
【特辑】文本分类算法集锦,从小白到大牛,附代码注释和训练语料
-
如何对大量的短文本数据进行高效建模? -
在LDA建模时,如何确定主题数? -
主题模型得到的结果解释性程度不高、看不懂咋办?
1 载入需要的python库
import numpy as npimport pandas as pdimport jiebaimport umapimport hdbscanfrom sentence_transformers import SentenceTransformerfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.metrics.pairwise import cosine_similarityfrom tqdm import tqdmimport matplotlib.pyplot as plt
笔者在这里使用的是汽车之家的口碑评论数据,有20000+,大部分是长度不超过70的短文本数据。
from pyltp import SentenceSplitterdata = pd.read_excel('car_reviews.xlsx')data[['review']]= data[['review']].values.astype(str)splited_sentences = SentenceSplitter.split(' '.join(data['review'].tolist()))data = pd.DataFrame(list(splited_sentences), columns=["review"])
data['text_length'] = data["review"].apply(lambda x:len(x))
data = data[data['text_length']>5]
data.head()
对文本数据进行分词处理,同时排除语句中的停用词。
data['review_seg'] = data['review'].apply(lambda x : ' '.join([j.strip() for j in jieba.lcut(x) if j not in my_stopwords]))
data.head()
model = SentenceTransformer(r'gao_dir/my_pretrained_chinese_embeddings')embeddings = model.encode(data['review'].tolist(), show_progress_bar=True)
embeddings.shape
(9445, 512)
4 句嵌入降维处理
%%timeimport syssys.setrecursionlimit(1000000)umap_embeddings = umap.UMAP(n_neighbors=25,n_components=10,min_dist=0.00,metric='cosine',random_state=2020).fit_transform(embeddings)
Wall time: 53.5 s
metric。此次笔者使用的度量方式是是euclidean(欧氏度量),因为它不会受到高维度的影响
min_cluster_size。min_cluster_size(最小聚类大小)可以让调节主题数量,该数值越大,则发掘出的主题数量就越少,反之越多。
%%timecluster = hdbscan.HDBSCAN(min_cluster_size=30,metric='euclidean',cluster_selection_method='eom',prediction_data=True).fit(umap_embeddings)
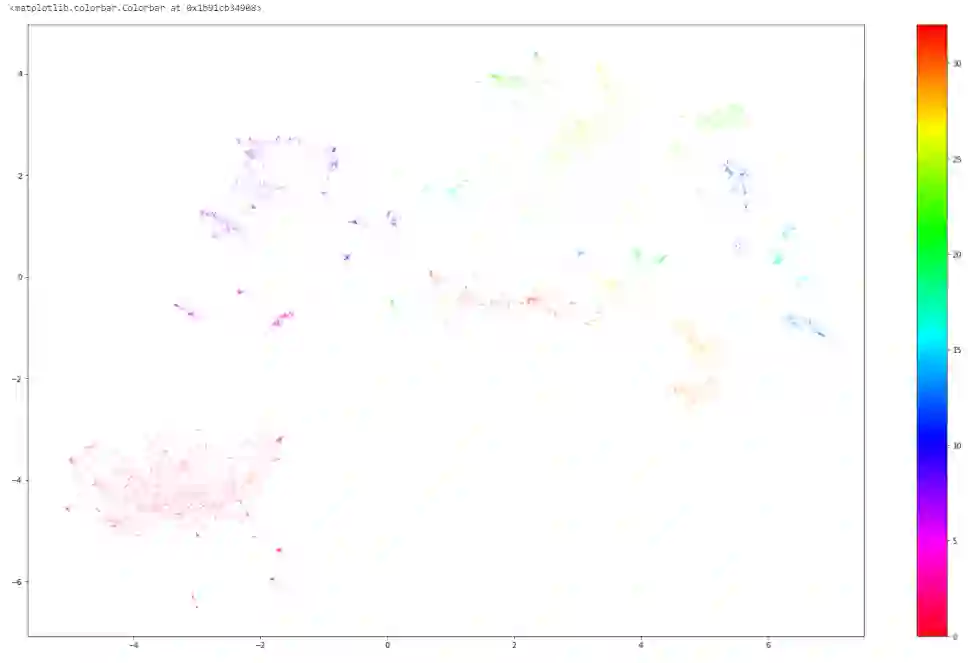
我们可以通过使用UMAP将数据嵌入到二维空间,并使用matplotlib对聚类进行着色,从而将产生的聚类可视化。有些聚类很难被发现,因为可能会有>50个主题生成,但一些主题下的语句数(在图中就是小点数)过少。
# Prepare data
umap_data = umap.UMAP(n_neighbors=15, n_components=2, min_dist=0.0, metric='cosine').fit_transform(embeddings)
result = pd.DataFrame(umap_data, columns=['x', 'y'])
result['labels'] = cluster.labels_
# Visualize clusters
fig, ax = plt.subplots(figsize=(25, 15))
outliers = result.loc[result.labels == -1, :]
clustered = result.loc[result.labels != -1, :]
plt.scatter(outliers.x, outliers.y, color='#BDBDBD', s=0.05)
plt.scatter(clustered.x, clustered.y, c=clustered.labels, s=0.05, cmap='hsv_r')
plt.colorbar()
# plt.savefig("result1.png", dpi = 300)
def c_tf_idf(documents, m, ngram_range=(1, 1)):my_stopwords = [i.strip() for i in open('stop_words_zh.txt',encoding='utf-8').readlines()]count = CountVectorizer(ngram_range=ngram_range,stop_words= my_stopwords).fit(documents)t = count.transform(documents).toarray()w = t.sum(axis=1)tf = np.divide(t.T, w)sum_t = t.sum(axis=0)idf = np.log(np.divide(m, sum_t)).reshape(-1, 1)tf_idf = np.multiply(tf, idf)return tf_idf, count
def extract_top_n_words_per_topic(tf_idf, count, docs_per_topic, n=20):words = count.get_feature_names()labels = list(docs_per_topic.Topic)tf_idf_transposed = tf_idf.Tindices = tf_idf_transposed.argsort()[:, -n:]top_n_words = {label: [(words[j], tf_idf_transposed[i][j]) for j in indices[i]][::-1] for i, label in enumerate(labels)}return top_n_wordsdef extract_topic_sizes(df):topic_sizes = (df.groupby(['Topic']).Doc.count().reset_index().rename({"Topic": "Topic", "Doc": "Size"}, axis='columns').sort_values("Size", ascending=False))return topic_sizes
docs_df = pd.DataFrame(data['review_seg'].tolist(), columns=["Doc"])docs_df['Topic'] = cluster.labels_docs_df['Doc_ID'] = range(len(docs_df))docs_per_topic = docs_df.groupby(['Topic'], as_index = False).agg({'Doc': ' '.join})
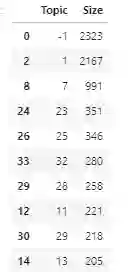
此次产生的主题数为:
len(docs_per_topic.Doc.tolist())tf_idf, count = c_tf_idf(docs_per_topic.Doc.values, m = len(data))top_n_words = extract_top_n_words_per_topic(tf_idf, count, docs_per_topic, n=20)topic_sizes = extract_topic_sizes(docs_df); topic_sizes.head(10)
看看主题索引为18的主题下的主题词是哪些:
top_n_words[18]
[('问题', 0.1025568295028655),
('没有', 0.09461670245949808),
('追评', 0.08719721082551075),
('目前', 0.07247799984688022),
('发现', 0.06975059757614206),
('时间', 0.06712798723943217),
('再来', 0.05536254179522642),
('味道', 0.05231485606815352),
('满意', 0.04991319860040351),
('感觉', 0.04842748742196347),
('出现', 0.04813242930859443),
('一个月', 0.046830037344296443),
('月份', 0.04624729052000483),
('新车', 0.04403148698556992),
('异味', 0.04383294309480369),
('暂时', 0.04334722860887084),
('车开', 0.04318017756299482),
('现在', 0.04022216122961403),
('质量', 0.038859284264954115),
('提车', 0.035243555499171186)]
top_n_words[-1]
[('外观', 0.03397788540335169),
('喜欢', 0.028063470565283518),
('性价比', 0.024877802099763188),
('觉得', 0.02017027908469892),
('感觉', 0.019562629459711357),
('没有', 0.01852212424611342),
('大灯', 0.018513381594025758),
('配置', 0.018280959393705866),
('比较', 0.017890116980130752),
('价格', 0.017679624613747016),
('非常', 0.017142161266788858),
('品牌', 0.017058422370475335),
('满意', 0.016970659727685928),
('豪华', 0.016424003887498418),
('优惠', 0.01609247609255133),
('xts', 0.01579185209861865),
('设计', 0.015732793408522044),
('动力', 0.01541712071670732),
('大气', 0.014732855459186593),
('有点', 0.014718071299553026)]
from pprint import pprint
for i in list(range(len(top_n_words) - 1)):
print('Most 20 Important words in TOPIC {} :\n'.format(i))
pprint(top_n_words[i])
pprint('***'*20)
Most 20 Important words in TOPIC 0 :
[('马儿', 0.24457507362737524),
('马儿跑', 0.2084888573356569),
('不吃', 0.09709590737397493),
('油耗', 0.06709136386307156),
('目前', 0.059650379616285276),
('不让', 0.05319169690659243),
('想要', 0.04764441180247841),
('左右', 0.046580524081679016),
('跑得快', 0.045400507911056986),
('哪有', 0.044559365280351336),
('公里', 0.041230968367632854),
('高速', 0.039234425817170064),
('行驶', 0.03890482349013843),
('10', 0.037022144019066686),
('个油', 0.03682216481709768),
('动力', 0.03616975159734934),
('正常', 0.03520558703001095),
('市区', 0.034599821025087185),
('毕竟', 0.03458202416009574),
('道理', 0.031503940772350914)]
'************************************************************'
Most 20 Important words in TOPIC 1 :
[('油耗', 0.09524385306084004),
('高速', 0.05653143388720487),
('左右', 0.05463694726066372),
('市区', 0.04736812727722961),
('公里', 0.04426042823825784),
('个油', 0.0437019462752025),
('10', 0.04124126267133629),
('目前', 0.04106957747526032),
('接受', 0.03392843290427474),
('11', 0.03258066460138708),
('平均', 0.03254166004110595),
('百公里', 0.026974405367215754),
('12', 0.02667734417832382),
('现在', 0.026547861579869568),
('省油', 0.024521146178990254),
('比较', 0.023967370074638887),
('行驶', 0.02337617146923143),
('平时', 0.02231213384456322),
('开车', 0.02225259142975045),
('磨合期', 0.019891589132560176)]
'************************************************************'
Most 20 Important words in TOPIC 2 :
[('老虎', 0.1972807028214997),
('油耗', 0.08030819950496665),
('美系车', 0.051452721555236586),
('现在', 0.04511691339526969),
('10', 0.04164581302410513),
('个油', 0.041420858563077104),
('美国', 0.04121728175026878),
('左右', 0.03493195487672415),
('平均', 0.03288881578728298),
('目前', 0.029076698183196633),
('12', 0.028824764053369055),
('高速', 0.028687350320703176),
('11', 0.0263147428710808),
('基本', 0.025791405022289656),
('百公里', 0.025566436389413978),
('驾驶', 0.02511085197343242),
('郊区', 0.023879719505057788),
('多公里', 0.023290821021098026),
('习惯', 0.023170932368572476),
('朋友', 0.022668297504425915)]
'************************************************************'
Most 20 Important words in TOPIC 3 :
[('油耗', 0.09774756730680972),
('凯迪拉克', 0.08150929317053307),
('左右', 0.03704063760365755),
('个油', 0.03393914525278086),
('节油', 0.033147790968701116),
('目前', 0.029322670672030947),
('耗油', 0.028607158460688595),
('市区', 0.028138942560105483),
('11', 0.027057690984927343),
('接受', 0.027035026157737122),
('毕竟', 0.025713800165879153),
('现在', 0.025636969123009515),
('美系车', 0.025507957831906663),
('平均', 0.02536302802175033),
('之前', 0.024645241362404695),
('动力', 0.023532574041308225),
('比较', 0.02351138127209341),
('降低', 0.021912206107234797),
('正常', 0.02137825605852441),
('可能', 0.02017083805610775)]
'************************************************************'
Most 20 Important words in TOPIC 31 :
[('满意', 0.4749794864152499),
('地方', 0.3926757136985932),
('没有', 0.21437689162047083),
('发现', 0.17910831839903818),
('目前', 0.11420499815982257),
('暂时', 0.09540746799339411),
('挖掘', 0.08502606632538356),
('不好', 0.06606868576085345),
('满满', 0.06546918040522966),
('挑剔', 0.06351786367717983),
('后续', 0.05924768082325757),
('其实', 0.05517858296374464),
('没什么', 0.0467681518553301),
('真的', 0.04629681210390699),
('癫得', 0.04599618482379703),
('我太多', 0.04599618482379703),
('定为', 0.04599618482379703),
('3w', 0.04599618482379703),
('能吐槽', 0.04599618482379703),
('相对', 0.045510230820616476)]
'************************************************************'
Most 20 Important words in TOPIC 32 :
[('外观', 0.19202697740762065),
('喜欢', 0.09742663275691509),
('好看', 0.06539925997592003),
('吸引', 0.051963718413741596),
('时尚', 0.04628469650846298),
('大气', 0.045441921472445655),
('个性', 0.0447603686071089),
('个人', 0.03601467530065024),
('反正', 0.03586746904278288),
('霸气', 0.03438681357345092),
('不用', 0.03315500048740606),
('漂亮', 0.03302680521368137),
('外观设计', 0.032328941456855734),
('非常', 0.032326600304463396),
('外形', 0.03215438082478295),
('觉得', 0.03126961228563091),
('不错', 0.029505153223353325),
('看起来', 0.02949619921569243),
('顺眼', 0.026753843592622728),
('帅气', 0.026252936525869065)]
'************************************************************'
到了这里,主题发现的工作其实已经完结,但有时候,我们会觉得:
主题数过多,想要再少点,最好是按指定的数量进行相似主题合并;
发现主题中的层次结构会更有意义。
此时,就轮到主题归并出场了~
for i in tqdm(range(20)):
# Calculate cosine similarity
similarities = cosine_similarity(tf_idf.T)
np.fill_diagonal(similarities, 0)
# Extract label to merge into and from where
topic_sizes = docs_df.groupby(['Topic']).count().sort_values("Doc", ascending=False).reset_index()
topic_to_merge = topic_sizes.iloc[-1].Topic
topic_to_merge_into = np.argmax(similarities[topic_to_merge + 1]) - 1
# Adjust topics
docs_df.loc[docs_df.Topic == topic_to_merge, "Topic"] = topic_to_merge_into
old_topics = docs_df.sort_values("Topic").Topic.unique()
map_topics = {old_topic: index - 1 for index, old_topic in enumerate(old_topics)}
docs_df.Topic = docs_df.Topic.map(map_topics)
docs_per_topic = docs_df.groupby(['Topic'], as_index = False).agg({'Doc': ' '.join})
# Calculate new topic words
m = len(data)
tf_idf, count = c_tf_idf(docs_per_topic.Doc.values, m)
top_n_words = extract_top_n_words_per_topic(tf_idf, count, docs_per_topic, n=20)
topic_sizes = extract_topic_sizes(docs_df); topic_sizes.head(10)

-
用基于BERT的Sentence Transformers提取语句嵌入 -
通过UMAP和HDBSCAN,将文档嵌入进行聚类,语义相近的语句将聚集成簇群 -
用c-TF-IDF提取主题词
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏