徐宗本院士《机器学习的前提:一个元理论》,SIGIR2020视频报告
徐宗本院士在SIGIR2020的演讲,突破机器学习前提的瓶颈,非常硬核,值得学习

徐宗本
西安交通大学教授、陈嘉庚奖获得者、中国科学院院士
徐宗本教授发表了280余篇关于非线性功能分析,优化,机器学习和大数据研究的学术论文,其中大部分在国际期刊上。他目前的研究兴趣包括用于大数据分析,机器学习和数据科学的数学理论和基本算法。徐教授获得了许多学术奖项,例如,国家自然科学奖(2007年),国家科学技术进步奖(2011年),CSIAM Su Buchin应用数学奖(2008年)和Tan Kah Kee科学奖(信息技术科学,2018年)。应大会委员会的邀请,他在国际数学家大会(ICM 2010)上发表了45分钟的演讲。2011年当选为中国科学院院士。徐宗本院士在7月27日即主会议的首日下午,围绕“关于机器学习的前提:一个元理论”带来主题演讲。
关于机器学习的前提:一个元理论
机器学习(ML)运行和应用的前提是一系列的前提,这些前提既是AI的巨大成功,也是ML进一步发展的瓶颈。这些前提包括: (一)数据集上损失函数的独立性假设(假设i); (二)假设空间上的大容量假设,包括解(假设二); (三) 训练数据高质量的完备性假设(假设三);欧几里得关于分析框架和方法的假设(假设四)。
在这次演讲中,我们报告了我的团队在如何突破ML的这些预设并推动ML的发展方面所做的努力和取得的进展。对于假设I,我们引入噪声建模原理,根据数据样本的分布自适应地设计ML的损失函数,从而为实现ML的健壮性提供了一种通用的方法。对于假设二,我们提出了模型驱动的深度学习方法来定义深度神经网络(DNN)的最小假设空间,这不仅产生了非常高效的深度学习,而且为DNN的设计、解释和与传统的基于优化的方法联系提供了一种新的方法。对于假设三,我们开发了公理课程学习框架,从一个不完整的数据集,由易到难,一步一步地学习模式,从而为处理非常复杂的不完整数据集提供了可行的方法。最后,对于假设IV,我们引入一般的巴拿赫空间几何,特别是徐罗奇定理,作为对ML问题进行非欧几里得分析的可能有用的工具。在每个案例中,我们都提出了其思想、原理、应用实例和文献。

视频:


假设1:数据集上损失函数的独立性假设

假设2:假设空间上的大容量假设,包括解
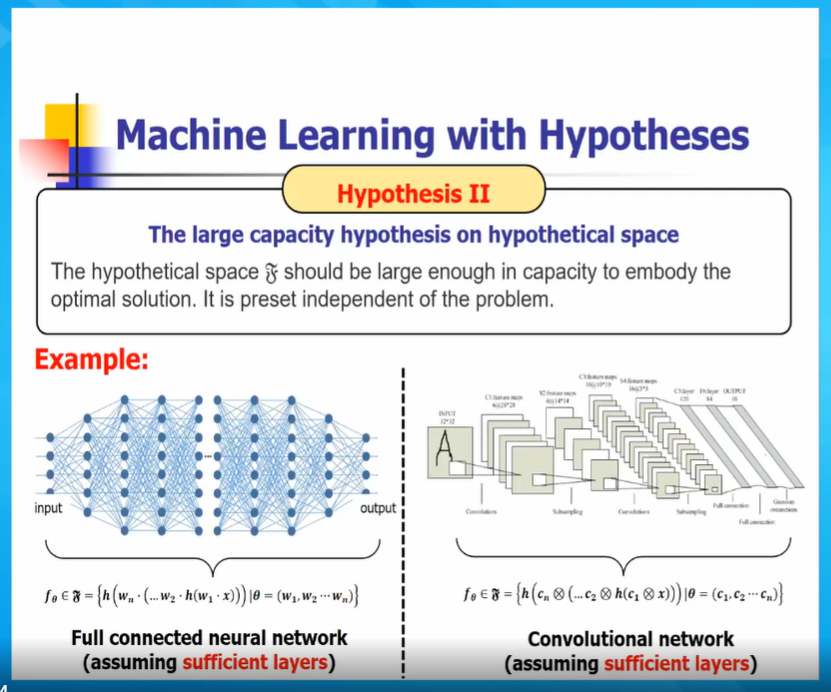
假设3:训练数据高质量的完备性假设

假设4:正则化假设


结论:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MLMT” 可以获取《徐宗本院士《机器学习的前提:一个元理论》》专知下载链接索引





