如何极大效率地提高你训练模型的速度?

本文为 AI 研习社编译的技术博客,原标题 :
How to Train Your Model (Dramatically Faster)
翻译 | 老赵 校对 | Peter_Dong 整理 | 菠萝妹
原文链接:
https://medium.com/@williampnowak/how-to-train-your-model-dramatically-faster-9ad063f0f718
注:本文的相关链接请点击文末【阅读原文】进行访问
我现在在Unbox Research工作,由 Tyler Neylon创办的新的机器学习研究单位,岗位是机器学习工程师。我刚刚为一名客户完成了一个服装图片分类的iOS 应用程序开发的项目——在类似这样的项目里,迁移学习是一种非常有用的工具
为了有效地部分重训练神经网络,迁移学习是一种很好的方法。为了达到这个目的,我们重新使用了之前已经构建起的模型架构以及大部分已经学习到的权重,使用标准的训练方法去学习剩下的还未重新使用的参数。
迁移学习 对比 非迁移学习
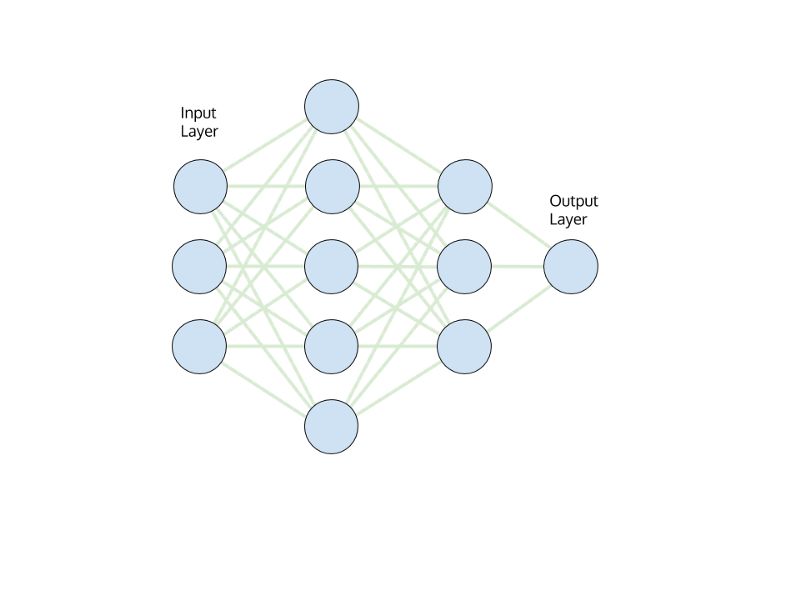
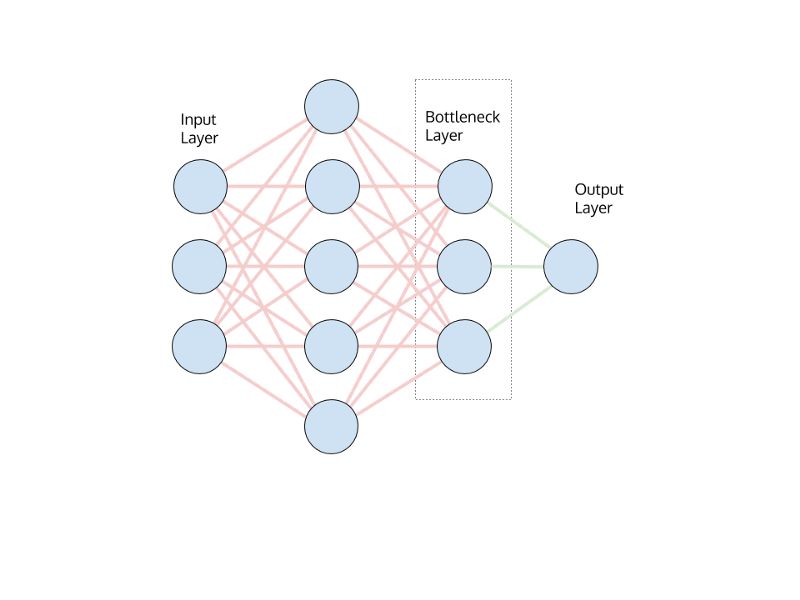
图1:标准神经网络模型的架构,绿色代表着所有权证和偏置的训练。
完全训练的神经网络在初始层中获取输入值,然后顺序地向前馈送该信息(同时转换它),直到关键地,一些倒数第二层构建了输入的高级表示,可以更容易地 转化为最终输出。 模型的全面训练涉及每个连接中使用的权值和偏差项的优化,标记为绿色。
倒数第二层被称为瓶颈层。 瓶颈层将回归模型中的值或分类模型中的softmax概率推送到我们的最终网络层。
图2:转移学习神经网络模型的模型架构,红色表示固定的权重和偏差,绿色表示仅训练最终层的权重和偏差。
在转学习中,我们从整个网络的预训练权重开始。 然后我们将权重固定到最后一层,并在我们训练新数据时让该层中的权重发生变化。 如图所示,我们保持红色连接固定,现在只重新训练最后一层绿色连接。
转移效率
转移学习的两个主要好处:
1. 对新数据的培训比从头开始更快。
2. 如果我们从头开始,我们通常可以用比我们需要的更少的训练数据来解决问题。
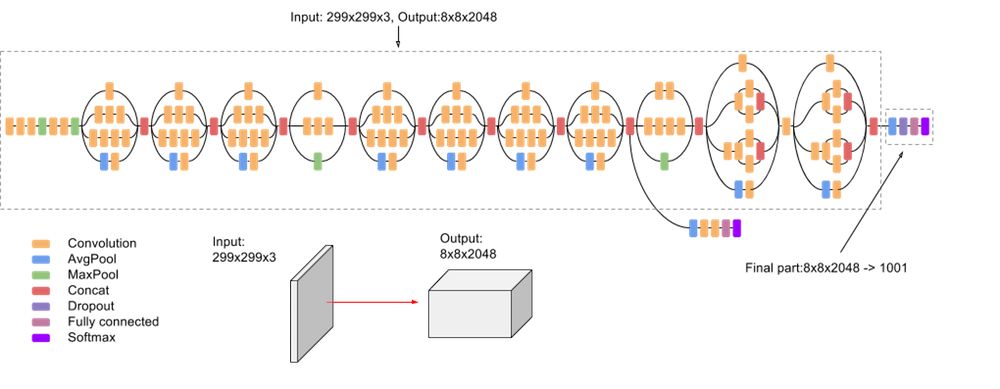
图3:InceptionV3模型的高级概述,我们用它来演示迁移学习示例。 图像的奇特流程图性质与Inception是一个卷积神经网络有关。
在这里,我们确切地考虑为什么迁移学习如此有效
通过仅重新训练我们的最后一层,我们正在执行计算成本极低的优化(学习数百或数千个参数,而不是数百万)。
这与像Inception v3这样的开源模型形成对比,后者包含2500万个参数,并使用一流的硬件进行训练。 因此,这些网络具有良好拟合的参数和瓶颈层,具有高度优化的输入数据表示。 虽然你可能会发现很难用自己有限的计算和数据资源从头开始训练高性能模型,但你可以使用迁移学习来利用其他人的工作并强制增加你的性能。
示例代码
让我们看看一些Python代码,以获得更多的思考(但不要太远 - 不想迷失在那里)。
首先,我们需要从预训练模型开始。 Keras有一堆预训练模型; 我们将使用InceptionV3模型。
# Keras and TensorFlow must be (pip) installed.
from keras.applications import InceptionV3
from keras.models import Model
InceptionV3已经在ImageNet数据上进行了训练,该数据包含1000个不同的对象,其中很多我发现它们非常古怪。 例如,924类是“鳄梨”。

图4:mmm ......
实际上,预训练的InceptionV3就是这样认可的。preds = InceptionV3().predict(guacamole_img) 返回一个1000维数组guacamole_img(其中是一个224x224x3维度的np数组)。
preds.max() 返回0.99999preds.argmax(-1)而返回索引924 - Inception模型确实这个鳄梨酱就是那个! guacamole_img(例如,我们预测Imagenet图像#924的置信度为99.999%。这是一个可重现代码的链接。
现在我们知道InceptionV3至少可以确认我正在吃什么,让我们看看我们是否可以使用基础数据表示重新训练并学习新的分类方案。
如上所述,我们希望冻结模型的前n-1层,然后重新训练最后一层。
下面,我们加载预训练模型; 然后,我们使用TensorFlow方法 .get_layer() 从原始模型中获取输入和倒数第二个(瓶颈)图层名称,并使用这两个层作为输入和输出构建新模型。
original_model = InceptionV3()
bottleneck_input = original_model.get_layer(index=0).input
bottleneck_output = original_model.get_layer(index=-2).output
bottleneck_model = Model(inputs=bottleneck_input, outputs=bottleneck_output)
在这里,我们从Inception模型的第一层(index = 0)获取输入。 要是我们 print(model.get_layer(index=0).input) ,我们看到Tensor("input_1:0", shape=(?,?,?,3), dtype=float32) 这表明我们的模型期望一些不确定数量的图像作为输入,具有未指定的高度和宽度,具有3个RBG通道。 这也是我们想要作为瓶颈层输入的东西。
我们将瓶颈的输出Tensor("avg_pool/Mean:0",shape=(?, 2048), dtype=float32) 看作是我们通过引用倒数第二个模型层访问的瓶颈。 在这种情况下,初始模型已经学习了任何图像输入的2048维表示,其中我们可以将这些2048维度视为表示对分类必不可少的图像的关键组件。
最后,我们使用原始图像输入和瓶颈层作为输出实例化一个新模型:Model(inputs=bottleneck_input, outputs=bottleneck_output).
接下来,我们需要将预训练模型中的每一层设置为无法训练 - 基本上我们正在冻结这些层的权重和偏差,并保留已经通过Inception原始的,费力的训练学到的信息。
for layer in bottleneck_model.layers:
layer.trainable = False
现在,我们制作一个Sequential() 新模型,从我们之前的构建块开始,然后进行一些小的添加。
new_model = Sequential()
new_model.add(bottleneck_model)
new_model.add(Dense(2, activation=‘softmax’, input_dim=2048))
上面的代码用于构建一个复合模型,该模型将我们的Inception架构与具有2个节点的最终层相结合。 我们使用2因为我们将重新训练一个新的模型来学习区分猫和狗 - 所以我们只有2个图像类。 将此替换为你希望分类的许多类。
如前所述,瓶颈输出的大小为2048,所以这是我们的input_dim Dense密集层, 最后,我们插入softmax激活,以确保我们的图像类输出可以解释为概率。
我在本文的最后部分包含了一个非常高的网络布局图像 - 请务必查看它。
要完成,我们只需要一些标准的TensorFlow步骤:
# For a binary classification problem
new_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
one_hot_labels = keras.utils.to_categorical(labels, num_classes=2)
new_model.fit(processed_imgs_array,
one_hot_labels,
epochs=2,
batch_size=32)
这里processed_ims_array是一个数组(number_images_in_training_set,224,224,3)和label一个基础真实图像类的Python列表。 这些是与训练数据中的图像类对应的标量。num_classes=2 所以标签label只是number_of_images_in_training_set 一个包含0和1的长度列表。
最后,当我们在第一个猫训练图像上运行此模型时(使用Tensorflow非常方便的内置双线性重新缩放功能):

图6:一只可爱的猫......对你有好处!
该模型预测猫有94%的置信度。 这非常好,考虑到我只使用了20个训练图像,并且只训练了2个周期。
总结
通过利用预先构建的模型体系结构和预先学习的权重,迁移学习允许你使用学习的给定数据结构的高级表示,并将其应用于您自己的新训练数据。
回顾一下,你需要3种成分来使用迁移学习:
1. 一个预训练的模型
2. 类似的训练数据 - 你需要输入与预训练模型“足够相似”的输入。 类似的意味着输入必须具有相同的格式(例如输入张量的形状,数据类型......)和类似的解释。 例如,如果你使用预训练的模型进行图像分类,则图像将用作输入! 然而,一些聪明的人已经格式化音频以通过预训练的图像分类器运行,并带来一些很酷的结果。 与往常一样,财富有利于创意。
3. 训练标签,在此处查看完整的工作示例,以演示使用本地文件的迁移学习。
如果你有任何问题/发现此值,请在下面留下评论。 如果你有任何想要讨论的机器学习项目,请随时与我联系!will@unboxresearch.com。

对于纽约市的读者 - 我们将在2019年1月举办关于TensorFlow的整个研讨会 - 在这里获得门票。
附录
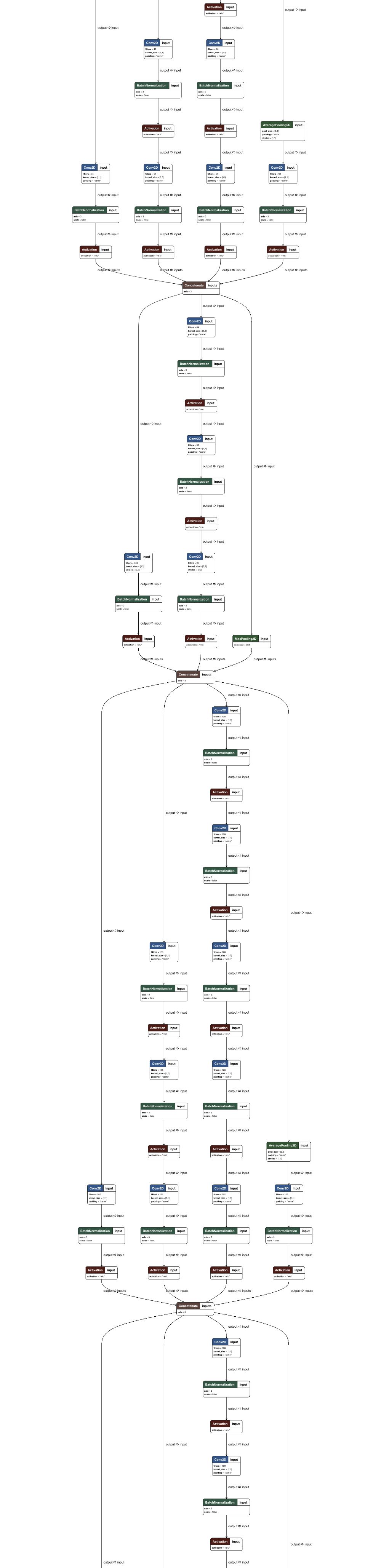
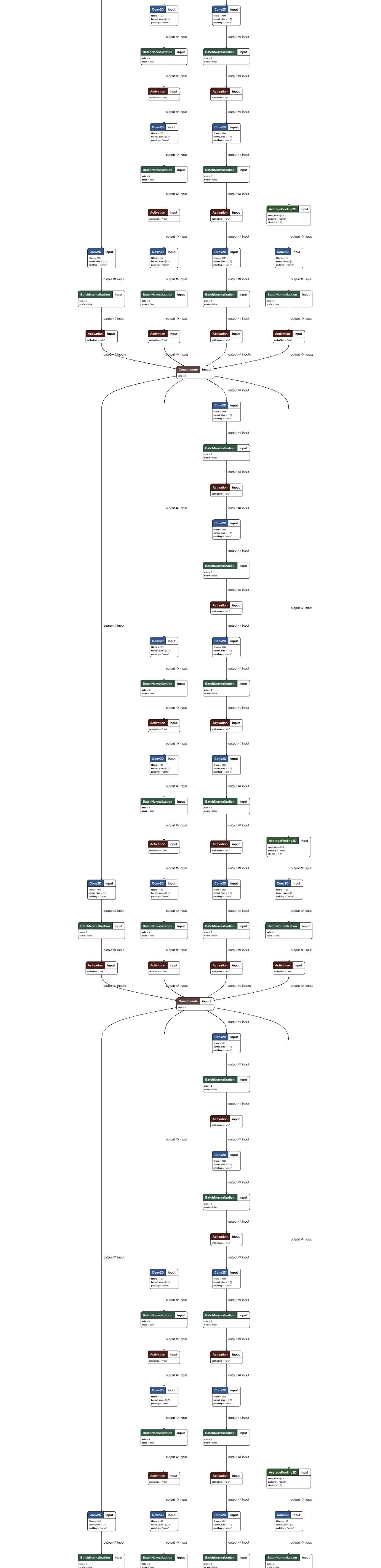
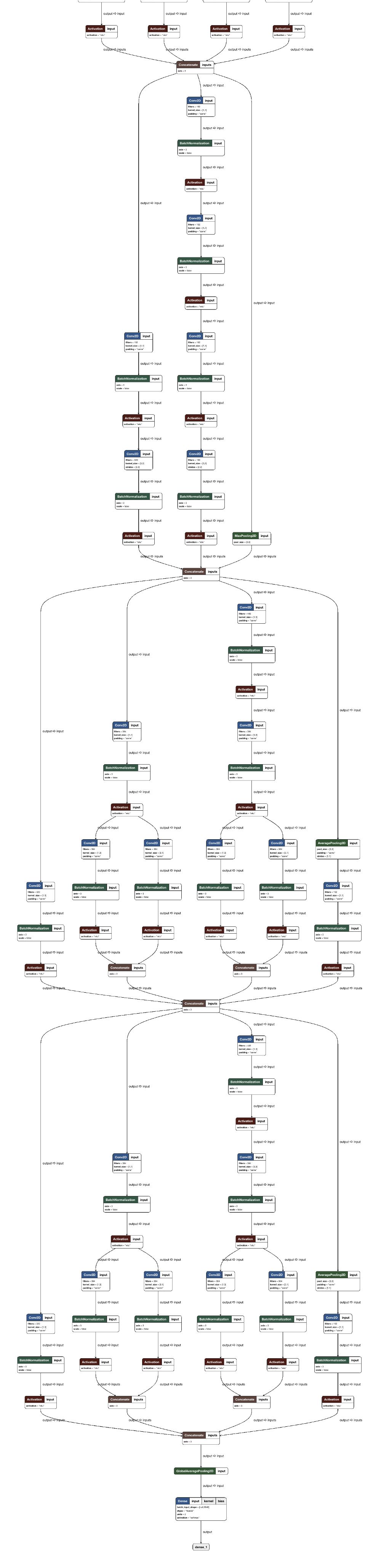
感谢Tyler Neylon。
想要继续查看该篇文章相关链接和参考文献?
戳链接或点击底部【阅读原文】:
http://ai.yanxishe.com/page/TextTranslation/1126
AI研习社每日更新精彩内容,观看更多精彩内容:
使用 SKIL 和 YOLO 构建产品级目标检测系统
AI课程/书籍/视频讲座/论文精选大列表
Excel 还能这样玩?轻松搞懂一维 & 三维卷积神经网络
数据科学家应当了解的五个统计基本概念:统计特征、概率分布、降维、过采样/欠采样、贝叶斯统计
等你来译:





