3天上手,30天精通!—— 深度学习FPGA加速器设计
机器之心专栏
作者:Pooterko
本文的目标是帮助对于深度学习硬件加速器设计感兴趣的朋友快速上手基于 FPGA 的深度学习加速器设计。
准备
以下是阅读本文的基础,请做好下列基础准备后再上手加速器设计:
C 语言设计:熟练掌握 C 语言语法。
计算机体系结构知识:参考书《计算机组成与设计》,不需要熟读全书,但要对一些加速器设计相关的基础概念有比较清晰的理解和认识,如流水线、数据并行等。
高层次综合
利用高层次综合工具,开发者只需要编写高级语言的代码完成程序功能,就能将高级语言编写的代码综合成相同功能的 RTL 级实现 (基于 Verilog 或 VHDL)。开发者还可以通过添加一些 pragma 的方式来指示和调整高层次综合工具生成的硬件模块的架构。整体而言,利用高层次综合工具进行 FPGA 硬件开发的过程,应该是利用软件语言的表达来描述硬件模块的过程。目前,高层次综合的代码都是基于 C/C++/OpenCL 的,所以对于没有硬件设计基础的朋友来说,利用高层次综合工具可以大幅度地降低学习难度,缩短开发周期,加快设计迭代速度。
3 天入门实例
我们需要使用一个简单的实例来进行入门学习。既然目标是让大家快速上手深度学习加速器的硬件设计,那么我们的实战示例就选择使用目前最火爆、最具代表性的深度学习算法——卷积神经网络 (CNN)。
我们选取卷积神经网络前向计算中耗时最长的卷积操作作为我们加速设计的目标。接下来,需完成以下步骤:
1. 准备工作(1 天)下载 Xilinx Vivado HLS 或 Xilinx SDx 工具链,利用官方 User guide 熟悉软件工具的使用,包括:新建工程、配置工程参数、综合流程等。
2. 软件实现(1 天)实现卷积层的软件版本 (C 语言版本),并封装成一个顶层函数。综合实现,结合高层次综合工具的 report 和 analyze 工具分析理解所生成的硬件架构和预计性能。卷积运算的流程如下图所示:
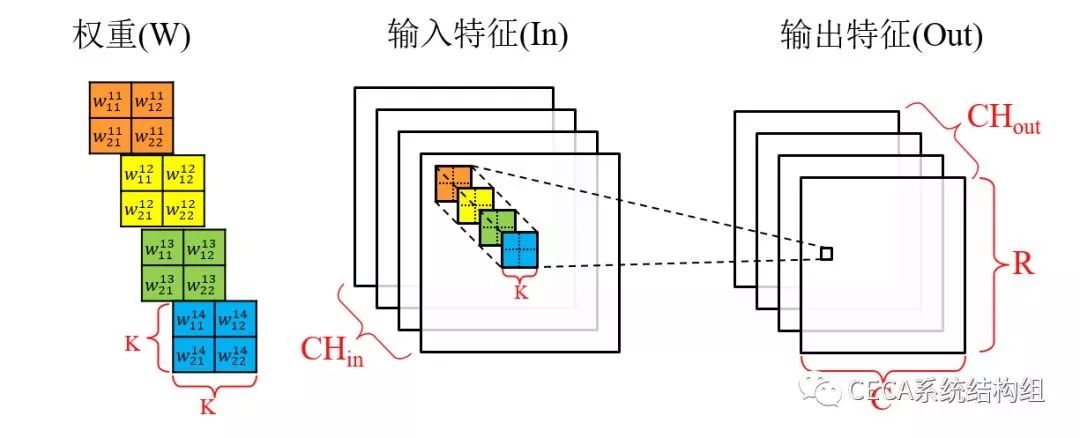
整个卷积层的输入是 CHin 张输入特征图,输出是 CHout 张输出特征图,每张输出特征图的大小为 R×C。由于每一个「输入-输出」特征图对都有一个特定的卷积核用于卷积计算,所以总共有 CHout×CHin 个卷积核,每个卷积核的大小为 K×K。在进行卷积计算的过程中,每个卷积核滑过各自的输入特征图,并使用当前滑过的窗口中的输入特征与卷积核内的权重完成卷积计算 (对应位置相乘,所有乘积累加),卷积的结果会累加到对应位置的输出特征上。因此,卷积计算的算法流程如下式所示:
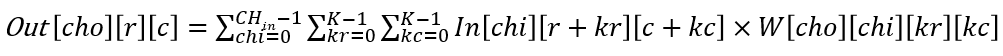
相应地,卷积层前向计算的软件版本代码如下所示:

本质上来说,卷积层前向计算的流程就是一个嵌套的 6 重循环,而在循环的最内层进行的是乘累加运算。在我们的示例中,我们用如下代码放入 HLS 工具中进行综合分析:

其中,数据类型我们指定为单精度浮点 (float),网络层参数如下:

设置硬件周期为 10ns,在 Vivado HLS 2018.3 中综合得到该模块运行延迟和资源开销报告,其中延迟报告为 251376 个时钟周期(具体数字可能略有差异)。
3. HLS 优化(1 天)在实现了卷积层的软件版本后,我们可以尝试对该代码进行硬件并行优化,这里我们用一个简单的加速设计来帮助大家理解 HLS 的优化方法。从上面的卷积流程分析,我们不难发现:卷积计算过程中,不同通道的输入/输出特征图在参与计算的过程中没有数据依赖关系,因而是可以并行处理的。在我们这个简单的小例子中,我们计划将输入通道 (Input Channel Loop) 和输出通道 (Output Channel Loop) 这两个维度进行并行加速优化。因此,我们想要实现的加速器核心模块示意图如下:
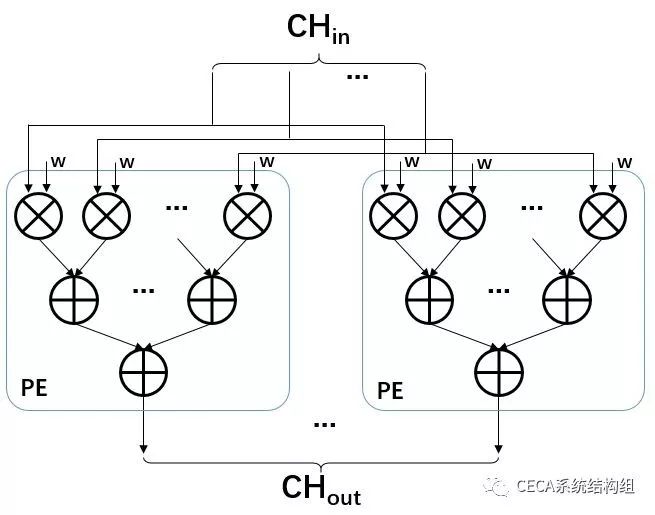
我们使用 CHin 个并行的乘法器来并行处理不同通道的输入特征与其对应权重的乘法,这些并行乘法的乘积累加到一起,即为一个输出通道的的卷积结果,这里,我们把该模块称为一个处理单元 (Processing Element,简称 PE,即上图中蓝色框部分)。一个 PE 只负责一个输出通道的卷积计算,我们可以把 PE 复制多份,形成上图的结构,来并行处理所有输出通道的卷积计算。总结来说,这个加速器调用一次可以并行处理包含 CHin 个输入特征点和 CHout 个输出特征点的卷积计算,而其中所有输入特征点都属于不同的输入通道,输出特征点也分属于不同的输出通道。要完成整个卷积层 6 重循环的计算,我们需要重复多次调用这个加速器。
现在我们就需要使用 HLS 来将上文设计的加速器描述出来,主要进行的代码改动包括以下三部分:
循环重构:由于我们的加速器是在输入通道和输出通道两个维度进行并行化,完成卷积计算需重复调用加速器多次,因此,我们需要将输入通道循环和输出通道循环放在最内层循环中。由于最内层的乘累加操作满足结合律,卷积的 6 重循环的顺序可以直接调整,而无需其它改动。
数组划分:从上面加速器设计我们可以看出,我们需要并行地访问输入特征 (In)、输出特征 (Out) 和权重 (W),而对应的并行度分别为 CHin、CHout 和 CHout×CHin。因此,在 FPGA 实现的时候,我们需要将这些数据划分到多个 RAM 块中以满足并行访问的需求。我们可以使用 Array Partition 来完成数组划分,该 pragma 的具体语法请参考 Xilinx 官方文档。
循环展开:为了描述出我们的加速器在输入通道和输出通道两个维度进行了并行优化,我们需要使用 pragma UNROLL 来将这两个循环完全展开,pragma UNROLL 的具体语法请参考 Xilinx 官方文档。
综合上述改动后,我们的代码如下所示:
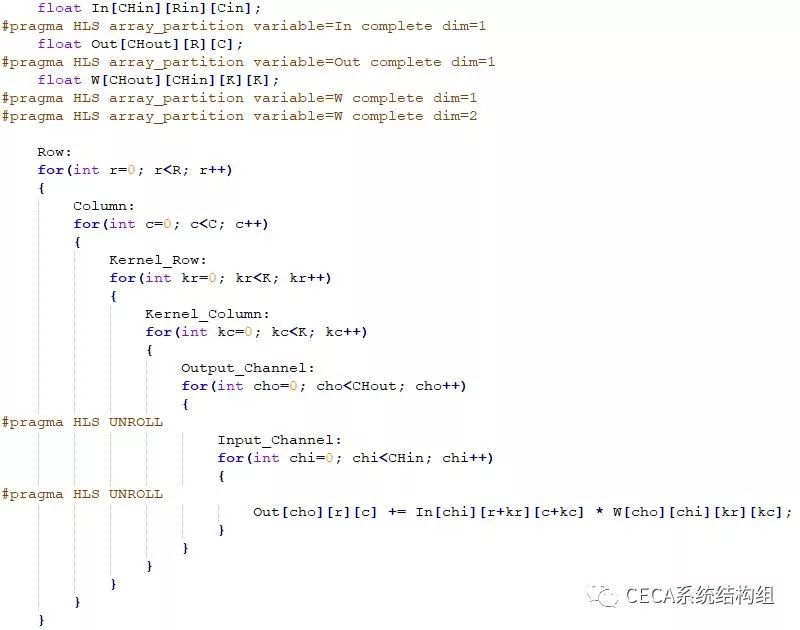
在 HLS 工具中重新综合,我们可以发现延迟降到了 36876 个时钟周期 (具体数字可能略有差异),有了 6.82 倍的加速效果。但当我们仔细看 HLS 的综合报告时可以发现,虽然我们实现了一个并行加速器,可是这个加速器调用并没有流水化起来:
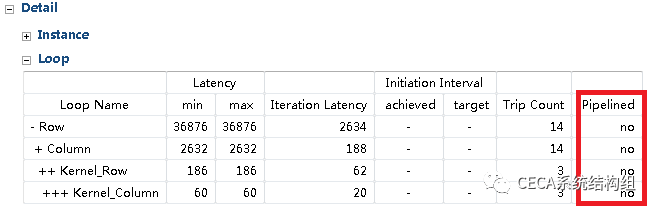
因此,我们可以尝试进一步优化提升性能:使用 pragma PIPELINE 将加速器设计流水化起来,该 pragma 的具体语法请参考 Xilinx 官方文档。在使用 pragma PIPELINE 以后,之前的 pragma UNROLL 可以去掉以精简代码,这是由于 HLS 工具会自动将需要流水化的循环内部的所有子循环展开,这个优化会在 HLS 工具的 Console 里显示。因此,我们的代码调整如下:

在 HLS 工具中重新综合,发现延迟降到了 29993 个时钟周期 (具体数字可能略有差异),性能进一步提升了 22.95%。HLS 的综合报告里也显示加速器调用也已经流水化了:
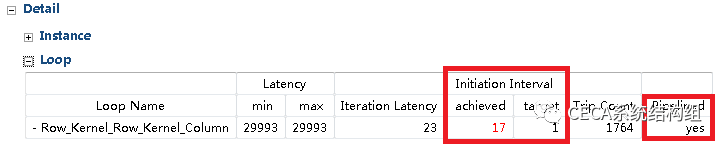
从上面的综合报告我们可以发现一个细节,虽然整个循环已经流水化了,但是 Initiation Interval 却仍然不是理想情况的 1,即:不能做到每个周期都开始一个新的 Iteration 的计算。那么问题出在哪里呢?还有没有进一步优化的空间呢?
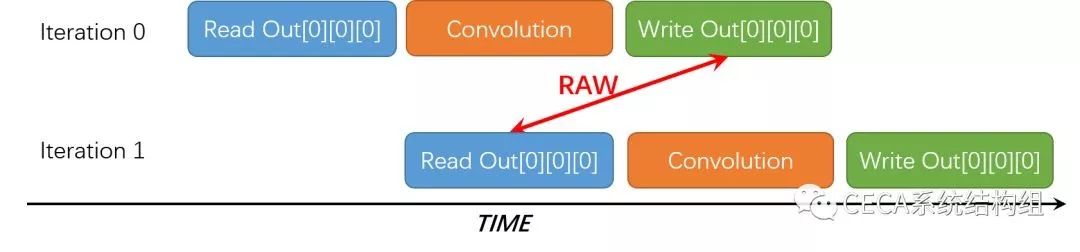
通过分析代码和 HLS 工具的 Warning 我们可以发现,问题出在 Out 这个数组上。在我们的实现中,Out 数组在内层循环的一个 Iteration 中参与了自加运算 (+=),即:先被读,后被写。如下图所示,在执行 Iteration 0 的时候 (r=c=kr=kc=0),Out[0][0][0] 先被读,然后被写;然而在接下来执行计算 Iteration 1(r=c=kr=0, kc=1) 的时候,仍然是 Out[0][0][0] 先被读,然后被写。因此,如果我们使用 pragma PIPELINE 进行性能优化,相邻的这两个 Iteration 都需要操作 Out[0][0][0] 这个位置的数据,从而产生写后读 (RAW) 的数据依赖,即:程序必须等待 Iteration 0 对 Out[0][0][0] 的写操作完成后,才能开始执行 Iteration 1。为了保证程序结果的正确性,HLS 工具不会将这部分循环完全流水化,进而导致性能的下降。
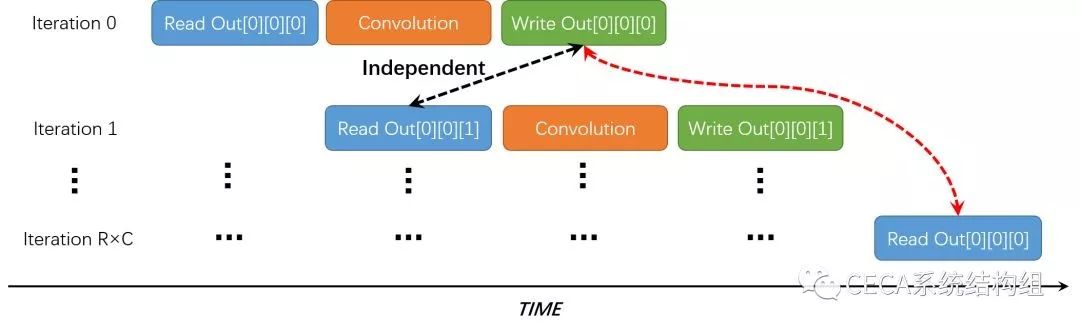
通过观察我们可以发现:Out 数组的在程序中的访问位置,只和 r、c 这两个循环变量相关,而和 kr、kc 无关。我们可以利用这一点解决 RAW 数据依赖的问题。为了能将内层循环的计算完全流水化,我们决定将 Kernel Row 和 Kernel Column 两重循环移到外层。如下图所示,将循环流水化时,相邻 Iteration 所访问的 Out 数组的数据位置是不同的,不存在数据依赖,可以流水执行;而有 RAW 数据依赖的 Iteration 将在很远的时间点发生 (R×C 个 Iteration 之后),此时对于该位置的写操作早已完成,读操作可以正常进行。这样一来,我们实现了一个完全流水化的硬件架构,提升了加速器的整体处理性能。
按照上述优化调整后的代码如下:

在 HLS 工具中重新综合,发现延迟降到了仅仅 1782 个时钟周期 (具体数字可能略有差异),相对于原始无优化版本的加速达到了 141.06 倍!HLS 的综合报告里显示加速器调用也已经完全流水化了:
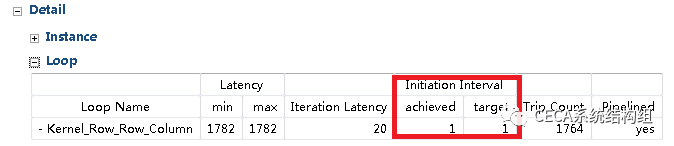
综上,我们就完成了一个高效的卷积运算加速器,而基本上利用 HLS 工具设计 FPGA 硬件加速器的入门也就完成了。总结来说,使用 HLS 设计 FPGA 加速器的一般化设计流程如下:
熟悉并理解目标算法,通过软件运行目标算法,分析性能瓶颈所在;
实现加速目标的软件版本,分析其中可以并行、流水化的部分,并构想可行的硬件架构;
通过代码重构,加 pragma 等方法在 HLS 工具中描述目标架构,此过程需注意保证改写的代码功能性上与原代码严格保持一致;
调整硬件参数配置,最大化利用硬件资源 (计算资源如 DSP、存储资源如 BRAM) 来最大化加速器的性能。
30 天精通学习
在完成了上面的 3 天入门实例后,大家可以进一步学习和实践 FPGA 加速器的设计,这一部分我们推荐大家利用 3 到 4 周的时间对相关知识进行详细、系统的学习。高层次综合的相关知识的学习我们推荐学习 Xilinx 公司推出的《Parallel Programming for FPGAs (中文版)》,该教程的下载地址是 https://github.com/xupsh/pp4fpgas-cn。大家要仔细阅读这本书,并配合 https://github.com/xupsh/pp4fpgas-cn-hls 中的代码实例理解高层次综合的代码风格和 pragma 的使用方法。关于高层次综合的 pragma 请参照 Xilinx 官方的 pragma 详解加深理解和记忆。开发板方面,我们推荐使用 Xilinx Pynq-Z2 进行上板实践。
结语
硬件加速器设计是一个长期的、需要大量经验积累的工作。本文仅为读者提供了一个快速入门上手设计的分享,想要设计高效的硬件加速器的读者还需要多关注前沿领域、多阅读顶级学术论文、多上手设计实践,在发掘潜在加速需求的同时提升自身设计加速器架构的能力。本文侧重入门知识分享,后续会考虑出进阶版实例、论文分享、设计总结等,希望读者能够多多反馈意见。
致谢
感谢北京大学高能效计算与应用中心罗国杰教授和 Xilinx 大中华区教育与创新生态高级经理陆佳华先生对本文的校订和支持。
CECA 系统结构组简介
北京大学高能效计算与应用中心 (Center for Energy-Efficient Computing and Applications,简称 CECA) 成立于 2010 年。该中心是北京大学在「985 工程」中建设的开展国际先进水平的高能效计算与应用研究的科研机构。该中心既是北京大学计算机系统结构学科的重要组成部分,又是一个交叉研究机构。CECA 系统结构组的主要研究方向包括:面向深度学习等应用的加速器系统架构设计,面向边缘计算等新兴应用的高能效系统研究,和基于新型存储器的高能效存储系统结构研究。

本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


